张丽萍
〔摘要〕 求解期刊分类大数据自动存储问题时,传统方法在分解的过程中无法保证准确性与合理性,对解的合并策略选择不合理,导致寻优过程中出现一定的偏差,造成期刊分类存储效率大大降低。为此,需要提出一种新的基于群体协同智能聚类的期刊分类大数据自动存储方法。确定径向基神经网络的初始结构,通过样本分布计算径基宽度获取隐节点群,将其当成初始集合。将分类存储精度最高、Fmeasure最大、期刊特征相似性最高作为目标函数,将其加权和作为适应函数。在求解过程中,各子群内部通过模拟退火法将分布估计算法和遗传算法结合在一起,产生新个体,利用群体协同合作的方式实现智能聚类。通过进化获取最优个体,得到最终精英集合,将其看作最后得到的径向基神经网络结构,通过得到的径向基神经网络实现期刊分类大数据自动存储。实验结果表明,所提方法期刊分类大数据存储性能强。
〔关键词〕 群体协同智能聚类;期刊分类;大数据;存储
〔中圖分类号〕TP391〔文献标识码〕A〔文章编号〕1008-2689(2019)02-0067-06
引言
大数据时代,人们接触媒体的成本逐渐减少,网络阅读逐渐变成一种习惯,大部分期刊社均已经进行自助网络出版,期刊数字出版迅猛发展[1][2]。现阶段大部分国内外科研人员早已习惯查看网络数据资源,对纸质期刊的依赖性逐渐降低[3]。随着数字期刊量的迅猛增加,对期刊的准确查询也开始变得越来越困难,需研究一种有效的期刊分类大数据自动存储方法,为大数据查询提供有效的技术支持。
传统期刊分类大数据自动存储方法存在不完善的地方,无法有效反映更加普遍意义的协同思想[4][5]。传统的大数据自动存储方法在分解的过程中无法保证准确性与合理性,而分解不合理,在解的结合过程中将出现很大问题,造成期刊分类存储失败。不仅如此,传统方法对解的合并策略选择不合理,更将会导致合并后解的适应能力差,在寻优过程中出现一定的偏差,使得期刊分类存储效率大大降低。为此,急需发展出一套新的基于群体协同智能聚类的期刊分类大数据自动存储方法。此方法简单说就是,首先将大数据进行人工的分类,来获取期刊分类大数据的样本;然后为了消除多余数据之间存在的可能性的矛盾对样本进行并行聚类,通过FCM算法使得多个进程同时并行完成期刊分类大数据的聚类任务;最后对性能改进型评估,以便聚类方法的性能得到改善,从而实现期刊分类大数据自动存储。
一、? 期刊分类大数据的预处理
本文基于群体协同智能聚类,通过衰减半径聚类法[6]获取径向神经网络初始结构,新添加一个聚类层,也就是通过Kmeans法对已经求出的初始隐层节点聚集在一起,将性质类似的引接点聚集为隐节点群,结合子种群完成进化。
(一)? 隐节点结构与参数的混合编码
依据径向神经网络的结构特点,通过含网络隐节点结构与相关参数矩阵式混合编码形式[7]。与各个体相应的隐节点相应的并非一个隐节点,而是隐节点群。Csk用于描述第k个隐节点群中第s个个体代表的隐节点中心,k用于描述种群量,s用于描述子种群大小。所有Csk都是nk×d+2的矩阵,nk用于描述隐节点群所含的节点数量, d用于描述输入向量维数。通过隐节点与参数的混合编码计算,得rksi=1表示隐节点的存在。
(二) 初始化
聚类中心的主进程初始化主要包括以下几个部分:
首先把期刊样本集合划分为训练集、评价集以及测试集,确定初始隐层节点φj,通过样本空间信息获取λ初始值。其次通过优化的Kmeans法[7]完成对求出隐层节点的聚类处理,产生若干节点。最后针对各隐节点群,通过任意选择的部分隐节点,得到初始群体的个体数,并且使得起作用的隐节点相应的控制分量位rksi=1。
(三) 群体协同智能聚类
