未春凤 赵淑贤


摘要:数据流处理的关键是应用高效的单趟扫描算法,创建数据流的概要结构。现有的概要结构存在着重构误差较大的缺点。作者针对这个问题,结合数据流分层遗忘概要结构,采用simHash算法提取数据流中的概要信息,形成一种新的数据流分层遗忘概要结构(simHash-Based Hierarchical Amnesic Synopsis,SH-HAS)。本文将SH-HAS结构用在CUP99和Covertype数据集上,实验验证了该结构的可靠性和稳定性。
关键词:数据流;概要结构;simHash;分层遗忘
中图分类号:TP311 ? ? ? ?文献标识码:A
文章编号:1009-3044(2019)15-0006-02
随着计算机网络和各类电子设备的应用,越来越多的数据以流的形式出现,这种新的数据形式被称为数据流[1]。数据流具有实时性、有序性、高速性、演化性、无限性等特性[2]。这使得传统的数据挖掘方法不能直接应用到数据流上。
因为数据流具有无限到达的特性,导致现有的计算机系统不能存储全部的数据流。针对这一问题,学者提出了建立数据流的概要结构,以便保存数据流的概要信息和根据该结构提供数据流的近似处理结果。数据流概要结构是存储数据流概要信息的一种结构,旨在使用较小的数据规模代表全体数据,称为概要结构(synopsis structure)[3]。现有的数据流概要结构主要通过直方图、抽样、小波、随机投影和散列方法获取数据流的概要信息。
分层遗忘概要(Hierarchical Amnesic Synopsis,简称HAS)[4],是陈华辉提出的一种基于数据流遗忘特性的概要结构构造框架。其他学者在这方面也进行了许多的研究,例如文献[5-7]。这些方法能有效地获取数据流概要信息,但存在着重构误差较大的缺點。
simHash算法由Google的工程师于2007年提出,在文档去重和文本相似度检索等领域。学者将SimHash算法用于数据的相似性检索[8-10],并取得了较好的效果。
SimHash算法既可以高效地压缩原始数据,又是一种降维方法。本文利用simHash算法在数据压缩方面的高效性,结合数据流的HAS结构,提出一种基于simHash的数据流分层遗忘概要结构(simHash-Based Hierarchical Amnesic Synopsis,简称SH-HAS)。该算法的主要思想为:采用simHash算法提取数据流上新到的数据子序列的概要信息,创建对应的数据节点并添加到SH-HAS结构中;当SH-HAS结构中某层的数据节点个数达到上限,则将当前层节点相加成K个节点并插入该结构的上一层;随着数据流的到来,动态调整该结构。本文将该结构用在CUP99和Covertype数据集上,实验验证了该结构的可靠性和稳定性。
1基于simHash的数据流分层概要结构
simHash算法[9]属于前述方法中的散列方法。它既是一种数据相似度计算方法,又是一种数据维度削减方法,用以解决数据流维度高和数据无限的问题。
1.1 分层概要结构
数据流除了具有前述的特点外,其数据的影响是随时间衰减的,表现为近期的数据价值更大。在分层概要结构中,数据所处的层数越低,说明数据到达的时间较晚;层数越高说明数据到达的时间较早。
1.2 数据定义
在SH-HAS结构中数据节点[P(D)]=[ts,n,X,Γ],其中[ts]为该数据节点的时间戳,记录D中最后一个数据的到达时刻;n为D中数据个数[D];[X]为D中数据的均值;[Γ]表示采用simHash算法计算出的数据概要信息。
1.2.3 SH-HAS结构的动态维护
随着数据的到达,为了使SH-HAS结构中保存的信息能无限接近真实的数据流,需要对此结构进行动态更新维护。数据流上的SH-HAS结构的动态维护算法如图1所示。算法的空间和时间复杂性在文献[4]中已经被证明,在此不再赘述。
2 实验及分析
2.1 数据集及评价标准
本文使用UCI(University of California Irvine)[11]的机器学习库中的KDDCUP99和Covertype数据集作为实验数据集,并使用相对重构误差来评价实验结果。
设有数据序列[D=(X1,X2,...,Xn)],设[D']为重构得到的重构数据集,其相对重构误差定义为式(1):
其中符号[∥x∥]表示向量x的2范数。
2.2 实验及结果分析
2.2.1实验设置
实验中修改MOA系统lancher文件模拟数据流的到达,将数据流上每2000条数据划分为一个子序列。本文实验比较了Sampling、Histogram和SH-HAS方法在数据流上的相对重构误差。
2.2.2实验结果及分析
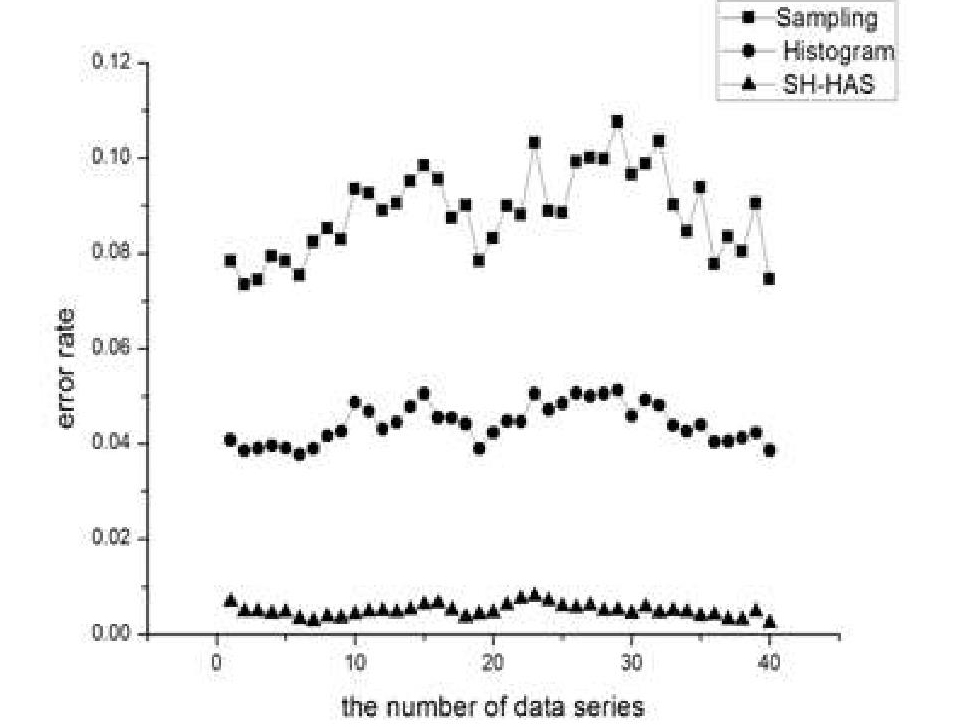
因为篇幅有限,在此仅列出数据集Covertype上的部分实验结果。图2分别截取了一部分实验数据,记载了将Sampling、Histogram、SH-HAS方法应用在Covertype数据集的相对重构误差。从图2中可以看出, SH-HAS方法较Sampling、Histogram方法相对重构误差明显降低。
