叶苏婷 潘媛媛 毕迎春


摘要:【目的/意义】旨在利用机器学习中决策树算法,构建心脏病预警模型,为临床医生及患者提供心脏病预警,反映患者心脏病发病情况。【方法/过程】以python为语言基础,运用机器学习中决策树所涵盖的算法理论对心脏病数据集建立预警模型,并构建用户程序界面。【结果/结论】根据实验结果,决策树算法预测准确率相对较理想,能够较为准确的反应患者的患病情况,可为患者提供心脏病发病预警信息以及协助临床医生进行诊疗。
关键词:心脏病发病预警;机器学习;决策树
中图分类号:TP311.1 文献标识码:A
文章编号:1009-3044(2020)19-0187-03
开放科学(资源服务)标识码(OSID):
1 相关研究及问题提出
心脏病是一种临床常见非传染性的慢性疾病。临床上多表现为心绞痛,呼吸困难,心悸,胸痛不适等症状,对人的身体健康有着极为不利的影响,是当今社会导致死亡的主要疾病类型之一[1]。
决策树算法( Decision Tree)作为机器学习中进行分类与回归的代表性算法。该算法可用于分类树形结构,其中对某一属性的一次测试看作一个内部节点,根据测试所得结果看作一条边,将某个类或类的分布作为叶子节点。其中每节点判断条件由对象属性表示,其分支表示符合节点条件的对象,对象所属的预测结果由此决策树的叶子节点表示[2]。心脏病起病隐匿,病程时间长,病因复杂。传统的医疗决策模型往往难以对这类疾病进行精准分析诊断,从而导致患者发现晚、治疗不及时。通过机器学习正确诊断此类疾病,对现有医疗数据进行有效提取处理,可准确构建预测模型,预测患者是否发病,从而获得诊断结果[3]。
目前国外诸多学者对心脏病发病预警模型进行了研究[4]。2009年,Tan K C.Teoh EJ[5]提取加州欧文分校机器学习数据库心脏病数据集,在LIB支持向量机和Weka上实现,得到84.07%的预测准确率。Chaurasia、Pal[6]在2013年使用朴素贝叶斯、J48、引导聚集算法对UCI数据集中的11个特征项进行预测,获得结果显示朴素贝叶斯准确率为82.31%,J48准确率为84.31%,引导聚类算法准确率为85.03%。Parthiban、Srivat-sac7]2012年利用来自印度金奈某研究所的心脏病数据集,使用Weka平台实现朴素贝叶斯及支持向量机诊断心脏病患病率.分别得到准确率74.00%、94.60%。2015年Vem bandasamy等人[8]使用朴素贝叶斯算法对印度金奈某研究所的心脏病数据集进行分类预测,得到86.42%预测准确率。机器学习算法涵盖广泛,在模型研究时,特征变量,算法的选择不同,均会导致预测准确率差异[9]。
基于上述情况,本模型利用决策树算法对UCI克利兰夫医学研究中心的心脏病数据集构建研究模型。
2 决策树算法描述
决策树生成:一是向根节点输人数据;二是利用信息熵(或基尼系数)度量,选择数据某个特征来把数据划分成不相交的节点;三是根据数据的不确定性大小对节点进行转化分割[10],根据模型研究需求选用基尼系数作为度量。
基尼系数定义如下:
条件基尼系数根据A的不同取值{a1,……,am}对y进行限制后,先对y分别计算基尼系数,再将m个基尼系数根据特征取值本身的概率加权求和,从而得到总条件基尼系数。因此条件基尼系数越小,y被A限制后总不确定性越小,A可以帮助提供决策。
根据基尼系数度量方式从数据集中训练出一系列的划分规则,使得这些规则能够在数据集上集中体现构成了决策树的生成过程。
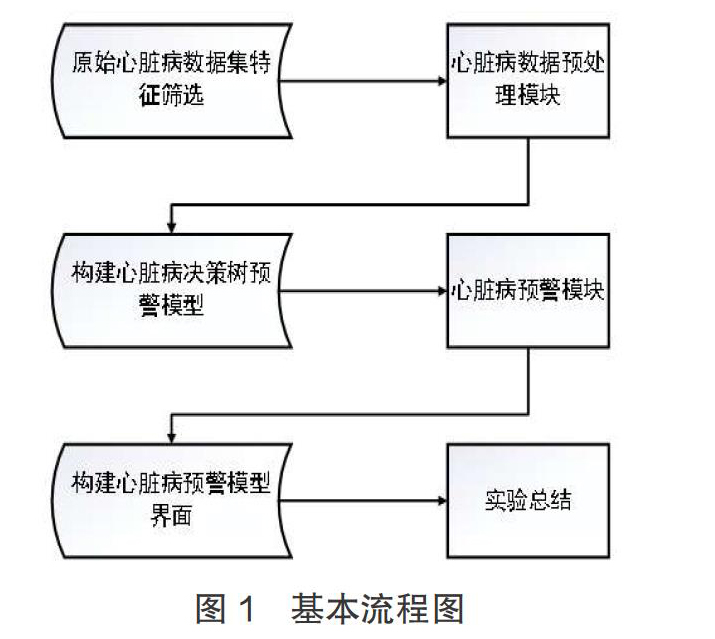
3 基于决策树算法的心脏病发病预警模型实现
基于决策树算法的心脏病发病预警模型实现,如下图1所示:
3.1 原始心脏病数据集特征筛选
研究采用来源UCI机器学习知识库的心脏病数据集,共有303个样本和76个特征,基于该数据集选用心脏病致病原因的14个特征构成特征子集,如下表1所示。
