俞鑫 吴明晖

摘? 要: Web网页中包含了大量异构的半结构化或非结构化数据,如何准确地从这些网页中提取有价值的信息显得极其重要。文章基于深度学习,结合BERT构建了一种新型的BERT+BiLSTM+CRF信息抽取模型,实验结果表明了该方法的有效性。
关键词: 深度学习; 信息抽取模型; Web; BERT+BiLSTM+CRF
中图分类号:TP391? ? ? ? ? 文献标志码:A? ? ?文章编号:1006-8228(2019)09-30-03
Research and application of deep learning based Web information extraction model
Yu Xin, Wu Minghui
(Computer and Computing Science School, Zhejiang University City College, Hangzhou 310015, China)
Abstract: Web pages contain large amount of heterogeneous semi-structured or unstructured data, and how to accurately extract valuable information from web pages is extremely important. With the help of deep learning, this paper proposes a new BERT+BiLSTM+CRF information extraction model. The experimental results show the effectiveness of the proposed method.
Key words: deep learning; information extraction model; Web; BERT+BiLSTM+CRF
0 引言
伴隨着互联技术的迅猛发展,网上的数据总量呈指数增长。互联网Web网页中的海量数据包含了大量有价值的信息。因此,如何准确地从网页中抽取有价值的信息变得越来越重要。然而,由于不同网页的结构差异和数据格式不同,大多数网页都显示半结构化或非结构化的数据。如何有效地从网页中提取所需信息一直是互联网数据处理行业的关键问题之一。
信息抽取是自然语言处理领域的一个子领域。近年来,深度学习也在被大量应用到自然语言处理(NLP)相关领域,并取得了重大突破。使用深度学习的方法,可以自动地学习合适的特征与多层次的表达与输出。
本文提出了一种基于深度学习的BERT+BiLSTM+CRF的Web信息抽取模型,并在高校教师的个人主页信息抽取中得到应用。
1 Web信息抽取模型及实现
1.1 模型概况
首先通过网络爬虫获取教师个人主页内容,对内容按一定规则进行处理,对部分教师简介的标记,制作成训练集和验证集,经过深度学习模型训练,实现自动对同类型的其他Web页面进行结构化目标信息抽取。
图1是一个非结构化的教师个人主页简介,页面中目标信息字段有教师姓名,性别,职务,学历,人才层次,荣誉和获得奖励等。目标是将这些目标信息准确地提取出来。
1.2 数据预处理和实体定义
通过网络爬虫抓取数据之后需要对数据预处理,去除文本中大量无意义的空格和空行。将文本按句划分,每句一行,长度不超过LSTM设置的最大长度。
下一步进行数据标注。通过标注数据明确哪些信息需要被抽取和数据之间的联系,构建出用于模型训练的数据集。
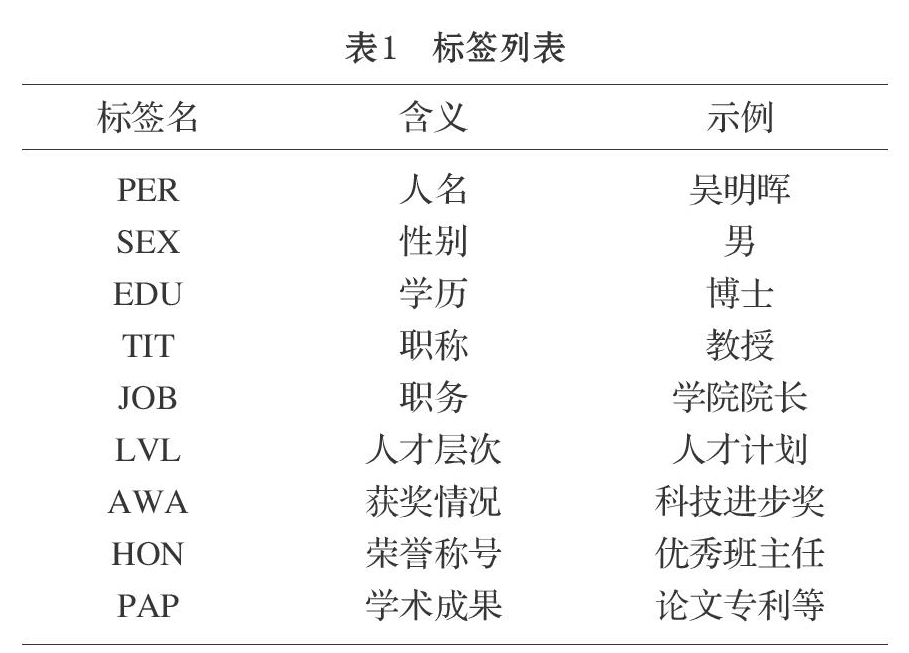
