摘 要: 大型计算机网络中的各种软件和设备均存在安全漏洞,导致以往提出的大型计算机网络中非正常数据挖掘方法无法进行合理挖掘。针对该问题,提出一种新型的大型计算机网络中非正常数据挖掘方法。所提方法通过数据洗涤、格式变换和模式挖掘等操作,挖掘出大型计算机网络中的非正常数据。使用所提方法设计的数据挖掘系统由数据挖掘器、分析模块和数据库组成,数据库为数据挖掘器和分析模块提供处理和挖掘方案。数据挖掘器实时监控着大型计算机网络中的非正常情况,并进行数据处理。分析模块使用“二次激活”方式对处理过的数据进行分析,挖掘出其中的非正常数据。实验结果表明,所提方法具有较好的收敛性,所设计的系统具有较强的可扩展性。
关键词: 大型计算机网络; 非正常数据; 数据挖掘技术; 合理挖掘
中图分类号: TN711?34; TP393.08 文献标识码: A 文章编号: 1004?373X(2017)12?0059?04
Abstract: Various softwares and equipments in large?scale computer networks have security holes, which lead to the previously?proposed abnormal data mining methods in large?scale computer networks can′t make reasonable mining. Therefore, a new abnormal data mining method in large?scale computer network is put forward. The method can mine the abnormal data in large?scale computer network by data washing, data format conversion and pattern mining operation. The data mining system designed with the proposed method is composed of data mining processor, analysis module and database. The database provides the processing and mining schemes for data mining processor and analysis module. The data mining processor is