陈富秋 张棋 黄青松
摘要:亚马逊作为全球最大的产品在线零售商,其市场数据集中包含产品、客户及其评论的详细信息,若能基于顾客评论和商品信息进行文本分析,对于想要参与亚马逊平台的上市公司的产品投放和营销手段具有极大的商业价值。因此,本文旨在利用自然语言处理分析顾客的评论文本,研究顾客购物的情感倾向,结合商品星级过滤出更加客观的评价;构建商品的“评论星级”,并基于该星级建立评论的终极星级的时间序列模型,以此来预测某种商品的市场声誉变化。
关键词:文本分析;自然语言处理;时间序列;市场预测
中图分类号:TP391文献标识码:A
文章编号:1009-3044(2020)19-0196-05
开放科学(资源服务)标识码(OSID):
1 问题简述
在亚马逊的在线市场中[1],它为顾客提供了一个评论商品的机会。由亚马逊公司给出的官方数据可以得知,该数据集包含商品名称,其中被称为“星级”的个人评级允许购买者使用1(低评级,低满意度)到5(高评级,高满意度)的等级来表达他们对产品的满意度。此外,顾客还可以提交被称为“评论”的基于文本的信息,可以具体描述商品体验感受或缺陷。其他客户可以在这些评论中提供有帮助或没有帮助的评级,以帮助他们做出自己的产品购买决定。
通过建立数学模型研究以下问题:
问题一:阳光公司计划在网上市场推出并销售三种新产品:微波炉、婴儿奶嘴和吹风机。该公司的数据中心提供了三种产品的数据文件。这些数据代表了在数据显示的时间段内亚马逊市场上销售的微波炉、婴儿奶嘴和电吹风的客户的商品评论信息和商品评级。分析所提供的三个产品数据集,基于顾客评论的文本信息和商品评级建立衡量标准,为阳光公司在其三个新的在线市场产品中取得成功。
问题二:,确定并讨论每个数据集内基于时间的度量模式,这些度量模式可能表明一个产品在网上市场的声誉在增加或减少,以此来考虑产品的发展市场。
2 问题分析
2.1 问题一的分析
如表1所示,是顾客评论集的部分数据展示,针对该数据集中的各个字段,星级表示该顾客对该商品打出的评价等级,以此表达顾客对该商品的满意程度。针对其余浏览该条评论的顾客,他们可以对任意评论做出自己的判断,如果认为该评论对自己购买该商品有帮助,就投出有用票。此外,在亚马逊商城中有一类特殊用户-Vine会员,他们因撰写准确而有见地的评论而赢得的了信任,并成为会员,亚马逊会为该类会员提供免费的产品试用机会,该会员可以根据自己的用后体验编写评论,并且该会员的评论亚马逊后台无法修改或编辑。针对评论的可靠性,可以一定程度上依据该顾客是否真实购买过该产品进行初步判断。除此之外,该数据集还记录了每条评论的标题、具体文本内容以及评价时间,供其他顾客考量。
