韩鲁峰

摘 ?要: 针对传统的网络教学平台选课过程中缺乏个性化推荐的缺点,提出一种基于Mini Batch K-Means算法的课程推荐聚类分析方法,该方法通过对网络教学平台中的课程及学生分别进行聚类分析来实现个性化研究。与标准的K-Means算法相比,Mini Batch K-Means算法选取小批量的数据子集,从而加快了计算速度, 减少了k均值的收敛时间。文章通过一个实例说明了该方法在面对海量的网络数据时,能够更高效地实现选课过程中的课程个性化推荐。
关键词: 数据挖掘; K-Means; 个性化; 教学平台
中图分类号:TP399 ? ? ? ? ?文献标识码:A ? ?文章编号:1006-8228(2020)01-84-03
Abstract: Aiming at the shortcomings of traditional network teaching platform that lacks personalized recommendation, this paper proposes a clustering analysis method based on Mini Batch K-Means algorithm. The method realizes individualized research by clustering the courses and students in the network teaching platform. Compared with the standard K-Means algorithm, Mini Batch K-Means algorithm selects small subsets of data, which speeds up the calculation and reduce the convergence time of K-Means. This paper illustrates an example that can effectively implement the personalized recommendation of the courses during the course selection process in the face of massive network data.
Key words: data mining; K-Means; personalize; teaching platform
0 引言
随着互联网与教育事业的日益融合及发展,网络化教学已经成为当今教育发展新的生长点和现代教育技术主流的发展方向。当前的网络教学还普遍存在教学模式单一、教学资源简单累积、智能化程度低等问题,而使用教学平台的学生学习能力、个人兴趣、学习基础,都存在着巨大的差异[1]。由此带来的是网络教学平台不能适应学习者个性化需求的矛盾。
为了解决上述矛盾,本文将数据挖掘技术应用于高校的教育教学, 开发个性化的网络教学平台,针对不同学生的学习需求以及学习风格对学生进行个性化推荐,从而有效的提高教学质量。
1 数据挖掘
1.1 数据挖掘概念
数据挖掘是数据库知识发现过程中的一个步骤[2]。WEB数据挖掘大致分为三类:内容挖掘、结构挖掘、用户使用记录挖掘。将Web数据挖掘应用于网络教学平台,对教学数据库中的大量数据进行抽取、转换、分析和模型化处理,使网络教学平台更加规范化、个性化、智能化。以此帮助我们在教育教学,课程制定和创新型人才的培养等方面进行有效的決策[3]。
1.2 聚类算法
最早的聚类思想出现在我国的《战国策 齐策三》中,即“物以类聚,人以群分”。聚类是将数据划分为若干组的过程,并使得同一个组内的数据对象之间相似度越高越好,而不同组中的数据对象之间相似度越低越好[4]。
根据聚类算法所采用的基本思想,可以将聚类算法分为以下四类:层次聚类算法、分割聚类算法、基于约束的聚类算法、机器学习中的聚类算法。本文采用的Mini Batch K-Means算法是K-Means算法的改进版,K-Means算法是分割聚类算法的一种,是解决聚类问题的一种经典方法。Mini Batch K-Means算法在求解稳定的聚类中心时,每次随机抽取一批数据,然后进行K-Means计算,直至中心点稳定之后,再将所有的数据依据这些中心点进行分类,从而达到和K-Means一样的效果,同时又大大的减少了计算量。
1.3 K-means算法的原理
