范华 翁利国 周艳 姜川 孙涛


摘要:电网工单数据是电网运行情况以及客户满意程度的主要信息来源,近年来,有学者将深度学习的方法应用于工单数据的关键信息提取,但是提取出的关键词、词还不足以完整描述工单反映的具体情况。本文提出了一种事件抽取模型,先通过一定的方式进行文本预处理,确定标签体系和特征模板,再用Bi-LSTM和CRF相结合的模型进行实体识别和标注,最后通过TFIDF模型提取出事件表达,将该模型用于电网工单数据的事件抽取,用准确率、召回率和F1得分作为模型的评价标准,证明了该模型在工单数据分析中的可用性。
关键词:双向长短期记忆网络;条件随机场;词频-逆文件频率算法;电网工单;事件抽取
中图分类号:TP183 文献标识码:A
文章编号:1009-3044(2020)04-0291-03
收稿日期:2019-10-15
作者简介:范华(1971—),男,浙江杭州人,浙江中新电力工程建设有限公司,高级工程师,硕士,配网自动化;翁利国(1982—),男,浙江杭州人,国网浙江杭州市萧山区供电有限公司,高级工程师,硕士,配网自动化。
Event Extraction of Power Customer Service Order Based on BiLSTM-CRF and TFIDF
FAN Hua',WENG Li-guo',ZHOU Yan',JIANG Chuan',SUN Tao'
China)
Abstract:Power Customer Service Order data is the main source of information on grid operation and customer satisfaction.In recent years,some scholars have applied the method of deep learning to the key information extraction of work order data.However,the extract-ed keywords and words are not enough to fully describe the specific situation reflected by the work order.This paper proposes an event extraction model,which firstly performs text preprocessing in a certain way,determines the label system and feature template,and then uses Bi-LSTM and CRF model for entity recognition.Finally,the event expression is extracted by TFIDF model.This paper uses the :model for the event extraction of the power customer service order.This paper chooses the accuracy,recall rate and F1 score as the eval-uation criteria of the model,and prove the availability of the model in the analysis of work order data.
(1.Zhongxin Power Engineering Construction Corporation of Zhejiang,Hangzhou 3 10000,China;2.Power Supply Construction Corporation of Hangzhou Xiaoshan District of Zhejiang State Grid,Hangzhou 310000,China;3.Shanghai University of Electric Power,Shanghai 201300,