在协同进化遗传算法的基础上,结合Pareto支配概念与精英保留策略把协同进化遗传算法引入期刊分类大数据自动存储多目标优化问题的求解中[8]。设置一种外部精英集合,通过拥挤距离提高外部种群的多样性,同时依据聚类思想完成对外部种群的分类处理,对各类构造对应概率模型。在进化时各子群内部通过模拟退火法将分布估计算法和遗传算法结合在一起,产生新个体,然后利用群体协同合作的方式实现智能聚类。
1 父种群生成
本节设置外部精英集合,对当前搜寻的优秀完整个体进行存储,父种群生成过程可描述为:
首先完成对精英集合的聚类处理。假设精英集合被划分成2种聚类,依次针对2种聚类,依据种群1到种群C的顺序,按照不同群的个体,依次构造对应概率模型,使得全部种群向更好的方向进化,优化解集的分布性。对算法截至当前搜寻的优秀解进行保存,避免出现进化倒退的现象。
针对父种群的候选集,从第2代开始,直接从精英集合中选择最优个体形成,所以在进化时,算法一直在优秀种群中完成搜寻,找到更优个体后,对精英集合进行补充。
在进化的初始阶段,精英集合发挥着很大的作用,需通过精英集合构造概率模型,提高种群找到Pareto前沿的速度,并且搜寻到更优个体。然而在初始阶段,精英集合中个体数量不多,需完成对其的扩充,令其可构造概率模型,同时将其看作下一代父种群的候选种群。假设外部集合的最小容量是R,为了形成下一代父种群,外部集合容量需高于子种群规模M。
2 新种群产生
通过基因混合模型形成新的个体。基因混合的基本原理为形成个体的基因源于各种存在差异的算法。
完整个体通过7个个体基因构成,个体基因通过不同算法形成,个体基因通过EDA与GA两种算法结合在一起形成的,其中一部分通过EDA建立的概率模型获取,剩余部分通过GA交叉变异获取。
通过模拟退火法[9]把EDA与GA两种算法结合在一起,在进化的初始阶段,通过EDA的全局搜寻性能获取Pareto前沿,之后,通过GA较差变异在优秀种群中继续搜寻,发挥其局部搜寻能力,保证个体的多样性[10]。首先,EDA算法实现过程如下:
(1) 从种群中任意选取L个优秀群体,对柯西分布函数中的参数进行计算;
(2) 在优秀群体的基础上,通过clayton copula函数的参数估计获取均匀分布的随机序列a;
(3) 按照柯西分布的逆累积分布函数获取相应向量。
其次GA算法实现过程如下:
(1) 运行GA算法40次,获取聚类中心矩阵;
(2) 初始化种群。在针对获取的N个聚类成员,用一个染色体代表一个成员,通过实数编码方式对染色体进行描述;
(3) 针对各聚类成员,按照适应度函数求出其适应度值;
(4) 针对各聚类成员,依据适应度函数值,通过轮盘法判断个体的去留,形成规模一致的新一代种群;
(5) 针对复制形成的新种群,从种群中依据交叉概率与变异概率选择染色体完成交叉和变异处理,得到新种群;
(6) 重复进行上述步骤,直至达到收敛。
在进化时,为了有效均衡EDA和GA算法,通过模拟退火技术,引入尺度因子实现控制。尺度因子的结果数值分为两种条件获取,当t=1时,尺度因子的结果数值即为设定尺度因子上限;当t≠1时,尺度因子的结果数值通过设定尺度因子上限与退火因子的乘积,加上设定尺度因子下限的总和得到。其中退火因子,取值范围是0到1。
均衡合并策略为:将随机数与尺度因子相比,在随机数小于尺度因子的情况下,选用EDA算法,反之,选用GA算法。
二、? 期刊分类大数据自动存储的实现
基于群体协同智能聚类的期刊分类大数据自动存储实现过程如下:
第一,确定径向基神经网络的初始结构。通过样本分布计算径基宽度,完成对初始隐层的聚类处理,获取隐节点群,将其当成初始经营集合。
第二,求出不同子种群的个体适应值,对精英集合进行更新。
第三,通过进化获取最优个体,得到最终精英集合,将其看作最后得到的径向基神经网络结构,通过得到的径向基神经网络实现期刊分类大数据自动存储。
(一) 群体协同智能聚类方法的改进