本文使用BIO标注:将每个字标注为“B-X”、“I-X”或者“O”。其中,“B-X”表示该字是实体X的开头,“I-X” 表示该字是实体X的中间部分,“O”表示不是需要识别实体。例如:教授标记为“教 B-TIT 授 I-TIT”。具体实体标签定义见表1。待抽取网页如图1。
1.3 模型构建
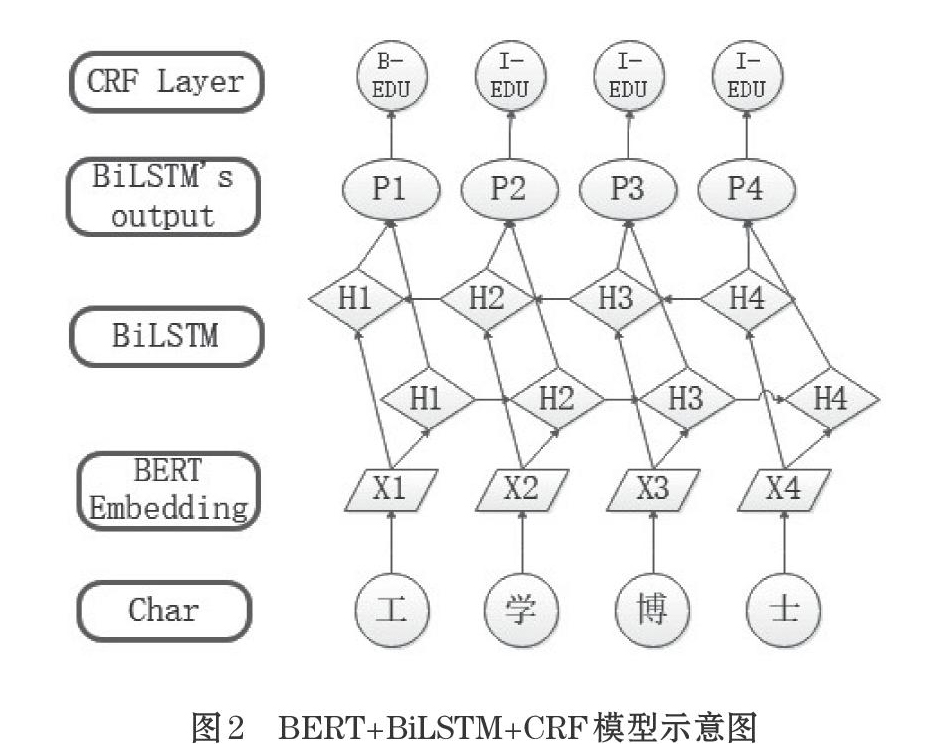
所构建的BERT+BiLSTM+CRF模型,包括一个BERT Embedding层,一个BiLSTM层和一个CRF层,模型结构如图2所示。
⑴ BERT Embedding层,将输入的句子通过Tokenize转化成数字id,输入BERT Embedding层提取特征,生成输入向量。BERT是Devlin等人提出了一种新语言表示模型[1],其目标是通过联合调节所有层中的左右上下文来预训练深度双向表示。在实际使用中需要一个额外的输出层来微调预先训练的BERT表示。
⑵ BiLSTM层,输入为了BERT Embedding层生成的输入向量。将向量序列一个向前的LSTM和一个向后的LSTM,把这两个LSTM在隐藏层进行拼接成为BiLSTM[2],经过全连接输出一个长度为标签数量的一个向量。BiLSTM综合考虑了过去的特征(正向过程提取)和未来的特征(逆向过程提取),避免了仅仅使用单向LSTM在对语句进行建立模型时会遇到无法获取从后到前信息的问题,通过BiLSTM可以更好的捕捉双向的语义依赖。
⑶ CRF层,使用crf_log_likelihood对LSTM输出向量进行序列标记,计算标签概率值。因为不同字之间存在相互关联,标记符号之间也会相互作用,比如O后面就不能接I等。CRF[3]可以使用句子级标记信息,并对两个不同标记间的关联进行建模。
2 实验
2.1 模型实现与训练
基于TensorFlow框架对该模型进行了算法实现。
数据集包括2384条句子,按6:4划分成训练集和测试集。参数设置为:单向LSTM 长度为100,BiLSTM的长度为200,LSTM的Cell使用CoupledInputForgetGateLSTMCell[4];学习率为0.001,Dropout為0.5;优化器选择Adam;Batch size为128,在GPU上训练200轮。
2.2 模型应用
训练好模型后,使用该模型来对网页信息进行目标数据抽取,应用案例如图3所示。
2.3 实验结果对比分析
为了验证所提出模型的效果,与一般的BiLSTM+CRF模型[5]进行了对比实验,采用Precision(P)、Recall(R)和F1 Score(F1)作为模型效果评价标准。
模型1为本文所研究的BERT+BiLSTM+CRF模型,模型2为一般的BiLSTM+CRF模型。在模型2中没有模型1的BERT Embedding层,而是传统的Char Embedding,字向量使用随机初始化的方式获得。两种模型实验结果如表2所示。
由表2可以看出,除LVL和EDU标签之外,其余7种标签在BERT+BiLSTM+CRF模型中F1值更高,且EDU标签F1值相差仅1.02%。整体上使用Bert模型能够有效提高信息抽取率,F1整体提高约3%。
3 结束语
本文提出了一种基于深度学习的BERT+BiLSTM+CRF的Web信息抽取模型,并使用TensorFlow框架和BERT对该模型进行了算法实现。通过实验对比分析,验证了模型的有效性,并在高校教师个人主页信息抽取中得到了实际应用。
参考文献(References):
[1] Devlin J,Chang M,Lee K,et al. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.2018.
[2] Hochreiter S,Schmidhuber J.Long short-term memory[J]. Neural Computation,1997.9(8):1735-1780