Key words:Bi-LSTM;CRF;TFIDF ;Power Customer Service Order;Event Extraction
工单数据包含了各类客户投诉信息以及供电局员工的解决方式和最后的处理结果。然而,这些数据都是非结构化的文本信息,传统的分析数据的方式依赖大量的人工阅读和整理,对工作人员的经验也较高要求[1]。
事件抽取是信息抽取任务中的一种,旨在从非结构化信息中抽取一个完整事件的事件表达和关键要素,并以结构化数据的形式传递给用户。事件抽取的结果包含表示事件类型的触发词以及事件要素,触发词是可以表示事件的关键词,常常是.动词或者名词,事件要素根据事件类型的不同有不同的定义方式[2-3]。本文将事件抽取技术应用于工单数据分析,以客户反应的问题作為事件表达,并提取出时间、事发地点、工作人员作为事件要素。
本文做出的贡献有:
1)提出将事件抽取应用到工单数据分析中,不仅降低了对人工的依赖性,也保证了事件表达的完整性;
2)将TFIDF应用于事件触发词的提取,扩大了事件类型的范围,准确描述每个工单所反映的问题。
1 模型构建
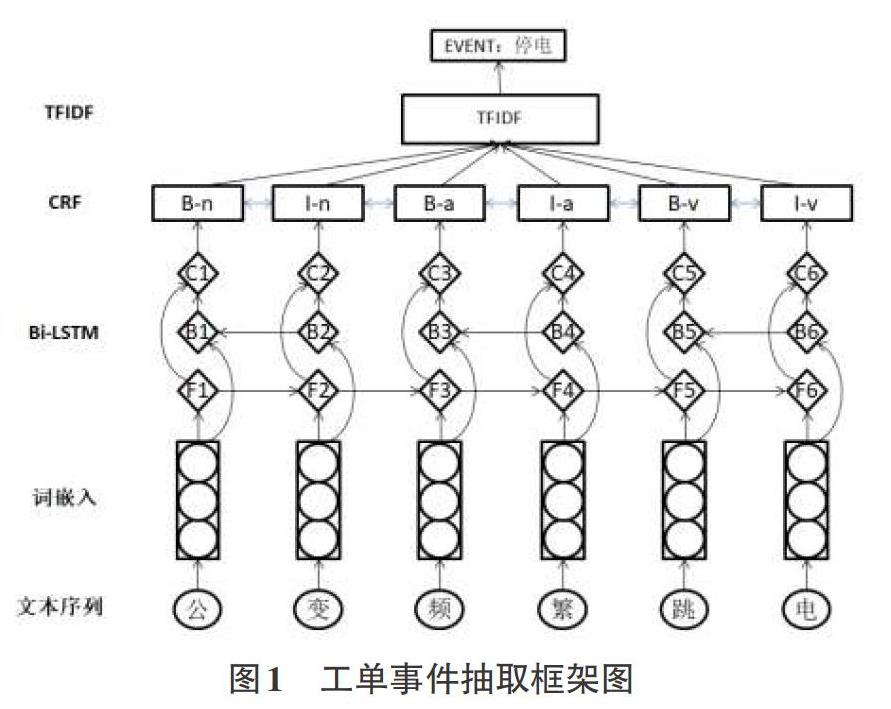
本文提出的模型由三个部分组成,工单数据预处理、基于Bi-LSTM和CRF的实体识别以及基于TFIDF的事件表达提取。
工单数据预处理部分将对原始数据进行分词,对于电气专有名词等构建词典,并且通过word2vec将文本转化成词向量。
实体识别部分对预处理过的工单数据进行序列标注,通过双向长短期记忆网络捕获句子级特征,将提取到的特征输入softmax,层,计算当前的词对应每个标签的置信度,最后将置信度分数输入条件随机场模块中进行序列标注,得到每个词的最大可能的标签。
事件表达抽取部分,將条件随机场标注出来的名词、动词集中到一起,计算每个词的词频-逆文档频率,得分最高的词即为该工单中最为重要的词,可以作为事件表达。
从输入到实体识别部分的模型结构如图所示:
1.1 工单数据预处理
电网的工单处理经过包含了客户反应的问题,故障发生的时间和地点,核实情况的单位,处理问题的工作人员,以及处理的大致过程。一般的分词方式无法准确识别如“频繁停电”“开关故障”“令克掉落”这种电气专有词汇[4],因此针对工单数据,建立了分词词典。
采用jieba分词工具,选用精确分词模式,导入建立的分词词典,以保证分词结果的准确性。
1.2基于Bi-LSTM和CRF的实体识别
LSTM(Long Short Term Memory),长短期记忆网络是对序列数据进行操作的一种神经网络。LSTM加入了一个记忆单元能够捕捉到长期的依赖信息。同时加入了门控单元,用于控制输入信息的哪部分将被送人记忆单元,历史信息的哪部分将被遗忘[5]。采用双向LSTM,将左右侧的输出拼接起来得到最终的词向量表示,最终的词向量将包含该词的上下文信息。
将分好词的工单数据输入word2vec模型训练成词向量,并传人Bi-LSTM中,从而获得对实体标注有效的特征。但是,Bi-LSTM捕获到的特征只能表示当前的词对标签结果的影响,对于整个序列的标注而言这是不够的,条件随机场可以解决这个问题。
条件随机场(Conditional Random Field,CRF)是一种 条件概率分布模型,由两组随机变量组成,是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型"。相比传统的基于规则的模型,CRF不需要设置规则,也就不需要考虑规则所带来的局限性;相比同为基于模型的HMM,CRF模型可以捕捉序列元素中相邻元素的影响,不局限于任何时刻观察值。对于工单数据这样的非结构化文本,每一条客户投诉内都包含了大量的信息,关键信息之间也存在丝丝缕缕的关系,因此,CRF是更好的选择,考虑到精度足够而训练复杂度最低,选择BIO(B-begin,I-inside,O-outside)标签体系来做序列标注。