传统群体协同智能聚类算法在计算时,时常出现获得局部最佳解的困境。而算法一旦遇到最佳解就会终止,不再继续计算,因此聚类算法的收敛性能较低[11][12][13]。为了提高期刊分类大数据的聚类精度,设计的大数据自主存储方法采用群体协同智能聚类算法,在传统群体协同智能聚类算法中采用多种群协同进化的方式,以免出现局部最优解。将总体种群划分成多个子种群,各子种群独立进化,对期刊分类的大数据实施周期性调控法,并将多种群协同进化也融入到调控法中。
群体协同智能聚类方法是一种群体协同进化的聚类算法,其将粒子数设置为N的种群划分成M个子种群,各子种群采用规范的群体协同智能算法实施局部检索,在检索时持续调整子种群内部粒子的效率以及位置。如果进化到第X代,则第一个子种群会获取局部最佳解一,并将该解传递给第二个子种群,用解一更新第二个子种群内具有最低适应度函数的粒子,此时第二个子种群实施X周期的进化,获取的局部最佳解是解二。再向第三个子种群传递解二,循环运行上述过程。最终一个子种群向首个子种群传递解M。每次迭代之前将即刻最佳位置反馈给后续子种群过程中,应对即刻的局部最佳解i是否符合精度需求进行分析,如果符合则终止聚类计算,否则继续聚类计算。各子种群的间隔是X代,相邻种群间可进行信息交互,循环进化,直至算法停止 。
聚类计算确保各子种群中的粒子处于最优解位置,增强算法的收敛效率。该群体协同智能聚类方法可确保各子种群同不同子种群间基于少量的局部信息完成交互,实现解区域中某个子区域的检索,运算代价小,并且子种群间的粒子变换能够完成远距离的信息共享。
(二) 期刊分类大数据的聚类处理
要对期刊分类大数据进行聚类,需先对期刊分类大数据进行特征提取,然后进行聚类处理[14]。虽然期刊分类大数据的特性在数据处理的时候较为复杂,但是对于并行聚类处理的方法设计过程来说是必不可少的。其过程为:首先将大数据进行人工的分类,来获取期刊分类大数据的样本。然后为了消除多余数据之间存在的可能性的矛盾对样本 进行并行聚类,并对选取特征性的数据。最后对性能改进型评估,以便聚类方法的性能得到改善。
在期刊分类大数据的聚类处理中融入并行的FCM算法[15]。所使用的FCM算法有密集计算的特点,先采用并行模式将期刊分类大数据进行数据分块,把分块后的数据划分到多种不同的进程中,使得多个进程同时期并行完成期刊分类大数据的聚类任务。具体FCM算法并行实现方法如下:
1 对期刊分类大数据采取并行的方式进行读取。在平台系统中先将期刊分类大数据划分为若干小份,再讲划分后的数据发送至各个进程,准备并行读取。
2 聚类中心在主进程中进入初始化阶段,再将聚类中心发送至各个子进程中。
数据并行模式是聚类方法中的主要采用模式,其中确保聚类方法精度的基础步骤即是数据的划分,所提聚类方法根据大数据的计算强度,对期刊分类大数据展开并行聚类,优化了FCM并行聚类算法的聚类任务负载不够均衡的问题,推导计算強度预估函数,运用预估函数对多个计算单元的计算量进行评估与测量,从而实现期刊分类大数据的聚类。
大数据存储系统的存储速度是用户考虑的重点。本文存储系统采用的群体协同智能聚类算法融入多种群协同进化的方案,避免出现局部最优解问题,具有较高的收敛效率,能够实现大数据的高效率写入操作。
三、 自动存储方法的个体评价和选择
利用计算合作适应值对子种群中某个体性能进行评价。合作适应值是该个体和源于其余子群的代表集中贡献值的体现,所以为了求解适应值,需从其余各子群中均选择一个个体,构成完整解。文中所有个体的适应值均指该个体和其余子种群的精英个体一起组成隐层结构的径向基神经网络的评价。