used to monitor the abnormal situation in large?scale computer network in real time, and carry out data processing. The analysis module is used to analyze the processed data by means of "secondary activation" mode, and dig up the abnormal data. The experimental results show that the proposed method has good convergence, and the system designed with the method has strong scalability.
Keywords: large?scale computer network; abnormal data; data mining technology; reasonable mining
0 引 言
随着电子信息技术的普及和不断发展,大型计算机网络随之产生,越来越多的网民能够更为便捷地享受各种信息资源,现如今,网络已成为人们生活中不可缺少的一部分。大型计算机网络在为人们提供便利的同时,也造成了一定的困扰,网络入侵事件时有发生[1]。若想有效维护大型计算机网络安全,需要将其中的非正常数据准确、高效地挖掘出来,相关组织已开始着手进行大型计算机网络中非正常数据挖掘技术的研究工作[2]。
1 非正常数据挖掘技术
数据挖掘技术是指依据特定任务,将重要的隐含知识从具有一定干扰存在下的随机数据集群中提炼出来[3]。数据挖掘技术是一项交汇科目,经其挖掘出来的数据具有一定的辅助决策作用。将这种技术用于进行大型计算机网络非正常数据的挖掘工作中,能够自动控制大量初始数据,为用户提供更多的便利[4]。
所提大型计算机网络中非正常数据挖掘方法的挖掘流程如图1所示。
由图1可知,所提方法先对大型计算机网络中的初始数据集群进行统一处理,处理过程包括数据洗涤和格式变换。数据洗涤的目的是将初始数据集群中的噪音、重叠参数和缺失重要特征的数据除去,再经由格式变换,使洗涤后的数据集群特征更加明显,提高对非正常数据的挖掘准确性。
当数据处理完毕,所提方法随即开始进行模式挖掘。所谓模式挖掘,是指通过对比分析方式获取大型计算机网络中数据之间共有特征的过程,所获取到的共有特征即为数据挖掘技术中的“知识”[5]。