Bi-LSTM部分输出的是一个可以表述当前位置特征的得分,CRF模块将词组成序列,考虑标签之间的依赖关系,找到得分最高的标签序列。
选择人民日报2014年的标注语料训练模型[9],该语料库对纯文本进行了词语切分和词性标注,此外,将专有名词人名标注为nr,地名标注为ns,机构名标注为nt,可以针对其标注提取出想要的关键词。
对于工单数据而言,需要提取出的主要是地名、时间和人名,而许多标注对没有帮助,所以需要先对语料库进行预处理:
1)姓名的合并:需要将人名中的姓和名两部分合并;
2)时间类合并:需要将连续的年、月、日合并到一起;
3)语料中有中括号括起来的词,该部分表示大粒度分词,是有代表性的名词,也需要合并。
选用sklearn_crfsuite工具包中的CRF模块训练模型,采用lbfgs算法,惩罚系数设置为0.1,迭代次数设置为100次。选用准确率、召回率和F1分作为评估标准,训练结果如下:
1.3 基于TFIDF的事件提取
从事件抽取的定义来看,事件的概念相对宽泛,没有明确的定义,而事件表达可以通过动词或者名词来表达,因此,可以通过提取出重要性最高的名词、动词集合,从而提取出事件的触发词。
TFIDF(term frequency-inverse document frequency,词频-逆向文件频率),是一种用于信息检索与文本挖掘的常用加权技术,计算词的词频和逆向文件频率之差,作为其重要性的评价。字词的重要性与它在文件中出现的次数成正比,与它在语料库中出现的频率成反比[7]。因此,如果某个词在一篇文档中出现的频率很高,并且在其他同批文档中很少出现,则认为该词或者短语具有很好的类别区分能力。
本文中,每个词条的词频表示的是该词条在对应的一条工单信息中出现的频率,词条的逆向文件频率的计算则是用工单中信息的总条数除以包含特定词条的文章数加1,并取对数。通过这样的设计,可以保证像“频繁停电”“开关故障”这样的具有代表性的词可以被重视起来,又可以保证其不会被“客户”“用户”这样 的词取代,而且不同的工单情况会被有效区分开来。
2 实验结果;
将185条 工单数据按专业人员的要求进行了事件要素和事件表达的标注,经过运行后将结果保存,并统计准确率,结果如下:
工单事件抽取的示例如下:
工单数据事件提取的结果可以总结为以下几点:
1)模型成功地提取出了工单中事件的完整表达,包括事件的类型以及事件发生的时间、地点和相关人物,将非结构化的工单数据转化成结构化的文本,结果显示的都是需要了解的关键问题,大幅度减少了人工阅读和整理;
2)采用Bi-LSTM捕获工单文本的上下文信息,提取出句子级特征,保证了特征提取工作的可靠性;采用CRF进行序列标注,相比HMM的提取效果更加准确;采用TFIDF进行事件类型的提取,根据每条工单处理过程的描述找到最关键的词作为事件表达,提取结果的准确率在75%以上,召回率在69%以上,F1分在0.72以上,说明了模型的可行性。
3 总结
本文通过Bi-LSTM、CRF和TFIDF算法进行工单的事件抽取,将非结构化的工单数据转化为结构化的信息,提取出了工单处理过程中的时间地点、负责该工单处理的人员和客户反应的问题,大幅度减少了人工阅读的工作。实验表明,模型可以准确提取出大部分工单数据的事件要素和事件类型,对于没有准确识别出来的要素,可以通过扩展词典和增加人工标注来提高对事件类型的识别能力和范围,此外,事件抽取也可以为工单分类、情感分析提供方便。
参考文献:
[1]邹云峰,何维民,赵洪莹,等.文本挖掘技术在电力工单数据分析中的应用[J].现代电子技术,2016,39(17):149-152.
