姚玲洁

摘要:针对贷款欺诈问题,该文使用随机森林对真实信用卡贷款数据进行特征排序,采用逻辑斯特回归构建信用卡反欺诈预测模型,训练获得的模型正确率较高,可应用于贷款欺诈预测系统中。
关键词:贷款交易欺诈;机器学习;随机森林;逻辑斯特回归;反欺诈
中图分类号:TP181 文献标识码:A
文章编号:1009-3044(2020)14-0260-03
1引言
随着国家不断增强对自主创业的支持力度,贷款已经成为一种非常重要的支付手段。然而,犯罪分子也关注到这种便利方法,使用各种虚假信息欺诈银行或者金融机构。因此构建一个可行性高、便利的交易欺诈预测模型对于维护正常的经济秩序是必不可少的。
近年,随着机器学习的深入发展及计算机硬件的处理数据能力不断提升,不少学者逐渐将关注点聚集在机器学习应用上。关于交易欺诈预测研究,文献[1]利用模糊神经网络、并行处理可快速产生欺诈规律信息。文献[2]利用决策树、布尔逻辑函数、聚类分析判定欺诈行为。文献[3]改进Apfiori算法挖掘欺诈交易的规律。文献[4]将BP神经网络应用在信用卡反欺诈研究中。文献[5]提出了一种基于大数据技术的三层反欺诈模型,支持日终批量检测信用卡的交易异常行为。文献[6]依赖于专家规则模型进行欺诈交易识别,过度依赖专家制定的规则。文献[7]先对数据进行数据预处理、再训练出可实施的五层DBN交易欺诈评分模型。文献[8]建立了一个基于SVM的反欺诈模型,先将kaggle中的银行卡消费数据进行预处理、缩放选择特征,再采用smote算法处理数据集的分布不均问题,调整参数形成最佳的训练模型后后,准确率达到97.00%。文献[9]提出了结合规则引擎、数据挖掘模型、人工校验方法,建立了一套互助互补、更加高效的信用卡反欺诈模式。本文采用机器学习里的随机森林、逻辑斯特回归算法应用于贷款交易欺诈判定中。
2贷款欺诈检测原理
信用卡反欺诈是利用信用卡的历史交易数据,构建信用卡反欺诈预测模型,提前发现客户信用卡被盗刷的事件。
3构建机器学习模型
3.1数据预处理
本文使用公开库kaggle的部分交易数据来训练及验证机器学习模型,并将欺诈行为和正常交易行为做出相应的标记。因公开库的数据量庞大,因此本文随机抽取284707条数据来做验证。正常交易信息是284315条,贷款欺诈信息为492条。
如图1的(a)(b)所示:数据严重不平衡,负样本f欺诈时的值为1的样本)的数量太少,如果不进行处理,直接用这样的数据来进行训练建模,会使得到的模型效果不佳。
因此需进行样本数据处理,主要有两种思路。
(1)下采样