基于上述数据集,我们需要从评论的文本信息和商品星级给出综合的产品评价标准,因为在现实生活中,不免会出现有顾客恶意打低分或者故意打高分的虚假评论现象,因此我们需要在已有评论的基础上,结合该商品的星级、评论内容以及该条评论的有用票数,为每一条评论重新定义一个全新的综合评级,以此更加客观全面地判断某类商品所在的顾客市场反响如何。
2.2 问题二的分析
由于在评价过程中,存在商品评级与评论的文本内容不一致的现象,为此我们提出“评论星级”,通过比较“商品星级”和“评论星级”剔除评论内容前后不一致的数据。并在此基础上综合考虑“商品星级”和“评论星级”得到评论的终极星级,根据往年数据,基于时间序列,建立综合星级和时间变化的数学模型,并以此来预测在未来时间内三类商品的市场的声誉变化趋势。
3 模型假设
假设1:给出评论的顾客的是否购买记录对浏览商品评价的读者的购买意向没有影响。
假设2:在该数据集中,回头客的现象很少,因此不考虑回头客对商品评论的影响。
4 符号说明
5 模型—的建立与求解
5.1 模型建立
为了评判评论给定的商品星级与评论的文本内容是否一致,我们需要对评论内容进行自然语言处理(NLP)[2]。我们调用已有的词典对文本进行分类,首先利用正则表达式按空格和符号分词符剔除停用词[3],这类词汇会对基于词频的算法公式产生很大的干扰。我们需要从评论内容中提取出词干,比如单词的单复数形式、动词时态以及组合单词,并利用词典进行归一化处理。首先,计算一个词汇的基础频率:
由于亚马逊商城存在Vine用户,其发表评论的真实度和关注度远比普通用户高,故不同种类用户的评论影响程度可用如下公式表示:
在提供的数据集中,有帮助投票数也会对综合星级的评定产生影响,我们将其影响程度转化为百分比Pi。我们规定,当评论没有获得任何投票数,该条评论不会对评论的综合星级评定产生影响,Pi=1;当评论的总投票数不为0时,若有帮助投票数超过总投票数的一半时,将对评价产生积极的影响;当有帮助投票数低于总投票数的一半时,将对评价产生消极的影响,故:
5.2 模型求解
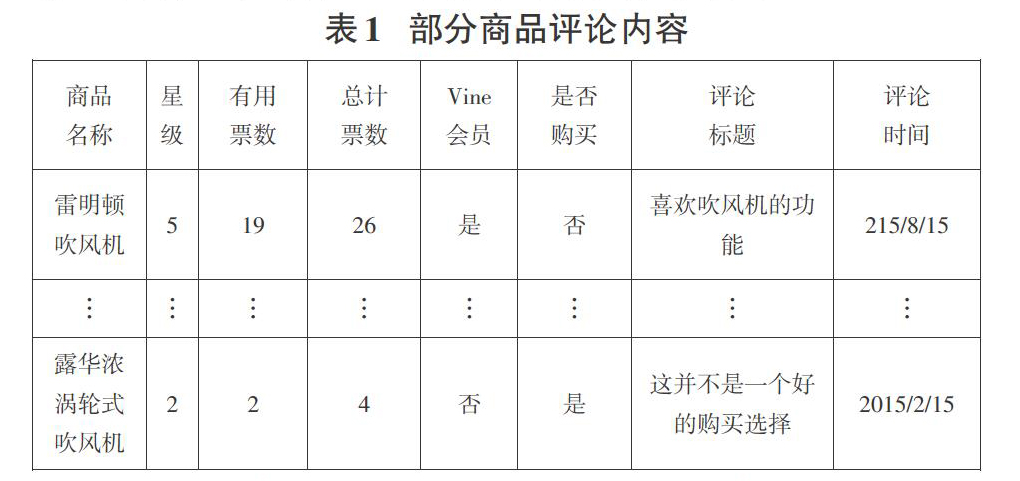
针对三类产品,我们将其用户评论的文本内容进行文本情感分析后,得到图2所示结果。
在求解每一类产品评论的综合星级时,我们根据用户的不同类型,将其评论数量、评论的总投票数量、评论的影响程度、用户的影响率做了如表3所示的统计。
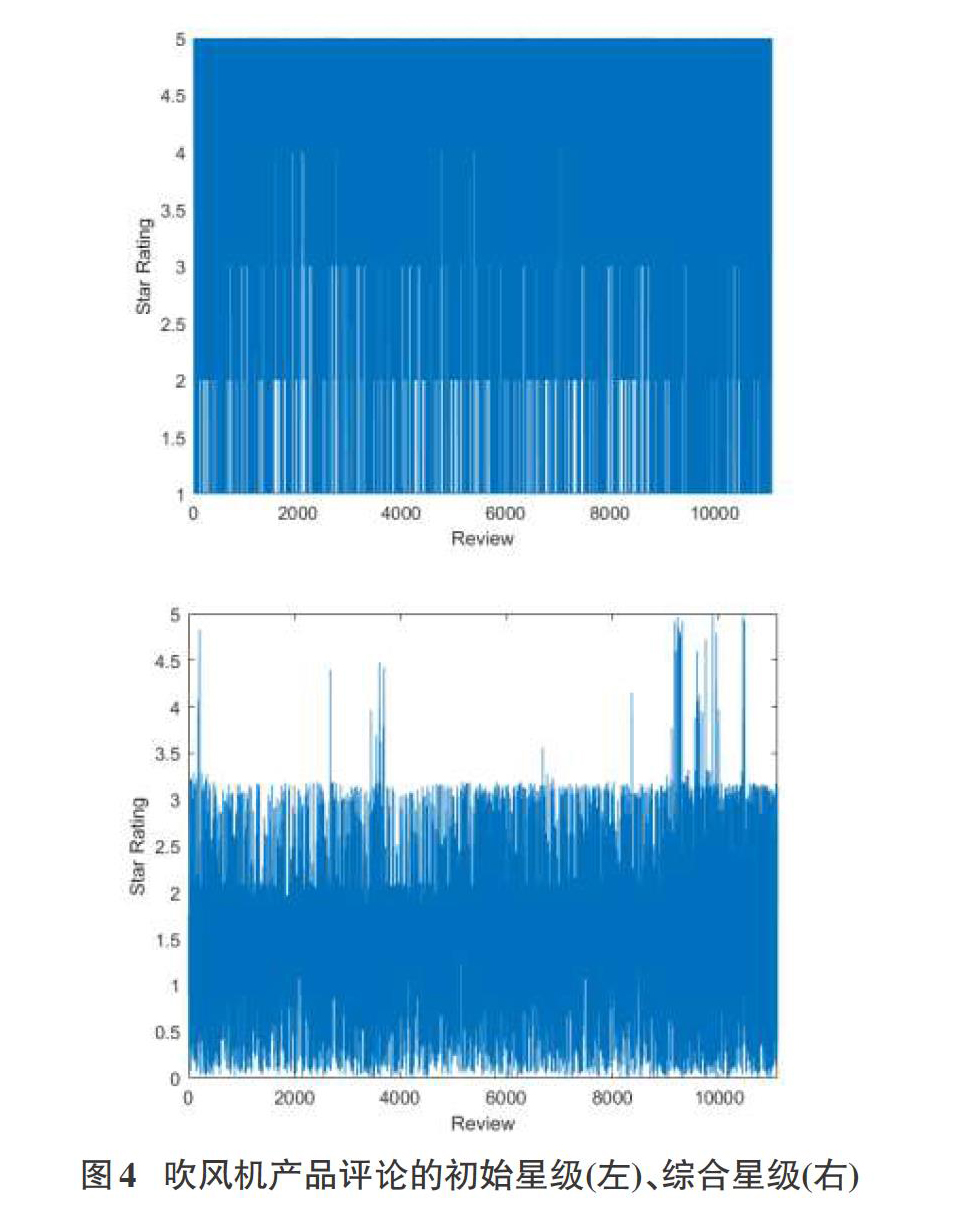
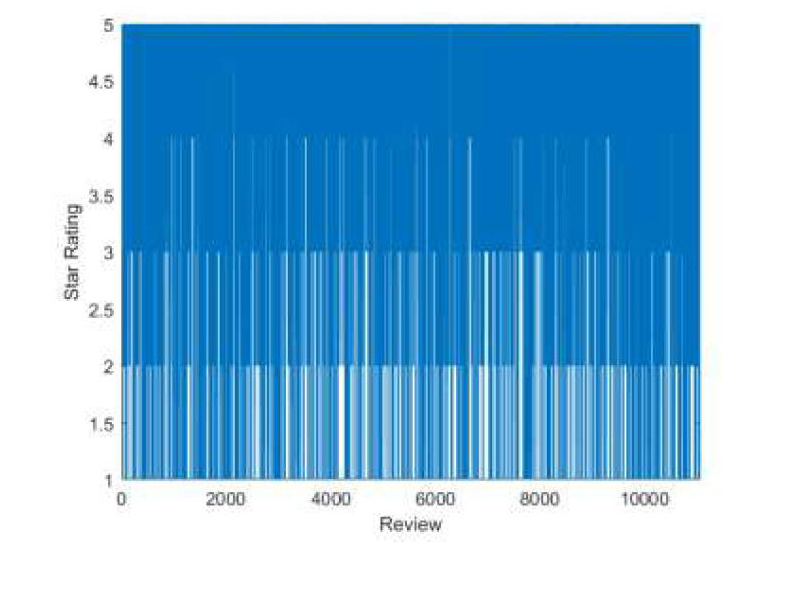
在综合考虑了评论的文本内容、商品星级、有帮助投票数、用户影响度的基础上,我们重新制定了三类商品每一条评论的综合星级,求解结果如图3-图5。
从上述结果图可以发现,三類产品评论的星级都有不同程度的变化,这表明原始的用户评论,存在部分不实现象,在综合考虑了评论文本情感、有帮助投票数、用户影响度等诸多因素后,综合星级更加客观准确,也更为其他用户提供更加真实的参考价值。
