张亮 赵妍
摘要:研究了矩阵相乘的并行算法,基于MPI消息传递库采用C语言实现了该算法,讲解了矩阵并行乘法中的矩阵划分方法和消息传递方法。
关键词:并行计算;MPI;矩阵相乘;消息传递
中图分类号:TP31? ? ? 文献标识码:A
文章编号:1009-3044(2019)23-0281-02
开放科学(资源服务)标识码(OSID):
MPI-based Parallel Computation of the Multiple of matrixs
ZHANG Liang, ZHAO Yan
(Ningxia Financial Vocational and Technical College, Ningxia 750021, China)
Abstract: Parallel Computation of the multiple of matrixs was studied, based on MPI and C Language the algorithm was realized. Partition of matrix and message passing in the algorithm was addressed.
Key words: Parallel Computation; MPI; Multiple of matrixs; Message Passing
1 引言
并行計算又叫高性能计算,在许多领域的都发挥着积极的巨大的作用,如物理、化学、材料等科学中分子尺度的模拟,天文学和地球科学中银河系的演化,,天气预报,地球数值模拟,全球长期气候变化的模型等[1]。这些研究都对计算机的运算速度提出了很高的要求,也只有高性能的并行计算才能满足这些要求。在并行计算中,集群系统以廉价高效等优点颇受人们青睐,是当今的主流。并行处理的软件支持环境包括基于OpenMP和MPI(Message Passing Interface)的各种环境。OpenMP主要用于共享式计算环境,而MPI则主要用于分布式计算环境[1]。本文实现了基于MPI的矩阵乘法运算。
2 算法描述
设有L×M矩阵A和M×N矩阵B相乘,得到结果为L×N的矩阵C。记矩阵A、B、C的第i行第j列的元素为Aij(i=0……L,j=0……M),Bij(i=0……M,j=0……N),Cij(i=0……L,j=0……N)。则:
Cij=
可见Cij只与A和B的第i行相关,而与其他行无关,所以具有并行计算的可行性。
假设有n个进程并行计算,则把矩阵A按行分成n个M/n行的小矩阵,每个小矩阵与B进行矩阵乘法,得到n个M/n行,N列的矩阵,将这些矩阵合并到一起就得到最终的结果。
3 算法实现
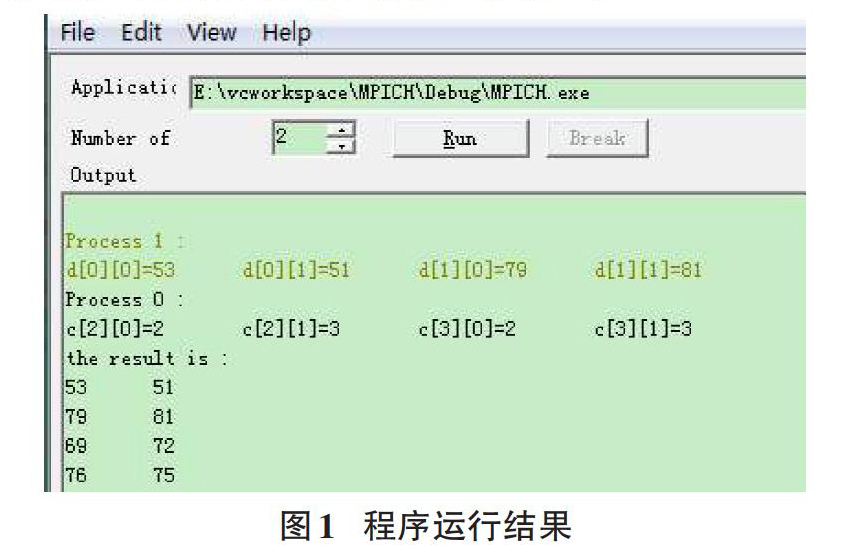
根据上面的算法,在VC6中用MPI的C语言实现为如下的程序:
#include "mpi.h"
#include
#include
#define l 4/*第一个矩阵的行*/
#define m 3/*第一个矩阵的列,第二个矩阵的行*/
#define n 2/*第二个矩阵的列*/
main(int argc,char *argv[])
{
int a[l][m]={{2,3,5},{4,5,7},{6,3,6},{1,6,7}};
int b[m][n]={{2,4},{3,6},{8,5}};
int c[l][n]={0};/*保存最终结果*/
int d[l][n]={0};/*各个分进程保存中间结果*/
int numproces,id,i,j,k,p,q,s,t,x,y;
MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numproces);
MPI_Comm_rank(MPI_COMM_WORLD,&id);
printf("Process %d :\n",id);
if(id>0)
{/*numproces个进程,l行,每个进程l/numproces行,
从(id-1)*l/numproces行到id*l/numproces行*/
for(x=0,i=(id-1)*l/numproces;i { for(y=0,j=0;j { for(k=0;k { d[x][y]=d[x][y]+a[i][k]*b[k][j];/*d[][]保存该进程计算结果*/ } printf("d[%d][%d]=%d\t",x,y,d[x][y]);
- 土司体育文化理论体系构建研究
- 传统武术文化的道家渊源与精神
- 中国武术“现代化”:起源、批判与反思
- 体育非物质文化遗产法律保护路径的选择研究
- 北京冬奥前期长春市冰雪休闲旅游发展对策分析
- 中国城市马拉松赛电视直播文本分析
- 1949—1966年间我国青少年体质健康政策文本量化分析
- 政府购买公共体育服务边界的研究
- 市场转型背景下体育赛事公共服务体系建设研究
- 北京国际体育中心城市与世界城市融合建设研究
- 海南省体育旅游空间优化及其发展模式
- “分享经济”模式下体育产业发展探究
- 奥林匹克运动改革发展问题研究
- 2015年全国大学生田径锦标赛甲B组男子跳高技术生物力学研究
- AKT/FOXO在一次低氧致骨骼肌蛋白质代谢变化中的作用
- 长期递增负荷运动对大鼠股骨OPG和RANKL蛋白表达的影响
- 非全日制体育硕士学位论文质量影响因素分析
- 学校体育教育本真解读及人文价值回归
- 《美国学校健康促进计划》的特征与启示
- 北京世锦赛女子链球运动员冠亚军投掷技术运动学分析
- 我国男子百米运动员苏炳添起跑加速技术研究
- 技术还是技艺:应该如何看待武术
- 述古、嬗变与赓续:基于学统视角看民族传统体育的传统再生
- 传统体育应该回归其迷失的生命哲学
- 理论与实践的范式:太极拳与生活互动研究
- cosine
- cosines
- cosiness
- co-sleep
- cosmeceutical
- cosmetic
- cosmetical
- cosmetically
- cosmetics
- cosmetic²
- cosmetic¹
- cosmic
- cosmicalities
- cosmicality
- cosmically
- cosmic-string
- cosmic-strings
- cosmo
- cosmopolitan
- cosmopolitanisms
- cosmopolitanly
- cosmopolitans
- cosmos
- cosmoses
- co-sovereign
- r2022090420000031
- r2022090420000032
- r2022090420000034
- r2022090420000035
- r2022090420000036
- r2022090420000038
- r2022090420000039
- r2022090420000040
- r2022090420000041
- r2022090420000043
- r2022090420000044
- r2022090420000045
- r2022090420000046
- r2022090420000047
- r2022090420000048
- r2022090420000049
- r2022090420000050
- r2022090420000051
- r2022090420000053
- r2022090420000054
- r2022090420000055
- r2022090420000056
- r2022090420000057
- r2022090420000058
- r2022090420000059