将模式挖掘定义成向的映射,和均是大型计算机网络中初始数据集群的一部分,并且,。在中随机定义一个数据集群,此时可以将和在中出现的几率设为向映射的知识,用表示,则有:
设置和的取值范围可使所提大型计算机网络中非正常數据挖掘方法具有收敛性。若无特殊规定,可将二者的取值范围均设置在0~100%之间。如果用户需要对某一特定的非正常数据进行精准挖掘,也可随时变更取值范围。
取值范围设定成功后,本文将式(1)和式(2)中的重叠部分输出,用来表示大型计算机网络中非正常数据的挖掘结果。
2 非正常数据挖掘系统设计
2.1 系统总体设计
现使用所提大型计算机网络中非正常数据挖掘方法设计数据挖掘系统,以实现对大型计算机网络安全的有效维护。
所设计的系统由数据挖掘器、分析模块和数据库组成,如图2所示。数据挖掘器被安放在大型计算机网络的特定节点上,用来实时监控网络工作的非正常情况,并进行数据处理。分析模块负责对数据挖掘器处理过的数据进行分析,进而挖掘出大型计算机网络中的非正常数据。数据库为数据挖掘器和分析模块提供数据的处理和挖掘方案。
2.2 系统具体设计
在所设计的大型计算机网络非正常数据挖掘系统中,数据挖掘器可看作是大型计算机网络初始数据集群的接收端,用于获取数据挖掘技术中的“知识”,其工作流程如图3所示。
由图3可知,在数据挖掘器开始工作前,数据库会事先根据大型计算机网络初始数据集群的特征制定数据挖掘器的具体挖掘方案,并对其实施驱动。数据挖掘器根据挖掘方案对数据进行洗涤和格式转换等处理。处理结果将被存储。
值得一提的是,数据挖掘器具有自检功能,如果处理结果不符合用户所设定的置信度,那么该结果将会被保留到数据挖掘器的缓存器中。一旦缓存器中有新鲜数据进入,数据库便会重新驱动数据挖掘器,直至处理结果成功通过自检。随后,所设计大型计算机网络中非正常数据挖掘系统的分析模块将对数据挖掘器的处理结果进行分析。为了增强系统的可扩展性,应充分利用系统计算节点的性能,并缩减节点失效率,为此,给分析模块设计出一种“二次激活”方式[6],以延长系统计算节点的使用寿命,如图4所示。二次激活是指当系统计算节点出现疲劳状态时,分析模块将自动放出替补节点,使疲劳节点拥有足够的时间去休整。休整后的计算节点将替换下替补节点,继续进行数据挖掘工作。
在分析模块中,每个计算节点均有多个替补节点,如果节点即将失效并且未能寻找到下一个合适的计算节点,将采取替补节点与性能相似节点同时工作的分析方式,以保证所设计大型计算机网络中非正常数据挖掘系统的可扩展性,并使挖掘结果更加准确。
3 实验验证
3.1 方法收敛性验证
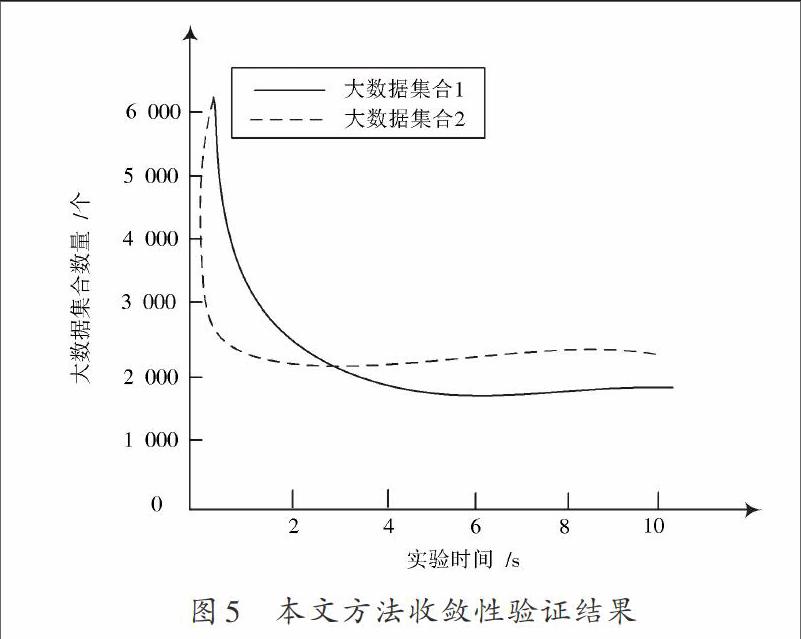