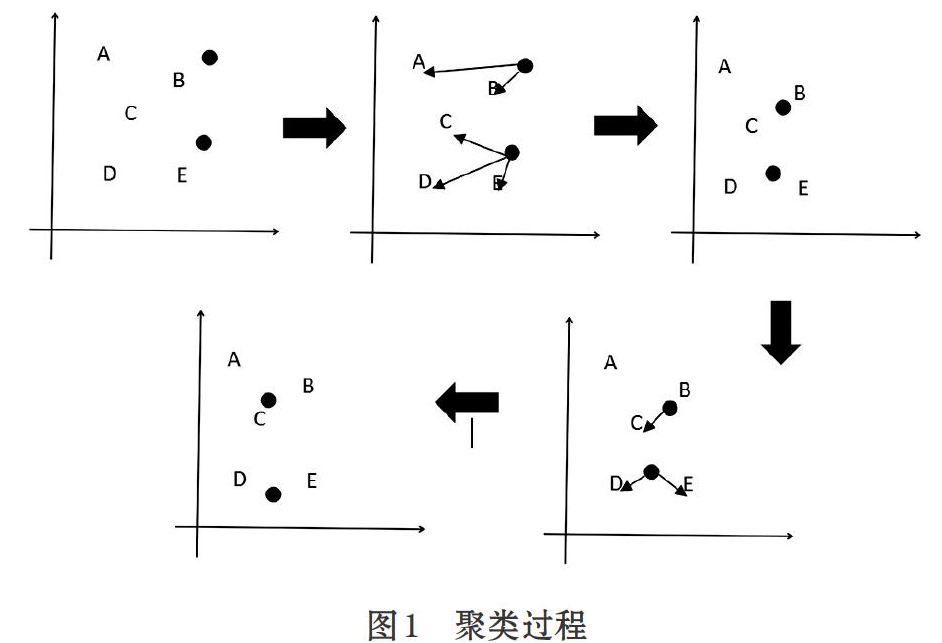
K-means算法是最常用的聚类算法,整个聚类过程如图1所示,假如我们在坐标轴中存在A,B,C,D,E五个点,然后我们初始化两个中心点,也就是将五个点分成两个类。采用欧式距离计算距离,把每个点分到离其最近的中心点所代表的类中。所有点分配完毕后,根据一个类内的所有点重新计算该类中的中心点。然后迭代分配点和更新中心点的步骤,直至中心点的变化很小或达到指定的迭代次数[5]。
2 聚类算法在个性化网络教学平台的应用
信息技术和教学技术的发展,促进了网络教学平台的诞生,目前国内的网络教学平台只实现了网络资源的共享以及学生学习时间和空间的灵活性,个性化教学环节还很薄弱。个性化推荐的实质是将学生信息与系统中的模型进行匹配,寻找具有相同或相近兴趣的学生,然后相互推荐浏览过的信息。个性化推荐服务已经应用于很多领域,并取得了惊人的效果。将个性化推荐服务应用于网络教学平台能够有效解决学生面对海量资源“迷航”的情况,由此减少学生寻找资源所需的时间,从而提高学习效率。
2.1 聚类算法设计
本文选用Mini Batch K-Means算法进行个性化选课推荐。
2.1.1 算法用到的公式
假定给定数据样本X,包含了n个对象X={X1,X2,X3,…,Xn}。其中每个对象都具有m个维度的属性。K-means算法的目标是将n个对象根据对象间的相似性聚集到指定的k个类簇中,每个对象属于且仅属于一个其到类簇中心距离最小的类簇中。
2.1.2 算法的主要过程
算法:改进的K-means算法(Mini Batch K-Means算法)
输入:包含n个学生对象,m条课程对象,聚类个数k1=k2=3
输出:k个聚类及其中心
主要步骤:
⑴ 随机抽取100个有效样本;
⑵ 初始化k个聚类中心;
⑶ 计算出每个对象到这k个中心的距离,如果Xi(1≤i≤n,1≤i≤m)这个对象跟kj(1≤j≤3)这个中心的距离最小,那么Xi属于kj这个中心。这样即可得到初步的k个聚类及聚类中心;
⑷ 根据第二步得到的每个聚类分别计算新的聚类中心,和第二步得到的聚类中心对比,如果不同,则继续第二步,如果相同,则继续第一步,直到聚类中心变化不大。
⑸ 将所有的样本根据中心点进行分类。
2.2 个性化课程推荐的数据挖掘实现过程
个性化推荐服务可以根据学生的个人基本信息、已选的课程、查询的课程、活跃度等,制定课程推荐策略。本文使用Mini Batch K-Means聚类算法对课程和学生分别进行聚类并做进一步的数据挖掘与分析。
2.2.1 课程聚类
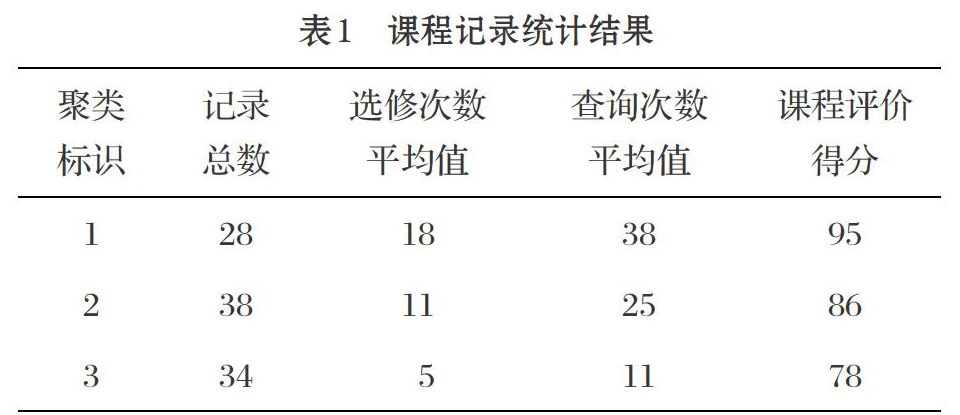
根据课程的部分属性进行聚类分析,用以得到课程的热门程度。首先,进行数据预处理。根据需要,从教学数据库中选择2018年信息工程方向的课程信息表、学生选课信息表,将两张表进行关联生成新表,再从新表中随机各抽取100条记录,从课程年度被选修的次数、课程年度被查询的次数、课程年度评价得分三个角度对记录进行聚类分析得到表1,根据分析结果来划分课程的热门程度。其次,进行数据清洗。删除掉异常数据记录或是数据有缺的记录。最后,对统计结果进行聚类挖掘得到表2。本文设置聚类个数K值为3,分别代表热门课程(聚类标识为1)、一般课程(聚类标识为2)、冷门课程(聚类标识为3),对清洗过后有效的数据进行聚类。
分析表1、表2的结果,可以得出以下结论:从课程的被选次数及被查询次数来看,顺应当前大数据时代的课程比较热门,综合了金融和IT 的课程相对热门,可考虑增设此类相关课程。此处的数据分析只选取了信息工程方向相关课程,其他方向的课程可以用同样方法进行聚类分析和挖掘。
2.2.2 学生聚类
首先,进行数据预处理。根据需要,从教学数据库中选择2018年信息工程方向的学生信息表、学生选课信息表,将两张表进行关联生成新表,再从新表中随机各抽取100条记录,从学生对资源访问的次数、访问持续的时间、发帖回帖的次数三个方面对记录进行聚类分析得到表3,并根据分析结果来划分学生类别。其次,进行数据清洗。清理掉异常的数据记录和数据有缺失的记录。最后,对统计结果进行聚类挖掘得到表4。本文设置聚类个数K值为3,分别代表活跃学生(聚类标识为1)、普遍学生(聚类标识为2)、消极学生(聚类标识为3),对清洗过后有效数据进行聚类。
2.2.3 个性化课程推荐及推荐结果评估
以信息工程方向的学生选课情况和查询数据作为验证,出现在选课和访问查询数据中的学生共1046條,这些学生中共有405人选修或查询过推荐的课程,推荐成功率为38.72%。
