陈津徽 张元良 尹泽睿

摘要:在深度学习中,传统的卷积神经网络对面部表情特征的提取不充分以及计算参数量较大的问题,导致分类准确率偏低。因此,提出了一种基于改进的VGG19网络的人脸表情识别算法。首先,对数据进行增强如裁剪、翻转等处理,然后采用平均池化取代全连接操作从而大幅降低网络的参数量,最后,测试的时候采用了10折交叉验证的方法增加数据量以提升模型的泛化能力。实验结果表明,改进后的神经网络在FER2013测试数据集上的识别准确率为72.69%。
关键词:深度学习;卷积神经网络;表情识别;VGG19
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2020)29-0187-02
2016年,谷歌公司的阿尔法狗横扫围棋界取得了惊人的成绩。自此,深度学习的浪潮席卷了全球各个领域。面部表情识别技术[1-2]也随之得到了发展。同时,一些问题也随之而来,如何提高面部表情分类的准确率,如何能够在保证准确率的前提下减少计算的参数量等。
有大量研究人员或科技工作者从事于表情识别任务中,Tang[1]等人提出将(Convolutional Neural Networks, CNN)中融人SVM,同时修改了全连接层中的计算损失值的方法,在表情数据集上的测试结果为71.2%,斩获了当年Kaggle比赛的一等奖。Howard等人[2]提出了一种MobileNetV2网络结构,它是基于一个反向残差结构,其中输入和残差块的输出是薄的瓶颈层,而中间层是一个轻量级的深度卷积来过滤特征。最终得到的准确率为:70.8%。采用了多尺度核卷积单元主要以深度可分离卷积为基础,分支中采用了的线性瓶颈层结构,对表情进行了分类获得了70. 8%的识别率。Li等人[3]通过改进数据集来提高人脸表情识别任务的分类正确率,数据集包含上万张面部图像,每个图像被单独标记约40次,然后使用EM算法(Expecta-tion Maximization)用来过滤不可靠的标签。Pramerdorfer等[4]通过采用级联的CNN来改善分類结果。徐琳琳等人[5]提出一种并行卷积神经网络来缩短网络的训练时间,获得了65.6%的准确率。虽然训练时间缩短了,但是准确率没有得到实质性的提高,参数的计算量没有发生改变。深度学习中的神经网络训练的过程是一个“黑箱”操作,它具体学习到的特征是不可见的,从而使得在精读和计算量之间难以做出选择。为了解决这一问题,Szegedy等人[6]提出了梯度反向传播来可视化训练过程中学习到的特征。
针对以上人脸表情识别任务中存在的问题,本文提出了一种基于改进的VGG19网络的人脸表情识别方法。首先,通过对数据进行增强处理,如随机裁剪、翻转等操作;然后,用平均池化代替原网络中的全连接层。经过实验后,网络的参数量减少了50MB左右;最后,在测试的时候,采用了10折交叉验证的方法间接增加了数据量,提升了模型的泛化能力。
1 数据集
FER2013数据集由Pierre Luc carrier和Aaron Courville通过搜索相关的情感关键词在网络上爬取的。这些图像都是经过人工标注的。它是由35886张表情图片构成,测试集28708张,公有验证集和私有验证集各3589张,每张图片是由大小为48x48像素的灰度图组成,分为7个类别,分别为中性、快乐、惊讶、悲伤、愤怒、厌恶、恐惧。图1展示了数据集中的几个样本。
2 神经网络模型
首先,利用超深度卷积神经网络提取人脸表情特征。然后,通过卷积核大小是1X1的平均池化层对提取的特征进行降维。最后,采用带有动量的随机梯度方法对算法进行优化,通过softmax函数来进行分类。
在训练过程中,改进后的网络结构的参数量如表1所示。表格只统计了网络结构中所有的卷积层,不包含其他网络层。相比原始VGC网络中140MB大小的参数量,减少了50MB左右,大大节省了计算资源和训练时间。
3 实验结果与分析
硬件条件:InteI(R) Core (TM) i5-7300HQ,GTX 1050ti-4GB,16 GB of RAM。
实验环境:Windowsl0,Python 3.6.8,Pytorch 0.4.1。
将改进的VGG19分别在FER2013和CK+两个数据集上进行了实验。
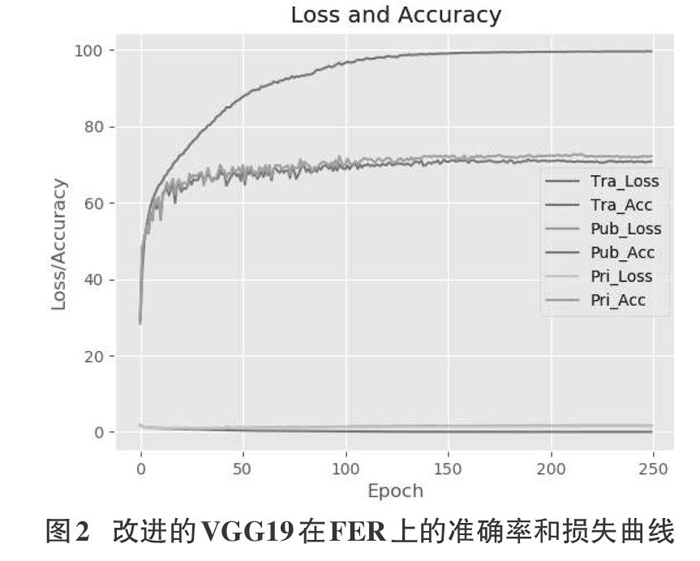
我们做了一系列的实验,它们都遵循这样一个过程:数据预处理(包括数据增强)一搭建神经网络一训练一测试一评估模型。其中一组实验单独使用CNN(VGG19)对FER2013进行了实验。经过约10小时250轮的训练获得训练模型并在测试集上进行测试。准确率为72.69%。我们在图2中分别记录了训练、验证、测试时的准确率曲线和损失曲线。
4 结语
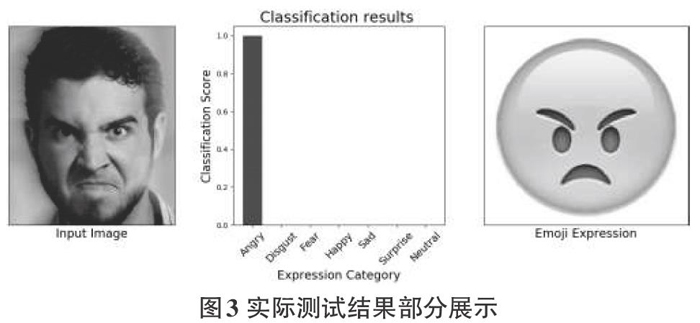
本文提出了一种用于人脸表情识别的改进的VGG19网络,并且验证了模型的有效性。在表情识别任务中,取得了比较高的准确率。此外,数据预处理、超参数调整、损失函数的选择等都可以进一步提高网络的表情识别效果。模型的实际测试结果如图3所示。
