
摘要:为了验证文本对是否由同一作者书写,设计并实现了一个作者身份验证系统。该系统选择了目前最先进的作者身份验证方法之二,即基于深度神经网络语言模型的方法和基于冒名者的方法。系统可根据不同的文本长度,自适应地选择合适的算法,具有识别准确率高、操作简便和运行速度快等优势。最终,在一个公开的博客作者身份语料库上进行了实验,获得了83%的识别正确率。实验结果表明,该系统可以在一定程度上解决两段文本的作者身份验证问题。
关键词:作者身份验证;冒名者;语言模型;神经网络
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2020)03-0031-03
1 背景
随着我国网络技术的不断发展与社交媒体等新型媒体形式的不断涌现,网络中出现了大量的匿名文本和作者用虚假身份书写的文本,包括由“水军”发表的虚假评论[1]、电信诈骗人员书写的诈骗邮件和诈骗短信[2]、由“枪手”代写的文章或冒名的文章[3]等。因此,对作者身份的有效验证具有巨大的实际应用价值,成为当前自然语言处理的热点研究方向。
作者身份验证[4-5]主要研究:给定一个文本对,判断文本X和文本Y是否由同一作者书写。本文设计的作者身份验证系统主要采用冒名者和深度神经网络语言模型两种算法,根据X和Y的文本长度,自适应地选择算法验证文本对,具有识别准确率高、操作简便和运行速度快等优势,可以满足目前作者身份验证方面的基本需求。
2 系统设计
2.1 系统组成
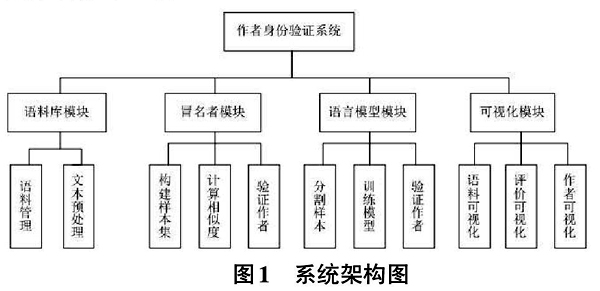
本文所设计的作者身份验证系统由语料库模块、冒名者模
2.1.1 语料库模块
主要完成语料的增、删、改、查等语料库管理功能,以及文本清洗、分词和分句等文本预处理功能。
2.1.2 冒名者模块
主要实现基于冒名者算法的作者身份验证方法,包括构建冒名者样本集、多种文本相似度算法的实现和验证作者等功能。
2.1.3 语言模型模块
主要实现基于深度神经网络语言模型的作者身份验证方法,包括分割文本为样本集、构建深度神经网络语言模型、语言模型训练和识别等功能。
2.1.4 可视化模块
主要完成语料可视化分析、算法评价指标可视化和作者信息可视化等功能。
2.2 系统流程
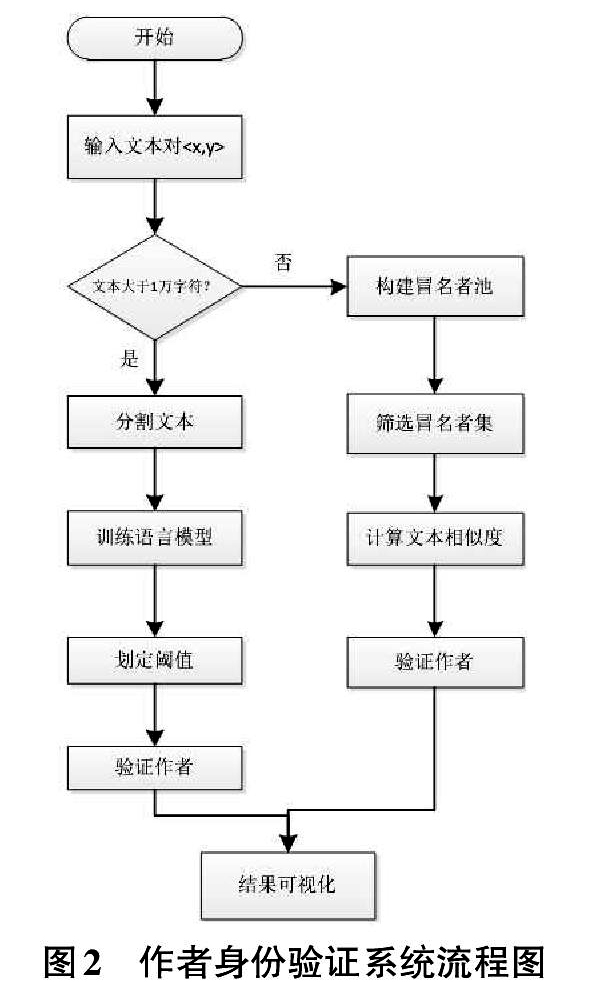
本文系统的运行流程,如图2所示。
步骤1:输入文本对。
步骤2:判断文本对中是否有文本的长度大于10,000字符。如果否,跳转步骤6。
步骤3:分割长度大于10,000字符的文本为训练样本集。
步骤4:训练深度神经网络语言模型,并计算所有训练样本在深度神经网络语言模型中的概率,并根据概率划定阈值。
步骤5:计算待验证文本在深度神经网络语言模型中的概率,如果大于阈值则认定文本对由同一作者书写,否则为不同作者书写。
步骤6:构建冒名者池,并从冒名者池中筛选出冒名者样本集。
步骤7:计算文本对和文本X与冒名者样本集中样本的文本相似度,如果文本对取得较大的文本相似度,则认定文本对由同一作者书写,否则为不同作者书写。
步骤8:可视化显示验证结果。
3 系统实现
本文的作者身份验证系统将根据文本对中X和Y的文本长度,选择不同的作者身份验证方法。当文本X或Y的长度大于10,000字符时,可将文本X或Y分割为多个样本,此时选择评价指标较高的基于深度神经网络语言模型的方法;否则,由于文本较短无法分割出足够的训练样本,选择评价指标略低的基于冒名者的方法。