对于数据集中出现的数量严重不等的两类数据,从数量比较多的那类样本中,随机选出和数量比较少的那类样本数量相同的样本,最终组成正负样本数量相同的样本集进行训练建模。
(2)过采样
本文使用过采样的方法把数据扩充到相匹配的程度,去除一些负样本,使得正负样本数目接近,从而处理样本不平衡问题,最后进行训练学习。由于随机过采样采取简单复制样本的策略来增加少数类样本,容易产生模型过拟合的问题,使得模型学习到的信息过于特别而不够泛化。
本文采用的是随机过采样算法的改进方案SMOTE。具体过程是先分离数据中的特征和标签,再将数据分成训练数据和测试数据,其比例为7:3,最后利用SMOTE来处理训练样本,得到均衡的训练样本。
3.2特征工程
特征工程是指自变量x对因变量v有明显影响作用的特征,特征工程可分为三个方面:特征构建、特征提取、特征选择。
特征构建是指从原始数据中人工的找出一些具有物理意义的特征。特征提取有多种常用的方法,如主成分分析法、LDA线性判别分析法、ICA独立成分分析法等。特征选择是最重要的步骤,是为了剔除不相关或者冗余的特征,減少有效特征的个数,减少模型训练的时间,提高模型的精确度。本文采用随机森林算法获取数据的显著特征。具体实现过程如下:
首先将目标变量进行可视化,显示的结果。其次进行特征衍生,特征Time的单位是秒,转化为以小时为单位对应每天的时间。再进行查看信用卡正常用户和异常用户之间的区别。从图2中可以看出,在贷款欺诈的事件中,部分变量之间的相关性更明显。其中变量v1、V2、v3、V4、V5、V6、v7、V9、v10、v11、V12、V14、V16、V17和V18以及V19之间的变化在信用卡被盗刷的样本中呈性一定的规律。另外,诈骗交易、交易金额和交易次数存在如图3所示关系。
查看数据的维度后,特征从28个缩减到了18个,其中不包含目标变量。最后对特征的重要性进行排序,具体过程为先构建x变量和Y变量,利用随机森林的feature impo~ance对特征的重要性进行排序,排序结果如图4所示。
3.3模型训练
3.3.1样本不平衡处理
构建自变量和因变量处理样本不平衡,样本个数共284807个,正样本占99.83%,负样本占0.17%。特征维数为18。
3.3.2构建分类器进行训练
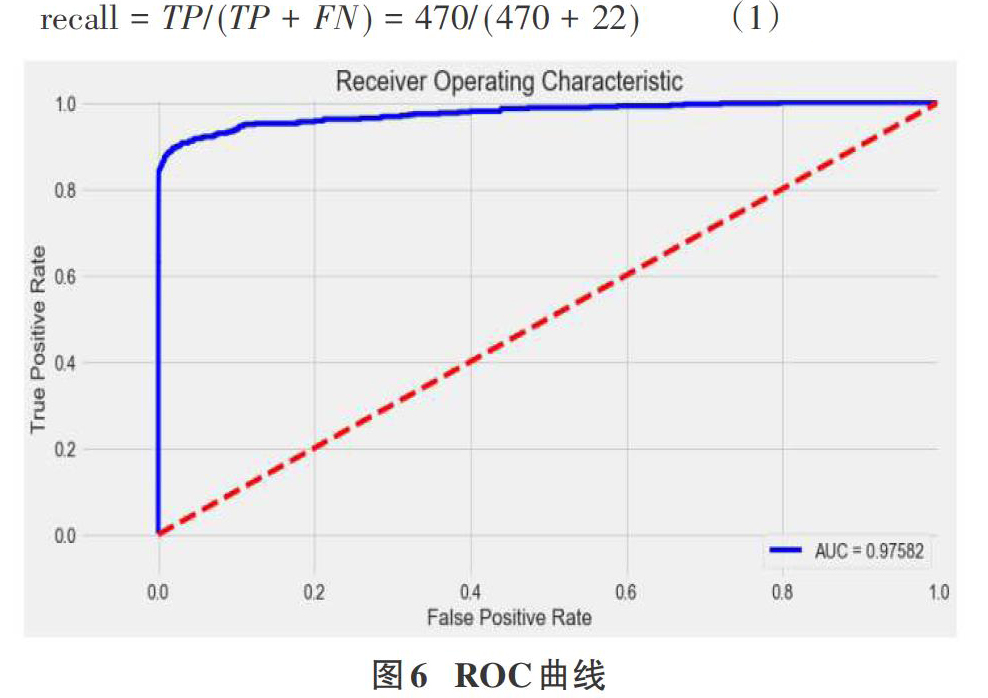
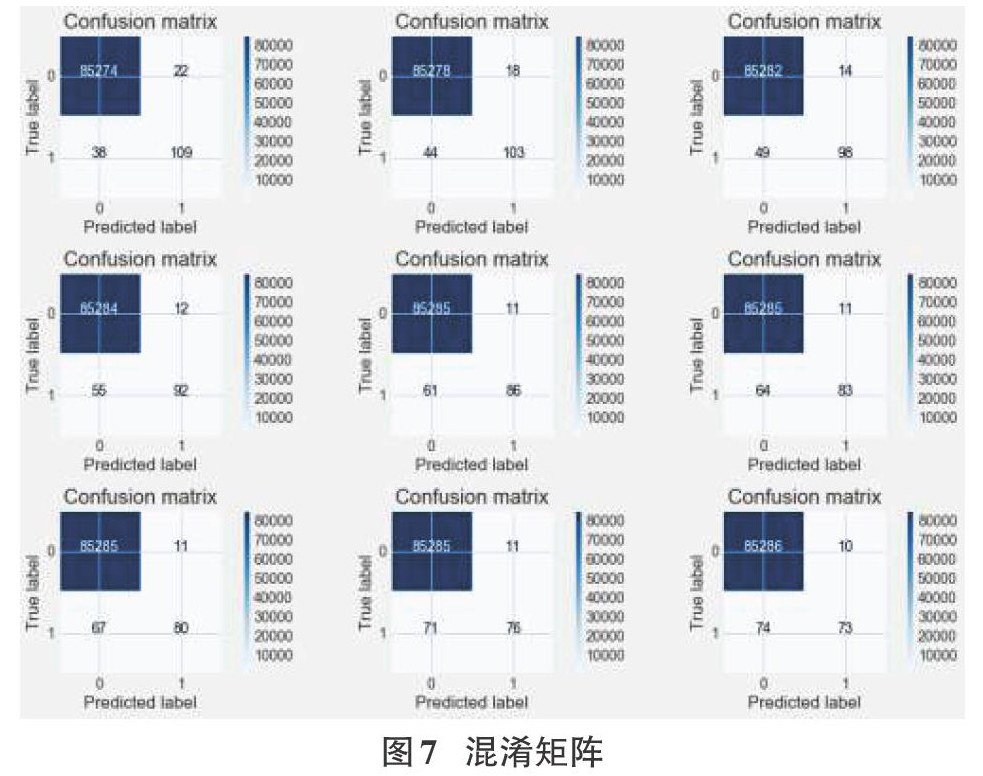
构建逻辑回归分类器进行训练,产生测试集的预测精度分值结果为0.99992。生成混淆矩阵(如图5)后,测试数据集中的召回度量为0.955284552846,阈值默认值为0.5,绘制ROC曲线。
3.4模型评估与优化
