李书钦 刘召 史运涛


摘? 要: 针对食品安全领域案件高发的突出问题,采用条件随机场模型对食品安全裁判文书的命名实体进行识别。基于HanLP平台和引入自定义词典,识别裁判文书中的人名、地名、机构名、食品、毒害物、危害后果等命名实体,取得了较好的识别效果。实验结果表明,基于条件随机场模型的命名实体识别方法是有效的,有助于自动识别食品安全裁判文书中的相关实体,构建食品安全知识图谱。
关键词: 食品安全; 裁判文书; 条件随机场; 命名实体识别
中图分类号:TP391.1? ? ? ? ? 文献标识码:A? ? ?文章编号:1006-8228(2020)10-01-03
Abstract: Aiming at the prominent problem of high incidence of cases in the field of food safety, the conditional random field model is adopted to identify named entities of food safety judgment documents. Based on HanLP platform, the custom dictionary was introduced to identify the person name, place name, organization name, food name, poison content and harmful consequences, and other named entities in the food safety judgment documents, which achieves good recognition effect. The experimental results show that the named entity recognition method based on conditional random field model is effective, which can help to automatically identify the related entities in the food safety judgment documents and construct the food safety knowledge graph.
Key words: food safety; judgment document; conditional random field; named entity recognition
0 引言
在命名實体识别研究领域,徐飞等[1]根据食品安全事件语料库,构造内部和外部特征模板,实现了人名和机构名两类命名实体的识别。唐钊[2]基于条件随机场模型,通过二次识别,解决了上下文环境中的人名识别问题。张剑[3]等用自定义标注集对农业命名实体进行标注,通过ICTCLAS分词系统进行分词,添加多种特征提高了识别率。张华平等[4]采用Viterbi算法进行模式匹配和角色标注,实现了真实语料库中的中国人名识别。俞鸿魁等[5]采用层叠隐马尔科夫模型,识别出大规模真实语料库中的人名、地名和机构名。郭剑毅等[6]基于层叠条件随机场模型,结合旅游景点常用特征词典和复杂特征,实现旅游领域景点、特产风味和地点的识别,相比HMM模型,具有较高的正确率和召回率。叶枫等[7]利用条件随机场工具CRF++,以词性、词边界、构词特征、上下文等为特征集,对中文病历中的疾病、临床症状和手术操作三类命名实体进行识别,取得了良好效果。杨锦锋等[8]构建了中文电子病历标注语料库,用于电子病例命名实体识别,对于个性化医疗服务和临床决策支持具有重要意义。鞠久朋等[9]提出一种CRF与规则相结合的方法,识别地理空间中的地名及机构名,具有较高的识别准确率。
2014年1月1日,《最高人民法院关于人民法院在互联网公布裁判文书的规定》正式实施,覆盖民事、刑事、赔偿、执行等不同案件类型的裁判文书在互联网公开。本文拟面向食品安全裁判文书,识别其中的人名、地名、机构名、食品、毒害物、危害后果等命名的实体,对食品安全案件的预测预警和情报分析提供参考,显著提升针对食品犯罪活动的主动发现能力。
1 命名实体识别