3.1 冒名者算法
冒名者算法[6],是由Koppel等人提出的作者身份验证方法,是目前为止最成功的短文本作者身份验证方法之一,在多个作者身份验证的公开数据集上取得了较高的评价指标,在作者身份验证的国际评测PAN-2013和PAN-2014中,優胜者就均采用了冒名者算法的变种。冒名者算法的基本思想是:通过引入一些其他作者书写的外部语料,将作者身份验证这种单分类问题转换为二分类问题处理,通过判断文本X更接近文本Y或冒名者,来决定文本对是否由同一作者书写。
冒名者算法的难点在于如何选择合理的冒名者文本构建冒名者样本集。最简单的做法是在一个由多位冒名者构成的冒名者池中,随机选择冒名者。本文采用由Potha等[7]人改进的算法构建冒名者文本集,该算法在冒名者池中选择具有最高相似度的K个文本构建冒名者样本集,算法具体步骤如下:
步骤1:构建冒名者池。
步骤3:选取冒名者池中相似度最大的K个冒名文本,构建冒名者文本集。
3.2 基于深度神经网络语言模型的方法
基于深度神经网络语言模型的方法[8],是由郭旭等人提出的作者身份验证方法,适用于文本对的文本长度不平衡的情况,即文本X的长度较长(10,000字符以上),文本Y的长度较短(100字符左右)。该方法的基本思想是:使用同一作者的语料训练的语言模型,将分配给该作者书写的文本更高的概率。本文选择加入注意力机制的门控循环单元构建深度神经网络语言模型。具体步骤如下:
步骤1:分割长度大于10,000字符的样本为若干个文本块,构建训练语料。
步骤2:使用训练语料训练深度神经网络语言模型。
步骤3:计算训练语料在神经网络语言模型中的概率,划定阈值0。
步骤4:计算短文本在神经网络语言模型中的概率。若大于阈值0,判断为正例;否则,为负例。
4 实验结果
本文选择的实验语料来自一个公开的博客作者身份语料库,该语料库包含19,320位作者共计681,288篇来自blogger.com的博客,平均每位作者有35篇博客和7,252字的博文。实验语料构建过程如下:
步骤1:从博客作者身份语料库中,筛选100位具有最多博客字数的作者,并将每位作者书写的所些博客首尾相连,形成一个博客文本。
步骤2:在博客文本的开始部分随机取10,000到15,000字符和3,000到5,000千字符,在结束部分随机取10,000到15,000字符和3,000到5,000千字符,共4个文本块,首尾文本块各2个。
步骤3:每位作者的首尾文本块两两组合,构成4个正例文本对,共400个正例文本对。
步骤4:随机在不同作者的文本块中组合,构成400个负例文本对。
步骤5:选取其中10个长文本对和90个短文本对作为测试样本集,其中正负例各占50%,其余文本对为训练样本集。
本文系统在对测试样本进行验证时,获得了83%的识别正确率。
5 结束语
本文设计并实现了一个作者身份验证系统,该系统采用Python语言编写,借助tensorflow、keras和HanLP等开源工具包,完成了语料库模块、冒名者模块、语言模型模块和可视化模块共四个功能模块。实验结果表明,该系统可以有效地解决作者身份验证的问题,在一定程度上满足了当前对文本作者验证的需要。但本文仅验证了系统在英文博客上的效果,对于在中文和其他体裁上的效果仍需要进一步实验。
参考文献:
[1]张艳梅,黄莹莹,甘世杰,等.基于贝叶斯模型的微博网络水军识别算法研究[J].通信学报,2017,38(1):44-53.