文章选用多个目标函数进行评价,从而有效保证种群的多样性。最后将多个目标加权求和转换为单目标,将其当成个体合作适应值。将分类存储精度最高作为第一个目标函数f1,通过将聚类成员δa中被准确聚类成相应种类Ci数据对象的数量γi之和,与数据对象数量N分之一的乘积得出单目标。随着Microprecision值的逐渐增加,分类存储效果也逐渐变好。将Fmeasure最大作为第二个目标函数,Fmeasure值主要取决于查全率与查准率。原始分类i的Fmeasure值Fi可通过2倍查全率与查准率乘积,与查全率查准率之和的商得出Fi加权平均,即可获取目标函数f2。Fm值越高,认为分类存储结果精度越高。固定期刊聚类,针对各期刊特征簇Ubl,用wpm描述特征bp在第m篇文档中的权重,用wim描述第l个特征聚类中心bcl在第m篇期刊中的权重,通过夹角余弦公式求出。利用上述因子的求和乘积,即可求出该簇中不同特征bp和该特征聚类中心bcl间的关联性,从而得到第三个目标函数f3。将期刊特征相似性最高作为第三个目标函数,利用求和乘积,从而得到第三个目标函数f3。设定集合Vdoc表示同时包含特征bp与特征bcl的期刊集合,Vdoc中所含期刊数量越多,同时出现特征bp与bcl的期刊数量越多。在此前提下,设ε1、ε2及ε3为既定指标重要性系数;ε1,ε2∈0,1均在[0,1]范围内取值,三者累积和为1,依次取03、03、04。则可通过上述重要性系数,及三个目标函数加权平均Fi获取个体评价和选择最终结果。
综上,个体评价和选择即把不同个体替换成精英集合中其所处子种群相应的精英个体,同时通过由此构成的径向基神经网络性能确定。
四、 结果分析
为了验证所提基于群体协同智能聚类的期刊分类大数据自动存储方法的应用效果,需要进行相关的实验并对实验结果进行分析。实验选用6个数据集,其中1个数据集为二维人工数据集,其它5个数据集为源于期刊大数据的真实数据集。6个数据集的具体信息分别包括如下内容:人工数据集的数据量为325个,均是2维,集群数共有3个;期刊真实数据集1的数据量为1200个,维数是4,集群数共有6个;期刊真实数据集2的数据量为1200个,维数是4,集群数共有6个。期刊真实数据集3的数据量为1800个,维数是15,集群数共有12个;期刊真实数据集3的数据量为1000个,维数是6,集群数共有5个;期刊真实数据集4的数据量为2000个,维数是14,集群数共有9个;期刊真实数据集5的数据量为1500个,维数是7,集群数共有8个。
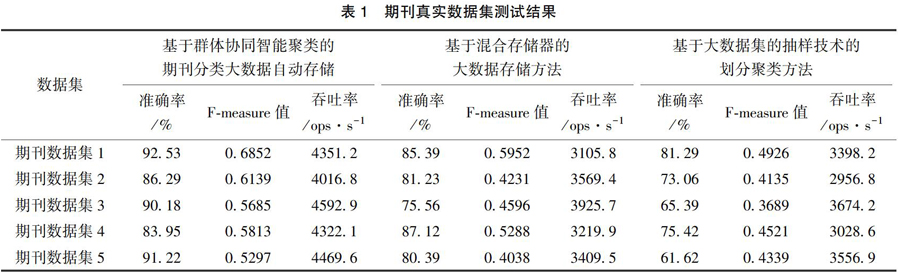
为了验证所提基于群体协同智能聚类的期刊分类大数据自动存储方法对期刊分类的有效性,针对二维人工数据集和真实期刊数据集,将基于混合存储器的大数据存储方法和基于大数据集的抽样技术的划分聚类方法作为所提方法的对比方法,进行实验测试。期刊真实数据集测试结果用表1进行描述。
分析可以看出,采用基于混合存储器的大数据存储方法对期刊分类大数据进行自动存储后,期刊的大数据能够得到大致分类,但分类精度不高。因而自动存储的结果中,各期刊的大数据有严重混杂现象,难以做到精确分类,导致自动存储的结果较差。采用基于大数据集的抽样技术的划分聚类方法对期刊分类大数据进行自动存储后,期刊大数据的分类精度相比基于混合存储器的大数据存储方法提高了很多,但依然存在分类不准确的情况,自动存储后的结果中发现仍有许多混杂在一起的大数据,不够准确的分类结果自然导致了自动存储效果的不理想。而采用本文方法对期刊分类大数据进行自动存储后,期刊的大数据分类精度较高,分类准确性高,因此自动存储结果较为理想。对比三种不同方法的实验结果可知,本文方法能够有效将二维人工数据集划分成3类,且划分精度较高,分类结果十分准确,分割集群中无其它集群数据。相比之下发现,基于混合存储器的大数据存储方法和基于大数据集的抽样技术的划分聚类方法分割集群中均有其它集群数据,划分结果不准确,因此验证了本文方法的有效性。
分别采用基于混合存储器的大数据存储方法、基于大数据集的抽样技术的划分聚类方法以及本文方法对期刊分类大数据进行自动存储,以下是对期刊真实数据集的存储,得到三種不同方法的对比测试结果如表1所示。