3 结束语
在“以学生为中心”的教育背景下, 只有提高网络教学平台的智能性,才能更好地为各种学生群体提供有针对性的服务,真正达到因材施教的目的[6]。本文将数据挖掘技术中的Mini Batch K-Means聚类算法应用于个性化课程推荐服务,从根本上改变了网络教学平台的服务方式,学生从只能“大海捞针”式选课转变为可根据个人需求及平台提供的个性化推荐服务进行选课,提高了学生的满意度和网络资源的利用率,使网络教学平台更加规范化、个性化、智能化。由于选取数据的学校是财经类院校,可能对聚类结果有一定的影响,后期可以选取综合性高校进行分析,提出更有效的改善网络教学平台的办法。
参考文献(References):
[1] Xu Rui. Survey of clustering algorithm[J].IEEE Tran on Neural Networks,2005.16(3):645-678
[2] 金阳,左万利.一种基于动态近邻选择模型的聚类算法[J].计算机学报,2007.30(5):756-762
[3] 倪巍伟,陈耿,吴英杰.一种基于局部密度的分布式聚类挖掘算法[J].软件学报,2008.19(9):2339-2348
[4] 潘小凤.基于聚类算法的图书馆书目推荐服务[J].图书馆学刊,2013.11(12):109-111
[5] C.Romero,S.Ventura.Educational data mining:A survey from 1995to 2005[J].Expert Systems with Applications,2007.33:135-146
[6] 张胜.数据挖掘中聚类算法的研究[J].软件导刊,2008.6(7):66-67
- 当前农村社区的情感状态研究
- 城乡养老社会保险制度一体化障碍性因素分析
- 大学生公益实践与专业特色相结合的创新路径研究
- 校企共育、学践结合模式下建档立卡贫困生创新创业能力提升路径
- 大数据云计算背景下保护个人隐私信息的重要性及安全协同保护机制的研究
- 浅析会计电算化的内涵及其特征
- 政府会计制度下高校固定资产的核算管理
- 浅议我国国有能源企业财务管理问题与对策
- 试析铁路集团公司会计核算存在的问题及建议
- 全面预算管理在医院财务内控中的运用
- 科研事业单位会计信息化建设存在的问题及对策研究
- 新时期企业会计内部控制的问题及处理对策研究
- 行政事业单位会计信息化建设研究
- 差额拨款事业单位财务管理水平提升的探析
- 论新行政事业单位会计核算的内涵及相关影响
- 浅析新时代背景下财务会计向管理会计转型战略研究
- 建筑施工企业财务风险控制与防范研究
- 新《政府会计准则》实施后事业单位固定资产的核算与管理
- 基于反腐的会计监管机制建设
- 中小企业财务内部控制存在的问题及对策
- 财务共享模式下财务管理的思考
- 内部审计视角下的企业应收账款管理
- 期货公司财务现状分析及改进建议
- 论企业财务管理信息化建设问题
- 会计估计变更与前期差错更正的区别探析
- unignitable
- unignited
- unigniting
- unignominious
- unignominiously
- unignominiousness
- unignominiousnesses
- unignorable
- unignorably
- unignorant
- unignorantly
- unignored
- unignoring
- unilabiate
- unilamellar
- unilateral
- unilateral contract
- unilateralcontract
- unilateralities
- unilaterality
- unilaterally
- unillumined
- unillusory
- unillustrative
- unillustrious
- 早就有心
- 早就有此愿望
- 早就有谱了
- 早就看透是什么货
- 早就看透是什么货啦
- 早就被鞭炮吓破了胆
- 早岁
- 早岁哪知世事艰
- 早岁那知世事艰
- 早已
- 早已仰慕
- 早已去世
- 早已料到
- 早已经
- 早已该死
- 早市
- 早年
- 早年间
- 早彩
- 早恋
- 早惠
- 早慧
- 早慧的儿童
- 早成
- 早成功