6 模型二的建立与求解
6.1 模型建立
在提供的数据集中,我们发现部分评论的商品星级和评论的文本内容不一致。例如,某用户为某一商品给出的星级是一星,但评价的内容却是“我喜欢这件商品”,我们将之称为“低分好评”。与之对应,也会存在“高分差评”的现象,因此我们需要对这类数据进行处理,剔除这部分没有价值的数据。基于此,我们根据每条评论的文本内容,给每一条评论评定一个星级,称为“评论星级”记为si,其也属于1至5星级。
6.2 模型求解
基于上述模型中的多项式,我们利用Matlab中的spline函数对三类产品进行散点图的拟合并得到较为光滑的曲线,从而求解出36x4的系数矩阵,以此得到三类产品关于时间变化的多项式函数。如图7-9展示了微波炉、吹风机、奶嘴三类产品的拟合曲线。
针对上述拟合曲线,利用Matlab工具统计出一系列数据验证拟合曲线的正确性,如表4所示。其中,SSE的值越接近于0,R-square的值越接近于1表明曲线的拟合效果越好。
在拟合曲线的基础上,我们可以求得三类产品关于时间的终极星级变化多项式,基于该多项式,我们可以分别预测三类产品在未来1月的终极星级变化,如图10所示。以及以年为单位的终极星级变化趋势,如图11所示。由图10可知,在未来一个月,微波炉的终极星级较之上月有所上升,而吹风机和奶嘴的终极星级均有一定程度下降。而在未来一年,微波炉的终极星级较之往年会有所下降,吹风机和奶嘴的终极星级较之往年均有小幅度的上升。
7 结论
综上,我们使用自然语言处理对商品评价的文本内容进行情感分析,结合产品星级、文本情感评价以及每条评论的有帮助投票数,建立模型求解每一条评论的客观评价,以此便于商品市场投放的考量。并且,基于时间序列建立终极星级的变化曲线,并以此预测商品的未来声誉变化。根据结果,我们发现,在短期内,微波炉具有较为理想的市场反响,具有一定的发展潜力。
参考文献:
[1] 2020年美国大学生数学建模竞赛C题
[2] NLP-文本情感分析https://blog。csdn.net/weixin_4239865 8/ar-ticle/details/85222547
[3]自然语言处理一停用词https://blog. csdn. net/weixin_4215 2696/article/details/86082566
[4]熵值法。 https://blog.csdn.net/fsfsfsdfsdfdr/article/details/83443562
[5] Spline(三次样条插值)https:/fblog.csdn.net/zb1165048017/arti-cle/details/48311603
【通联编辑:梁书】
收稿日期:2020-04-12