在大型计算机网络中,只有具有较好收敛性的非正常数据挖掘方法才能有效保证挖掘结果的准确性。为了验证本文所提方法收敛性的优劣,需要进行一次实验。本次实验在某大型计算机网络实验室中进行。用于进行数据挖掘的主机配置为:3 GB内存、四核i7处理器、500 GB硬盘。实验中,于主机写入本文方法,并向大型计算机网络中加入两种类型的大数据集群,两集群中的数据节点[7?8]分别为4万个和80万个。当数据节点中的数据不出现波动时,表示本文方法已进入收敛状态,此时主机便不会再向下一节点传递数据。实验结果如图5所示。
从图5可明确看出,本文方法具有收敛性,并且大数据集群中的数据节点越多,方法的收敛时间就越短。在两种大数据集群中,本文方法的收敛时间分别为1.2 s和4.3 s。据统计,其他方法的收敛时间大多在10.8 s左右,这显示出本文方法具有较好的收敛性。
3.2 系统可扩展性验证
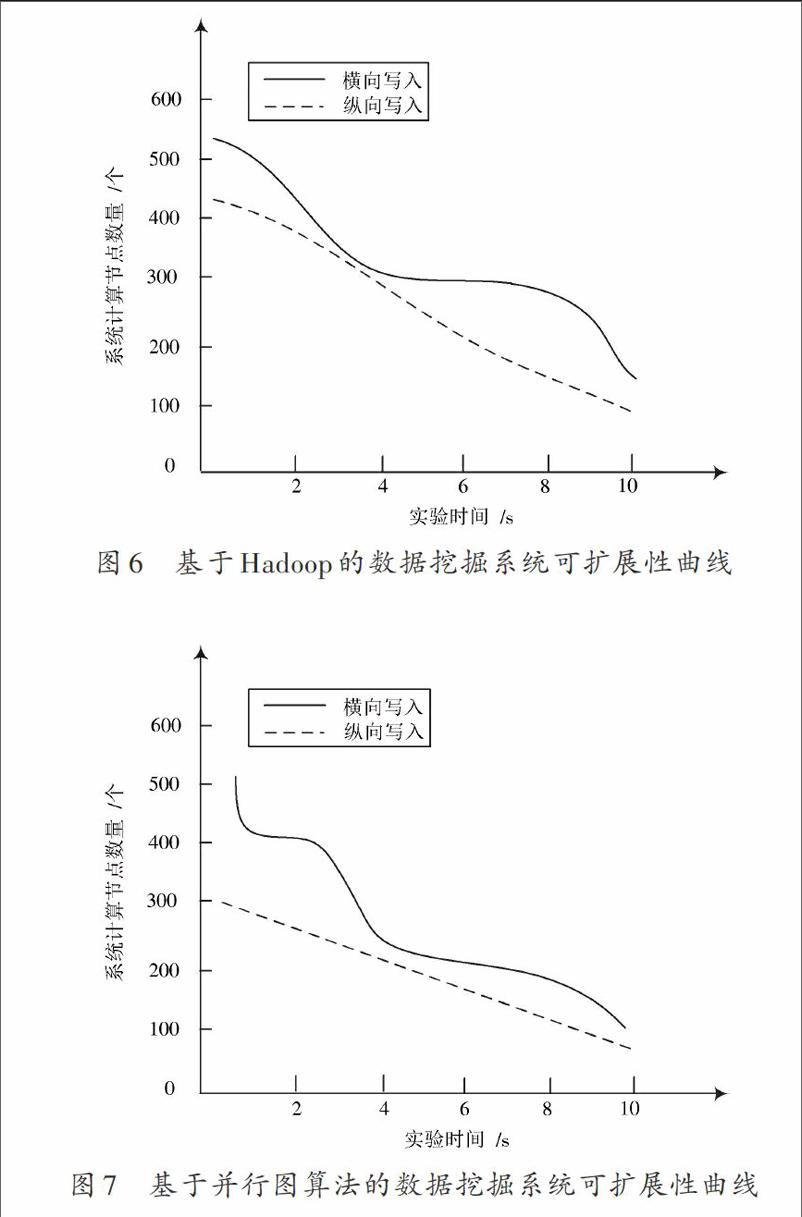
为了验证经本文方法设计出的数据挖掘系统是否能够合理应对大型计算机网络中非正常数据的更新,需要对本文系统的可扩展性进行验证。实验选出的对比系统有基于Hadoop的数据挖掘系统和基于并行图算法的数据挖掘系统。
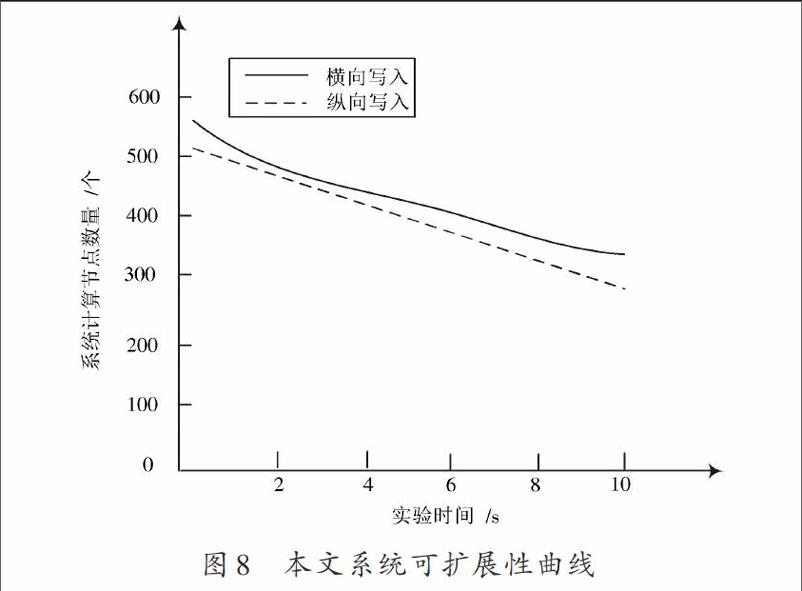
在第3.1节实验的基础上,只保留大数据集群2,并分别以横向和纵向方式向集群的数据节点中随机写入30 000个非正常数据。使用三种系统对大型计算机网络中的非正常数据进行挖掘,所得实验结果如图6~图8所示。
由图6~图8可知,三个系统在纵向写入下的可扩展性均低于横向写入。与其他两个系统相比,本文系统参与进行非正常数据挖掘的节点数量更多,并且节点失效率最少,证明使用本文方法设计出的数据挖掘系统具有较强的可扩展性。
4 结 论
本文提出一种新型的大型计算机网络中非正常数据挖掘方法,并使用该方法设计数据挖掘系统。数据挖掘技术是指依据特定任务,将重要的隐含知识从具有一定干扰存在下的随机数据集群中挖掘出来。将数据挖掘技术用于进行大型计算机网络非正常数据挖掘工作中,能够对大量数据进行自动控制,为用户提供更多便利。实验结果表明,本文方法具有较好的收敛性,使用本文方法设计出的数据挖掘系统也具有较强的可扩展性,可将大型计算机网络中的非正常数据准确、高效地挖掘出来。
参考文献
[1] 吴嘉瑞,唐仕欢,郭位先,等.基于數据挖掘的名老中医经验传承研究述评[J].中国中药杂志,2014,39(4):614?617.
[2] 李善青,赵辉,宋立荣.基于大数据挖掘的科技项目查重模型研究[J].图书馆论坛,2014,34(2):78?83.