[2] Ren Y F,Ji D H.Neural networks for deceptive opinion Spamdetection: an empirical study[J]. Information Sciences. 2017.385/386: 213-224.
[3]关珠珠,李雅楠,郭锦秋,医学期刊编辑初审过程中对“枪手”论文的识别[J].编辑学报,2018, 30(1):61-63.
[4] Halvani 0,Winter C.Graner L On the usefulness of compres-sion models for authorship verification[C]//Proceedings of the12th International Conference on Availability. Reliability andSecurity - ARES '17, August 29-September l,2017. ReggioCalabria, Italy. New York. USA: ACM Press, 2017.
[5] Rocha A,Scheirer W J,Forstall C W. et al.Authorship attri-bution for social media forensics[J]. IEEE Transactions on In-formation Forensics and Security, 2017, 12(1):5-33.
[6] Koppel M, Winter Y.Determining if two documents are writ-ten by the same author[J]. Journal of the Association for Infor-mation Science and Technology, 2014, 65(1):178-187.
[7] Potha N,Stamatatos E.An improved impostors method for au-thorship verification[M]//Lecture Notes in Computer Science.Cham: Springer International Publishing, 2017: 138-144.
[8]郭旭,祁瑞華,基于神经网络语言模型的作者身份验证[J/OL].情报理论与实践[2019-11-12].http://kns. cnki.net/kcms/detail/ 11.1762.G3 .20191024.1127.002.html.
- 用电监察工作对供电企业营销服务的重要性
- 浅论城市水利建设管理中存在的问题及对策
- 城市配网自动化发展分析及其运行管理模式研究
- 关于某电厂500kV启备变跳闸事故分析
- 电气施工中强电施工电缆安装技术初探
- 电气设备局部放电的超声波检测的研究
- 智能配电网技术在配电网规划中的应用分析
- 智能电网环境下继电保护面临的问题分析
- 电力系统及其自动化技术的安全问题分析
- 电气自动化在智能建筑中的应用
- 配网调度运行安全监管的意义及防控措施
- 10kV配电网自动化系统的智能化建设分析
- 调度在电网事故处理中的作用
- 浅谈平罗县农村集中式供水工程运行管理存在问题及措施
- 10kV线路过电压保护器的运维与故障原因分析
- 浅谈建筑给排水节能节水技术
- STATCOM对线路距离保护影响研究
- 智能电网的电力调控一体化探讨
- 电气试验在变压器故障分析中的应用研究
- 避雷器及并联间隙的应用对输电线路运行的影响分析
- 浅析中小型水电站安全管理模式
- Ag对Sn0.7Cu0.12Ni焊料性能影响研究
- 机械制造工艺与机械设备加工工艺的探讨
- 基于模糊层次分析的汽车故障维修方法
- 复杂汽车变速箱壳体的三坐标检测方法及误差探究
- pop-off
- pop out
- popped
- popped-out
- popper
- poppers
- poppies
- popping
- popping-off
- poppy
- poppylike
- pop quiz
- pops
- pop's
- popsicle
- popsicle™
- pop the question
- pop-the-question
- populace
- populaces
- popular
- popularise
- popularised
- popularises
- popularish
- 衣冠辐辏
- 衣冠适越
- 衣冠齐楚
- 衣决
- 衣刷
- 衣剑
- 衣包
- 衣匳
- 衣单
- 衣单薄而身寒冷
- 衣单身寒的士兵
- 衣单食薄
- 衣和裙
- 衣囊
- 衣妆楚楚
- 衣妆美
- 衣宵食旰
- 衣宽带减
- 衣宽带松
- 衣宽带缓
- 衣履
- 衣履弊穿
- 衣屩
- 衣屩褴褛
- 衣岔