[3] Lafferty J D,Mccallum A,Pereira F,et al.Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data[C].international conference on machine learning,2001: 282-289
[4] Greff K,Srivastava R K,Koutnik J,et al. LSTM:A Search Space Odyssey[J]. IEEE Transactions on Neural Networks. 2017.28(10):2222-2232
[5] Huang Z, Xu W, Yu K. Bidirectional LSTM-CRF models for sequence tagging[J].arXiv preprint arXiv:1508.01991, 2015.
- 乡村振兴战略下城郊农村“三变”改革的探索与实践
- 结构功能主义视角下供销社在农村中的作用
- 国内外发展经验对江西省“一村一品”产业发展的启示
- 南疆深度贫困地区相对贫困治理路径研究
- 亳白芍产业发展路径研究
- 四川省古树名木智慧管理系统设计的思考与建议
- 英国奶业发展现状及与中国的合作展望
- 基于“互联网+”的自然资源利用监测模式研究
- 山东省国土空间总体规划基数转换方法研究
- 盐池县特色产业扶贫模式及其成效分析
- “互联网+”背景下云南省腾冲市核桃产业发展对策研究
- 都市特色农业高质量发展对策研究
- 发展农村电商打赢精准脱贫攻坚战
- 村域乡村振兴评价指标体系构建
- 5TG-100A型油菜脱粒机结构设计
- 宁夏引扬黄灌区密植作物小麦滴灌带合理设计及布设参数优化
- 北斗导航系统在全国第三次国土调查中的应用
- 饲料中莫昔克丁的含量测定
- 腐霉利在韭菜中残留现状分析及风险评估
- 不同产地烟叶相似性分析
- 蓝莓酵素加工工艺及其优化研究
- 低温慢烤对烟叶品质的影响研究
- 大黄药用牙膏的制备工艺研究
- 加压CO2与热巴氏杀菌对原料乳杀菌效果的对比研究
- 黑曲霉菌发酵产柚苷酶培养基配方的优化研究
- more unheard of
- more unnarrow minded
- more unself possessed
- more unself righteous
- more unself sacrificial
- more unself sacrificing
- more unself sufficient
- more up and coming
- more upside down
- more up to the minute
- more user friendly
- more wafer thin
- more walk up
- more wall to wall
- more warm blooded
- more weather beaten
- more well to do
- more well wishing
- more white collar
- more white hot
- more wide eyed
- more wide ranging
- more willy nilly
- more win win
- more wise guy
- 漂浪
- 漂浮
- 漂浮不定
- 漂浮在水面的冰块
- 漂浮摇摆
- 漂浮的样子
- 漂浮的泡
- 漂浮,漂流
- 漂游
- 漂渺
- 漂溺
- 漂滥
- 漂漂
- 漂漂亮亮
- 漂漂然(飘飘然)
- 漂激
- 漂火头
- 漂点的
- 漂然
- 漂瓤子
- 漂田
- 漂疾
- 漂白
- 漂白布掉在染缸里——一世洗不清
- 漂白粉