3结语
本文针对现有数据流概要结构存在着重构误差较大的缺点,采用simHash算法提取数据流中的概要信息,形成一种新的数据流分层遗忘概要结构(SH-HAS)。该结构采用simHash算法提取数据流上新到的数据子序列的概要信息,创建对应的数据节点并添加到SH-HAS结构中;当SH-HAS结构中某层的数据节点个数达到上限,则将当前层节点相加成K个节点并插入该结构的上一层;随着数据流的到来,动态调整该结构。实验结果表明SH-HAS结构可以大大减小相对重构误差。下一步可开展基于SH-HAS结构的数据流相似性判断和分类等处理方法的研究。
参考文献:
[1] 黄树成,曲亚辉.数据流分类技术研究综述[J].计算机应用研究,2009,10:3604-3609.
[2] 李南.概念漂移数据流分类算法及应用[D].福建师范大学,2013.
[3] 龙门,夏靖波,张子阳.基于概要数据结构的网络异常检测方法[J].计算机应用与软件,2011,04:186-188.
[4] 陈华辉.基于遗忘特性的数据流概要结构及其应用研究[D].复旦大学,2008.
[5] Pang C,Zhang Q,Zhou X,et al.Computing unrestricted synopses under maximum error bound[J].Algorithmica,2013,65(1):1-42.
[6] Pham D S,Venkatesh S,Lazarescu M,et al.Anomaly detection in large-scale data stream networks[J]. Data Mining and Knowledge Discovery,2014,28(1):145-189.
[8] Graham Cormode;S.Muthukrishnan.An Improved Data Stream Summary:The Count-Min Sketch and Its Applications[A].2004
[10] Xu X,Gao C,Pei J,et al.Continuous similarity search for evolving queries[J].Knowledge and Information Systems,2014:1-30.
[11] http://www.ics.uci
【通联编辑:唐一东】
- “双一流”建设背景下民办高校学科建设定位及实施路径研究
- 趣味性教学模式在小学美术教学中的应用策略
- 职业教育教学质量评价反馈平台需求和功能研究
- 应届毕业生就业价值取向的研究分析
- 中职会计专业学生职业道德的培养
- 有关建筑工程中的防渗漏技术探析
- 装配式建筑区域发展政策评析
- 土木工程建筑施工技术及管理创新研究
- 高速公路沥青路面病害养护防治分析
- 建筑施工企业财务共享中心的建立与优化分析
- 论公路桥梁施工技术的质量控制
- 道路桥梁施工中的裂缝成因及预防
- 冲击碾压技术在公路路基施工中的运用
- 市政公路路基土方工程精细化施工管理要点
- 装配式建筑发展背景分析
- 建筑施工管理及绿色建筑施工管理分析
- 对建筑工程中的深基坑支护施工技术的思考
- 探讨城市轨道交通规划设计前期研究工作
- 公路工程建设风险管理现状及控制措施分析
- 水利工程中混凝土检测试验及生产质量控制
- 建筑工程施工技术管理探讨
- 关于建筑设计中绿色建筑设计要点研究
- 公路工程养护存在问题及对策浅析
- 传统材料在当代建筑中的文化表达
- 探讨电力建设工程管理与质量进度管理
- anti-soviets
- anti-spam
- antispam
- anti-speculation
- antispeculations
- antispeculative
- antispeculatively
- antispeculativeness
- antispeculativenesses
- antispending
- antispiritual
- antispiritualism
- antispiritualisms
- antispiritualist
- antispiritualistic
- antispiritualists
- antispiritually
- antisplitting
- antispreading
- anti-stalinist
- anti-stalinists
- antistate
- antistatist
- antisterility
- antistick
- 前往亲友新居祝贺
- 前往人家吃饭
- 前往从学
- 前往会见
- 前往受教
- 前往叩问
- 前往吊丧
- 前往吊谒
- 前往对质
- 前往应举
- 前往应试
- 前往征讨
- 前往慰问
- 前往报告
- 前往拜望
- 前往拜见
- 前往拜访
- 前往救助
- 前往救援
- 前往朝廷官署
- 前往栖息
- 前往看望
- 前往考试
- 前往聚会
- 前往聚集