[3] 丁骋骋,邱瑾.性别与信用:非法集资主角的微观个体特征—基于网络数据挖掘的分析[J].财贸经济,2016,37(3):78?94.
[4] 杨丹丹.搜索引擎及网络数据挖掘相关技术研究[J].数字化用户,2014,20(11):126.
[5] 王元卓,贾岩涛,刘大伟,等.基于开放网络知识的信息检索与数据挖掘[J].计算机研究与发展,2015,52(2):456?474.
[6] 唐晓东.基于关联规则映射的生物信息网络多维数据挖掘算法[J].计算机应用研究,2015,32(6):1614?1616.
[7] 陈震.对于以数据挖掘为基础的网络学习系统的设计与研究[J].山东农业工程学院学报,2014,31(6):38?39.
[8] 周立军,张杰,吕海燕.基于数据挖掘技术的网络入侵检测技术研究[J].现代电子技术,2016,39(6):10?13.
- 关于中国传统中医药的知识产权保护现状
- 尿毒清颗粒对腹膜透析患者蛋白结合型毒素的影响
- 调肝论治不孕经验探析
- 行为疗法在男科疾病中的应用
- 基于伏邪理论探讨红外热成像技术在健康体检中的应用
- 云南西双版纳地区民间常用雅解及资源调研
- 中西医结合治疗慢性咳嗽风邪伏肺证临床观察
- 运脾汤加减治疗中风后胃肠功能紊乱临床观察
- 痛风消散剂外敷治疗急性痛风性关节炎的疗效观察
- 通络熄风汤治疗缺血性脑卒中急性期患者的临床研究
- 新型冠状病毒肺炎疫情期间尘肺患者的中医防控建议
- 青刺尖中黄酮类成分调节脂代谢作用研究进展
- 从经络腧穴治疗咳嗽的配伍规律研究进展
- 健肝消脂方医院制剂质量标准初步研究
- 补青颗粒对过氧化氢诱导的晶状体上皮细胞氧化损伤的影响
- 对羟基苯甲醛对脑缺血再灌注损伤大鼠皮层区氨基酸类神经递质的影响
- 戴海青教授中西医结合治疗宫腔粘连的经验总结
- 夏惠明教授临证思维探析
- 毕朝忠论治胸痹心痛病经验
- 闫润红从风论治原发性三叉神经痛临床经验
- 参芪扶正注射液对胃癌术后患者代谢状态及免疫功能的影响
- 基于数据挖掘的卢桂梅教授辨治眩晕病用药规律研究
- 通络法治疗化疗相关性手足综合征的临床观察
- 桃核承气汤合甘麦大枣汤加减治疗老年性谵妄临床研究
- 中医延续性护理对提高特发性肺纤维化患者生活质量调查研究
- presymphony
- presymptom
- presymptomatic
- presymptoms
- presystematic
- presystematically
- pretabulate
- pretabulated
- pretabulates
- pretabulating
- pretabulation
- pretabulations
- pretangible
- pretangibly
- pretape
- pretaped
- pretapes
- pretaping
- pretariff
- pretariffs
- pretaste
- pre-taste
- pretasted
- pretaster
- pretasters
- 人多心不齐,鹅卵石挤掉皮
- 人多成王
- 人多成王。
- 人多手杂
- 人多手杂,动作忙乱
- 人多才多艺
- 人多把房盖歪了
- 人多拥挤
- 人多拥挤而嘈杂的样子
- 人多拥挤,场面热闹
- 人多拥挤,往来不断
- 人多无好饭,猪多无好食
- 人多是圣人
- 人多极拥挤的样子
- 人多气势大,力量大
- 人多没好汤,猪多没好糠
- 人多活儿轻,树多好遮荫
- 人多的姓氏
- 人多眼杂
- 人多瞎捣乱,鸡多不下蛋
- 人多而乱
- 人多而乱哄哄的样子
- 人多而公开的场所
- 人多而密集
- 人多而有威仪的样子