上一个步骤中的模型训练和测试都在同一个数据集上进行,会导致模型产生过拟合。一般来说,将数据集划分为训练集和测试集有3种处理方法:留出法、交叉验证法、自助法。
本文采用交叉验证法划分数据集,将数据划分为3部分:训练集、验证集和测试集。让模型在训练集进行学习,在验证集上进行参数调优,最后使用测试集数据评估模型的性能。模型调优采用网格搜索调优参数,通过构建参数候选集合,网格搜索穷举各种参数组合,再根据设定评定的评分机制找到最好的那一组设置。最后结合cross-validation和gird search,具体采用scikit learn模块modd_sdecfion中的GridSearchCV方法。
precision和recall是一组矛盾的变量。从上面混淆矩阵和PRC曲线可以看到,阈值越小,recall值越大,模型能找出信用卡被盗刷的数量也就更多,但换来的代价是误判的数量也较大。随着阈值的提高,recall值逐渐降低,precision值也逐渐提高,误判的数量也随之减少。通过调整模型阈值,控制模型反信用卡欺诈的力度,若想找出更多的信用卡被盗刷就设置较小的阈值,反之,则设置较大的阈值。
实际业务中,阈值的选择取决于公司业务边际利润和边际成本的比较;当模型阈值设置较小的值,确实能找出更多的信用卡被盗刷的持卡人,但随着误判数量增加,不仅加大了贷后团队的工作量,也会降低误判为信用卡被盗刷客户的消费体验,从而导致客户满意度下降,如果某个模型阈值能让业务的边际利润和边际成本达到平衡时,则该模型的阈值为最优值。当然也有例外的情况,发生金融危机,往往伴随着贷款违约或信用卡被盗刷的概率会增大,而金融机构会更愿意不惜一切代价守住风险的底线。
4实验数据测试
将random_state设置为0,每次切分的数据都一样,构建参数组合。确定模型Logistic和参数组合param_grid,cv指定10折,使用训练集学习算法得到测试集的精确度为0.99916。
5总结
本文首先介绍了贷款欺诈的背景,其次讲述了近年来学者们应用方法的优缺点,最后描述了如何利用真实的信用卡历史交易数据,使用机器学习构建信用卡的反欺诈预测模型,从而提前判定信用卡被盗刷的非法行为。从这个模型的测试结果来看,将机器学习可应用于贷款欺诈系统的建立中,能够降低误判率,效果良好。
- 急诊护理对抢救成功的心脏骤停危重孕产妇生活质量影响分析
- 不同护理模式在脑梗塞患者中的护理效果对比分析
- 生活饮用水水质微生物检验分析
- 小针刀松解联合腰神经阻滞注射治疗腰椎间盘突出症的临床研究
- 观察依那普利片联合乌拉地尔注射液治疗冠心病合并心力衰竭的临床疗效及安全性