3.2 Python语言构建决策树预警模型
对本心脏病数据集进行处理过程中,可知模型预测结果为:患病(设值1)或不患病(设值0),因此将此类预测看作二分类。
Stepl数据预处理的拆分与拟合。本研究特征子集中在14个特征里提取target列作为标签列,由于此时target作为预测目标结果,在特征子集中将此列丢弃,同时对特征子集进行拆分和交叉验证。导人Skleam中train_test_split,将数据集分割为训练集和测试集,设测试集占比25%。拆分后对数据集进行拟合操作,并对数据集吻合度进行评分。
Step2决策树CART算法优化参数模型。在Sklearn模块中,根据拟合后结果,对比训练集评分数据与测试集评分数据。本研究中,特征子集中含有14个特征,样本数较大,评分对比中易呈现训练集评分高于测试集,出现决策树过拟合现象,需采用前剪枝操作。采用决策树CART算法,通过max_depth參数优化模型,获得决策树bestdepth最佳深度值。再利用min_impurity_decrease参数优化模型,由于此参数为基尼系数指定阈值,当决策树分裂后,若其增益低于此阈值bestmin即立刻停止分裂,以此限制决策树生长。
Step3决策树预警学习模型及测试。以基尼系数为度量原则,构造一棵系数值下降最快的树,遍历现有特征子集中13个特征,选择最优特征为分裂特征生成树。又将两组参数best-depth最佳深度值及阈值bestmin,代人模型,获取模型得分(tees_score)、查准率、召回率、二分类模型精确度指标( Fl_score),以上数值均在0-1间。
3.3 预警模型界面程序构建
- 辽宁建设网上中国特色社会主义理论宣传平台对策研究
- 钓鱼岛争端的国际法解读
- 新媒体环境下意识形态建设规律探索
- 马克思主义信仰中国化的当代价值与路径
- 汲取古代官德文化精华 加强党政干部修养
- 大数据环境下的我国产业竞争优势转型
- 发展现代服务业的财政对策与建议
- 基于防范人身保险欺诈行为发生的保险核保问题分析
- 中国品牌建设的战略选择
- 丝绸之路经济带框架下新疆向西开放的前景与潜力
- 用互联网思维方式推进国家治理能力现代化
- 责任政府建设的基本问题及其反思
- 自然保护区的立法宗旨与立法原则
- “三教合一”概念的历史钩沉
- 在生态文明建设中促进人和社会的全面发展
- 境界与教化:文化哲学的地位和任务
- 从处置到治理:群体性事件的治本之策
- 社会管理战略的范式转变
- 奉系军阀与奉天总商会在整顿金融乱象中的合作与冲突
- 群众路线教育实践活动与党性锻炼的时代要求
- 董事会特征与家族上市企业可持续增长关系研究
- 辽宁省产业升级的低碳优势创新
- 器官捐赠的福利经济分析
- 海洋文化产业的就业拉动效应
- 国外城镇化发展及启示
- flash flood
- flash flooded
- flash flooding
- flash floods
- flashier
- flashiest
- flashily
- flashiness
- flashinesses
- flashingly
- flash-in-the-pan
- flashless
- flashlight
- flashlights
- flashly
- flashness
- flash-on
- flash-out
- flashs
- flash's
- flashy
- flash²
- flash¹
- flask
- flasks
- 上炕不脱鞋,必是袜底破
- 上烂药
- 上照
- 上牙打下牙
- 上状
- 上献宝玉一类的珍物
- 上玄
- 上班
- 上班奴
- 上班族
- 上班走私族
- 上瑞
- 上環
- 上甘岭
- 上甘岭战役
- 上用
- 上甲
- 上电
- 上界
- 上略
- 上疏
- 上疏陈述
- 上瘾
- 上白
- 上百次的回旋