作者简介:陈富秋(1999-),通讯作者,女,四川自贡人,學士,研究方向为计算机科学与技术;张棋,男,学士,研究方向为软件工程;黄青松,男,学士,研究方向为软件工程。
- 发亮、发声:引导大学图书馆发展的新理念
- 美国高校图书馆馆员培训与发展的典型案例研究
- 国外图书馆领导力研究述评
- 面向泛在信息社会的国家战略及图书馆对策研究
- 国外高校硕博士学位论文强制性开放获取研究
- 高校图书馆超高频RFID数据模型规范研究
- 新环境下图书馆阅读推广工作探析
- 高校图书馆官方微信经营策略研究
- 基于OPAC统计数据的借阅率提升策略探讨
- 高校学生对电子书的认知、使用和态度研究:以浙江大学为例
- 图书馆视角下的MOOCs版权问题研究
- 美国高校图书馆战略规划的方向、实施及启示
- 影响矩作为测度单篇论著影响力的评价指标探讨
- 数字化信息服务对环境可持续发展的贡献研究
- 高校图书馆俄文文献收藏现状与困境分析
- 日本大学图书馆文献资源建设与共享服务研究
- 北京大学图书馆支援玉树建立“北京大学图书室”
- 上海交通大学图书馆与武汉大学信息管理学院签署战略合作协议
- 封面图片介绍:长春建筑学院图书馆
- 张元济和我国近代最早的民办图书馆
- 论高校图书馆史的编纂
- 机构知识库相关政策研究
- 电子资源管理催生图书馆新架构
- 高职院校图书馆多元化延伸服务探索与实践
- 国内移动图书馆服务模式发展现状与趋势调研
- internes
- internesia
- internet
- internetcafe
- internet cafe
- internet-café
- internetcommerce
- internet commerce
- internet/ net
- internets
- internet/the net
- interneural
- interning
- internist
- internment
- internments
- interns
- internship
- internships
- internucleon
- internucleotide
- intern²
- in short supply
- inside
- in-side
- 冫食
- 冬
- 冬不冷,夏不热
- 冬不可以废葛,夏不可以废裘
- 冬不可以废葛, 夏不可以废裘。
- 冬不可废葛,夏不可废裘
- 冬不寒,腊后看
- 冬不拉
- 冬不拉弹唱
- 冬不极温,夏不极凉
- 冬不论三九,夏不论三伏
- 冬之旅
- 冬事
- 冬云
- 冬令
- 冬令营
- 冬仨月的活——能干多少干多少
- 冬侵合一说
- 冬冬
- 冬冬呛
- 冬冬鼓
- 冬凌
- 冬前不结冰,冬后冻杀人
- 冬南夏北,有风便雨
- 冬去夏来