参考文献:
[1] Tang Y.Deep learmng using linear support vector machines[J]. arXiv preprint arXiv:1306.0239.2013.
[2] Howard A,Zhmoginov A,Chen L C,et al.Inverted residualsand linear bottlenecks: Mobile networks for classification. de-tection and segmentation[J] 2018.
[3] Li S,Deng W H,Du J P.Reliable crowdsourcing and deep local-ity-preserving learning for expression recognition in the wild[C]//2017 lEEE Conference on Computer Vision and PatternRecognition (CVPR). 21-26 July 2017, Honolulu. Hl. USA.lEEE, 2017:2584-2593.
[4] Pramerdorfer C,Kampel M.Facial expression recognition usingconvolutional neural networks:state of the art[EB/OL].2016:arX-iv:1 612.02903[cs.CV].https://arxiv.org/abs/1 612.02903.
[5]徐琳琳,张树美,赵俊莉.构建并行卷积神经网络的表情识别算法[J].中国图象图形学报,2019(2):227-236.
[6] Szegedy C,loffe S,Vanhoucke V,et al.lnception-v4,inception-ResNet and the impact of residual connections on learning[EB/01]. 2016: arXiv: 1602.0726l[cs. CV]. https://arxiv. org/abs/1602.07261
【通联编辑:李雅琪】
作者简介:陈津徽(1994-),男,安徽安庆人,研究生,研究方向:图像处理、计算机视觉。
- 高职财经类专业建设与实验实训室建设联动关系构建途径研究
- 小型农田水利工程建设管理措施探析
- 利用X射线衍射法对三七类中成药进行鉴定的可行性分析
- 提高农药残留快速检测方法准确度的研究
- 住房公积金贷款对房地产销售的影响探讨
- 浅谈医院人力资源管理
- “互联网+”背景下企业财务转型研究
- 基于平衡计分卡的绩效体系构建探究
- 建筑施工项目成本管控分析
- 家族企业财务管理存在问题及对策
- 职业导向型的财务管理专业人才培养模式分析
- 试论施工组织设计对工程造价的影响
- 新时期地方政府债务风险管理策略探究
- 浅谈大数据时代的企业财务管理
- 企业财务管理创新中管理会计的应用
- 权责发生制在事业单位会计核算中的应用探讨
- 旅游管理专业校企合作创新人才培养路径探析
- 我国非营利组织民间基金会的治理问题研究
- 浅析致远科技有限公司绩效考核制度对现代企业的启示
- “知识三角”理念视角下职业院校协同创新共同体探索
- BIM技术在建设项目管理中的应用
- 大学生参与学科竞赛动机分析及激励机制研究
- 地下径流对小流域土石坝径流环境的影响及防洪要素分析
- 园林绿化施工中绿化苗木栽植管理技术研究
- 浅谈土壤重金属污染修复技术
- hold sb to
- hold sb to ransom
- hold sb to sth
- holds off
- hold somebody/somethingoff
- hold somebody/somethingup
- hold somethingon
- hold somethingout
- hold somethingtogether
- holds on
- holds out
- hold sth against sb
- hold sth back
- hold sth down
- hold sth in check
- hold sth out
- hold sth over
- hold sth over sb
- holds together
- holds up
- hold sway
- hold talks
- hold-the-bag
- hold the floor
- hold-the-fort
- 横海纛
- 横海鳞
- 横涂竖抹
- 横涕
- 横渡
- 横渡沙漠
- 横溃
- 横溢
- 横溢的才华与潇洒的风度
- 横滋
- 横滚
- 横滥
- 横滨
- 横澜
- 横灾横沴
- 横灾飞祸
- 横炽
- 横烈
- 横牛
- 横犇
- 横玉
- 横玉柱
- 横琴
- 横生
- 横生旁出的事