- 盐酸氨溴索不同给药方式治疗慢性支气管炎急性发作临床疗效的比较研究
- 快速康复外科理念在阑尾炎围术期中的应用效果分析
- 手外科开放性创伤术后伤口感染危险因素分析及预防对策
- 米非司酮与利凡诺联合用于中期引产的疗效
- 健康宣教对于支气管哮喘患者肺功能改善的效果分析
- 疾病预防控制机构微生物检验质量与控制过程分析
- 达菲林联合戊酸雌二醇治疗子宫内膜异位症的疗效及对炎症因子的影响效果观察
- 右美托咪定麻醉前滴鼻在小儿麻醉的临床应用
- 老年重症心力衰竭急诊内科治疗的临床效果分析
- 口腔正畸术联合种植支抗治疗在牙齿矫形术中应用效果
- 胺碘酮联合厄贝沙坦对心力衰竭合并心律失常的临床疗效观察
- 艾司奥美拉唑、胶体果胶铋联合呋喃唑酮、阿莫西林对幽门螺旋杆菌的根除效果观察
- 复方血栓通胶囊联合羟苯磺酸钙治疗早期糖尿病性视网膜病变
- 阿昔洛韦滴眼液联合糖皮质激素治疗重度病毒性角膜炎的疗效观察
- 观察卡培他滨联合奥沙利铂三周化疗方案对大肠癌患者免疫功能的影响
- 欣母沛联合催产素预防有高危因素产后出血的临床疗效分析
- MIPPO技术结合锁定钢板治疗胫骨远端骨折的临床疗效分析
- 单纯性牙周治疗与牙周正畸联合治疗牙周病的疗效比较分析
- 腰麻硬膜外联合阻滞用于妊娠高血压综合征产妇分娩镇痛的临床观察
- 贝伐单抗联合培美曲塞治疗肺腺癌的临床效果分析
- unanalogous
- unanalogously
- unanalogousness
- unanalogousnesses
- unanalysability
- unanalytic
- unanalytical
- unanalyzably
- unanalyzing
- unanarchistic
- unanecdotal
- unanecdotally
- unanemic
- unanesthetized
- unangelic
- unangered
- unangrier
- unangriest
- unangrily
- unangry
- unangular
- unangularly
- unangularness
- unangularnesses
- unanimatedly
- 周览
- 周览九土
- 周览泛观
- 周角
- 周言
- 周详
- 周详中肯
- 周详仔细
- 周详华丽
- 周详完备
- 周详审慎
- 周详慎密
- 周详畅达
- 周详练达
- 周详细密
- 周谋
- 周谘博访
- 周谨
- 周贫恤困
- 周贫济困
- 周贫济急
- 周贫济老
- 周贵人
- 周赈
- 周赡