命名实体识别(Named Entity Recognition,NER)是自然语言处理中重要的预处理模块,是机器翻译、句法分析、信息抽取等任务的基础。MUC-7(The Seventh Message Understanding Conferences)会议将命名实体细化为7类:人名(Person)、地名(Location)、机构名(Organization)、日期(data)、时间(time)、百分数(percentage)、金额(monetary value)等。中文命名实体识别的核心在于确定文本中命名实体的边界,由于中文不同于西方语言,没有明确的词语边界,不具备良好的字形特征,在实体词之间,实体词与非实体词之间存在边界模糊等问题,使得中文命名实体识别难度较大。
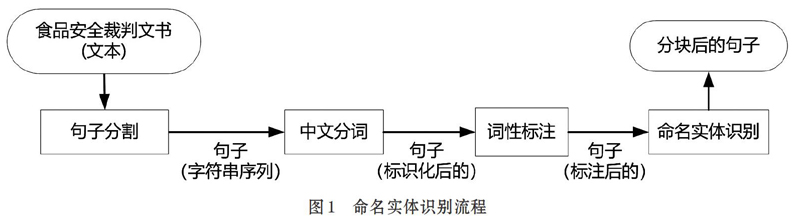
本文从食品安全裁判文书中,快速、准确地识别相关命名实体,先提取人名、地名、组织机构名,比如人名实体包括:原告、被告、法官、委托代理人等;组织机构名主要指与案情相关的机构,如公安机关、法院、律师事务所等;地名实体用来表达案发地点。由于面向食品安全领域,在对通用的命名实体进行识别之后,还需识别食品、毒害物、危害后果等命名实体。本文采用的命名实体识别流程如图1所示,首先对食品安全裁判文书中的文本进行句子分割,得到字符串序列,然后进行中文分词,得到标识后的句子,接着进行词性标注,返回标注后的句子,在此基础上,进行命名实体识别,最终得到分块后的句子,即命名实体。
2 基于条件随机场的命名实体识别
条件随机场CRF(Conditional Random Fields)是一种无向图模型,在给定输入结点值时,计算指定输出结点值的条件概率,该模型有效地解决了隐马尔科夫模型的独立性假设、基于最大熵的马尔科夫模型标记偏执等问题,在分词和命名实体识别领域有较高的识别率。CRF采用基于序列标注的机器学习方法,主要涉及中文分词、词性标注、训练语料生成、特征定义和模型训练。
则称[P(Y|X)]为线性链CRF。在标注问题中,[X]表示输入观测序列,[Y]表示对应的状态序列或输出标记序列。已知训练数据集,线性链CRF可通过极大似然估计得到条件概率模型。CRF通过定义权重系数和特征函数转化为机器學习问题,具有如下形式:
其中,[P(y|x)]表示某个标签序列的概率,[λa]和[μb]表示对应特征函数的权重参数,[ta]代表定义在[Y]节点上下文的特征函数,[Sb]为定义在[Y]节点上的特征函数[10]。CRF的预测问题是在给定[P(Y|X)]和输入序列[x]的前提下,求条件概率最大的输出序列[y*]。CRF预测算法如下所示。
3 实验结果与分析
本研究从无讼网公开的裁判文书中,下载3000余份食品安全相关文书,使用语言技术平台HanLP[11]进行分词、词性标注及命名实体识别处理,与名词实体相关的HanLP词性标注集如表1所示。
以裁判文书文本“2017年1月19日,被告人王从华在萧县文化路某排档卤制羊蹄时添加了过量的亚硝酸盐。被害人金某食用后发生中毒。被告人王从华于2017年3月15日17时许到萧县公安局投案。”为例,分词结果为“2017/m,年/qt,1月/t,19/m,日/b,,/w,被告人/n,王从华/nr,在/p,萧县/ns,文化路/ns,某/rz,排档/nz,卤制/n,羊蹄/nz,时/qt,添加/v,了/ule,过量/vi,的/ude1,亚硝酸盐/n,。/w,被害人/n,金某/nr,食用/vn,后/f,发生/v,中毒/vi,。/w,被告人/n,王从华/nr,于/p,2017/m,年/qt,3月/t,15/m,日/b,17/m,时许/nr,到/v,萧县公安局/nto,投案/vi,。/w”。统计出的命名实体如表2所示。
参考一系列食品安全国家标准(GB 2760-2017,GB 2761-2017等),收集整理食品词典共370个词,毒害物词典320个词,危害后果词典30个词,将上述词典增加到HanLP平台的自定义词典中,重新分词,结果为“/w,2017/m,年/qt,1月/t,19/m,日/b,,/w,被告人/n,王从华/nr,在/p,萧县/ns,文化路/ns,某/rz,排档/nz,卤/n,制/v,羊蹄/food,时/qt,添加/v,了/ule,过量/vi,的/ude1,亚硝酸盐/poison,。/w,被害人/n,金某/nr,食用/vn,后/f,发生/v,中毒/consequence,。/w,被告人/n,王从华/nr,于/p,2017/m,年/qt,3月/t,15/m,日/b,17/m,时许/nr,到/v,萧县公安局/nt,投案/vi,。/w”。自定义词典识别出的命名实体为:食品/羊蹄,毒害物/亚硝酸盐,危害后果/中毒。
从以上结果可以看出,默认情况下,HanLP平台将食品“羊蹄”识别为“其他专名”,将毒害物“亚硝酸盐”识别为“名词”,将危害后果“中毒”识别为“动词”。在加入自定义词典后,将“羊蹄”识别为“食品名称”,将“亚硝酸盐”识别为“毒害物名称”,将 “中毒”识别为“危害后果”,模型对食品安全相关命名实体的识别效果也有了相应的提高。