[2]丁麒,庄志画,刘东丹.基于文本数据挖掘技术的95598业务工单主题分析应用[J].电力需求侧管理,2016,18(S1):55-57.
[3]吉久明,,陈锦辉李楠,等.中文事件抽取研究文献之算法效果分析[J].现代情报,2015,35(12):3-10.
[4]邱奇志,周三三,刘长发,等.基于文体和词表的突发事件信息抽取研究[J].中文信息学报,2018,32(9):56-65,74.
[5]朱颢东,杨立志,丁温雪,等.基于主题标签和CRF的中文微博命名实体识别[J].华中师范大学学报:自然科学版,2018,52(3):316-321.
[6]徐静,杨小平.基于CRF模型的网络新闻主题线索发掘研究[J].中文信息学报,2017,31(3):94-100.
[7]孔秋强,贺前华.基于TFIDF与分类树的工程文本信息分类法[J].计算机应用与软件,2014,31(6):174-176,191.
[8]李静月,李培峰,朱巧明.一种改进的TFIDF网页关键词提取方法[J].计算机应用与软件,2011,28(5):25-27.
[9]张永伟,顾日国.基于大规模语料库的情感与修辞互动研究[J].当代修辞学,2018(3):38-54.
[通联编辑:唐一东]
- 浅析北海盆地油气分布特点及石油地质的条件
- 地质钻探项目精细化标准化管理探讨
- 新疆西昆仑甜水海岩群变质岩原岩恢复及形成环境
- 浅论测绘技术在智慧城市建设中的应用
- 阿拉善左旗呼仁德勒多金属矿点地质特征
- 江西省某煤矿开采对矿山地质环境影响分析
- 内蒙古基东地区公婆泉组火山岩锆石年代学及地球化学特征
- 西藏铁矿典型矿床及成矿规律初步研究
- 试论永康群与天台群地层时代关系
- 唐山—古冶土壤Se、Hg异常成因及生态效应
- 地震作用下岩质边坡倾倒破坏探讨
- 构造单元划分及岩石变质作用概述
- 高密度城市形态下的规划探索
- 鄂尔多斯沉积盆地形成演化过程浅析
- 论浊积岩研究历史现状及发展趋势
- 浅析多源性地理信息空间下数据集成模式
- 分析城市道路设计思路与技术要点
- 新形势下地质调查业务团队建设研究
- 我国城郊村人居环境安全性探讨
- 沉积地球化学的研究方向及发展趋势
- 英国地理信息产业发展现状及对我国的启示
- 甘孜州藏民聚落空间数理关系初探
- 防雷技术设计在输气站中的分析
- 摄影测量与遥感技术发展现状与趋势研究
- 我国绿柱石辐照改色研究进展
- administratorship
- administratorships
- administratress
- administrer
- admins
- admirabilities
- admirability, admirableness
- admirable
- admirablenesses
- admirably
- admiral
- admiralissimo
- accountingcycle
- accounting cycle
- accountingequation
- accounting eˌquation
- accounting period
- accountingperiod
- accountingprinciple
- accounting principle
- accounting rate of return
- accountingrateofreturn
- accounting rates of return
- accountingratio
- accounting ratio
- 朝霞危岫,暮霭平芜
- 朝霞暮霞,无水煎茶
- 朝霞暮霞,无水煎茶。
- 朝霞满天
- 朝露
- 朝露夕槿
- 朝青
- 朝靴
- 朝鞭绕
- 朝食
- 朝鮮
- 朝鲜
- 朝鲜“歌坛两翁”
- 朝鲜、日本等东方诸国
- 朝鲜人的姓名
- 朝鲜停战协定
- 朝鲜半岛
- 朝鲜古典小说的三大传
- 朝鲜战争
- 朝鲜战斗诗人
- 朝鲜族
- 朝鲜族婚宴上为什么没有糜子年糕
- 朝鲜族荡秋千的来历
- 朝鲜李朝实学派集大成学者
- 朝鲜民族