4 结束语
本研究采用基于条件随机场的命名实体识别方法,以无讼案例网中3000余例食品安全裁判文书为数据样本,进行自然语言分析,实现了非结构化文本数据中关键命名实体(人名、地名、组织机构名、食品、毒害物、危害后果)的提取,取得了比较好的效果,对于食品安全相关案件的犯罪预测预警,具有重要的理论和实践意义。下一步,在命名实体识别的基础上,继续研究食品安全实体关系抽取,进而构建食品安全知识图谱。
参考文献(References):
[1] 徐飞,宋英华.海量食品安全事件下的命名实体识别研究[J].科研管理,2018.39(7):131-138
[2] 唐钊.条件随机场模型在中文人名识别中的研究与实现[J].现代计算机(专业版),2012.21:3-7
[3] 张剑,吴青,羊昕旖等.基于条件随机场的农业命名实体识别[J].计算机与现代化,2018.1:123-126
[4] 张华平,刘群.基于角色标注的中国人名自动识别研究[J].计算机学报,2004.1:85-91
[5] 俞鸿魁,张华平,刘群等.基于层叠隐马尔可夫模型的中文命名实体识别[J].通信学报,2006.2:87-94
[6] 郭剑毅,薛征山,余正涛等.基于层叠条件随机场的旅游领域命名实体识别[J].中文信息学报,2009.23(5):47-52
[7] 叶枫,陈莺莺,周根贵等.电子病历中命名实体的智能识别[J].中国生物医学工程学报,2011.30(2):256-262
[8] 杨锦锋,关毅,何彬等.中文电子病历命名实体和实体关系语料库构建[J].软件学报,2016.27(11):2725-2746
[9] 鞠久朋,张伟伟,宁建军,等.CRF与规则相结合的地理空间命名实体识别[J].计算机工程,2011.37(7):210-212,215
[10] 李航.统计学习方法[M].清华大学出版社,2012.
[11] https://github.com/hankcs/HanLP.
- 中小民营企业资金管理存在的问题及对策探析
- 粉丝经济的现状与发展前景
- 基于动态条件得分模型的风险测度和MCS检验
- 特色小镇创新融资模式解读
- 大学生创业融资现状与策略研究
- 基层央行青年人才培养和发展探析
- OA系统在科学事业单位科研经费管理创新运用研究
- 2015-2017年Y保险昆明分公司车险人伤案件理赔状况及对策研究
- P2P平台融资问题的探析
- 基于ERP系统环境下的出版企业内部控制研究
- 在低利率时代,中央银行如何促进经济可持续发展?
- 美国EESA法案系统性金融风险处置的反思与启示
- 杠杆率上涨的内在机理
- 山东资本市场改革历程及展望
- 通货膨胀惯性对货币政策调控效果有影响吗?
- 绿色发展理念下长江经济带自然资源资产离任审计体系研究
- 吉林省科技文献信息服务平台网站建设概述
- 人口老龄化背景下人寿保险未来发展战略分析
- 高管激励对创新绩效影响的研究综述与展望
- 预算管理的刚性柔性在企业中的作用运用
- 对钢铁企业集团资金集中管理推行财务公司运作的探讨
- 我国电子商务平台企业的市场集中度分析
- 在校学生商品消费观念问题及转变策略
- 刍议新医改政策下公立医院绩效考核与薪酬的设计
- 我国P2P平台网贷成功率影响因素的实证分析
- detachedly
- detachedness'
- detachedness
- detachednesses
- detachedness's
- detacher
- detachers
- detaches
- detaching
- detachment
- detachments
- detach (sth) (from sth)
- detail
- detailed
- detailedly
- detailedness'
- detailedness
- detailednesses'
- detailednesses
- detailedness's
- detailer
- detailers
- detail's
- details
- detail²
- 拳头商品
- 拳头大是哥哥,个头壮是强梁
- 拳头对拳头,木棒对木棒
- 拳头打不着跳蚤
- 拳头打在棉花上
- 拳头打在海绵上——没有反应
- 拳头打跳蚤
- 拳头捣大蒜——辣手
- 拳头捶辣椒
- 拳头文学
- 拳头朝外打,胳膊往里弯
- 拳头朝外打,胳膊朝里弯
- 拳头熟不如人头熟
- 拳头砸核桃
- 拳头砸跳蚤——有劲使不上
- 拳头硬的是大哥
- 拳头舂青椒——辣手
- 拳头该藏在袖子里
- 拳头里伸出巴掌——不防这一手
- 拳头里攥着两把指甲
- 拳头难落笑人面
- 拳头项目
- 拳局
- 拳师教徒弟
- 拳手