表1 期刊真实数据集测试结果
数据集
基于群体协同智能聚类的
期刊分类大数据自动存储
基于混合存储器的
大数据存储方法
基于大数据集的抽样技术的
划分聚类方法
准确率
/%
Fmeasure值
吞吐率
/ops·s-1
准确率
/%
Fmeasure值
吞吐率
/ops·s-1
准确率
/%
Fmeasure值
吞吐率
/ops·s-1
期刊数据集1
9253
06852
43512
8539
05952
31058
8129
04926
33982
期刊数据集2
8629
06139
40168
8123
04231
35694
7306
04135
29568
期刊数据集3
9018
05685
45929
7556
04596
39257
6539
03689
36742
期刊数据集4
8395
05813
43221
8712
05288
32199
7542
04521
30286
期刊數据集5
9122
05297
44696
8039
04038
34095
6162
04339
35569
分析表1可以看出,采用基于混合存储器的大数据存储方法对期刊真实数据集进行分类后的自动存储,对各期刊的大数据进行分类后,其分类准确率平均约为8034%,Fmeasure值平均约为04012,自动存储大数据的吞吐量平均约为3367%。采用基于大数据集的抽样技术的划分聚类方法对期刊真实数据集进行分类后的自动存储,对各期刊的大数据进行分类后,其分类准确率平均约为6478%,Fmeasure值平均约为03525,自动存储大数据的吞吐量平均约为3002%。与基于混合存储器的大数据存储方法相比,基于大数据集的抽样技术的划分聚类方法的分类准确率较低,且Fmeasure值与吞吐量也较低,因此得出基于大数据集的抽样技术的划分聚类方法的自动存储效果不如基于混合存储器的大数据存储方法的自动存储效果理想。采用本文方法对期刊真实数据集进行分类后的自动存储,对各期刊的大数据进行分类后,其分类准确率平均约为8662%,F值平均约为06131,自动存储大数据的吞吐量平均约为4598%。对比三种不同方法的实验结果可得,采用本文方法进行期刊真实数据集的自动存储,其分类准确率和F值相比基于混合存储器的大数据存储方法和基于大数据集的抽样技术的划分聚类方法的分类准确率高出很多,说明本文方法存储分类精度更高。且本文方法进行大数据自动存储的吞吐量也远远高于基于混合存储器的大数据存储方法和基于大数据集的抽样技术的划分聚类方法自动存储的吞吐量,说明本文方法存储效率更高,充分验证了本文方法实用性强的优势。
综合分析以上实验结果得出,所提基于群体协同智能聚类的期刊分类大数据自动存储方法能够高精度的完成各期刊大数据的分类,并且具有较高的吞吐量,能够在短时间内存储大批量的数据,因此自动存储效率高,充分说明了所提方法具有分类准确性高、存储效率快的良好性能,有效性和实用性强。
五、? 结 论
本文通过实验提出一种新的基于群体协同智能聚类的期刊分类大数据自动存储方法。确定径向基神经网络的初始结构,通过样本分布计算径基宽度,完成对初始隐层的聚类处理,获取隐节点群,将其当成初始集合。将分类存储精度最高、Fmeasure值最大、期刊特征相似性最高作为目标函数,将其加权和作为适应函数。结合Pareto支配概念与精英保留策略把协同进化遗传算法引入期刊分类大数据自动存储多目标优化问题的求解中。设置一种外部精英集合,通过拥挤距离提高外部种群的多样性,同时依据聚类思想完成对外部种群的分类处理,对各类构造对应概率模型。在进化时各子群内部通过模拟退火法将分布估计算法和遗传算法结合在一起,产生新个体,然后利用群体协同合作的方式实现智能聚类。求出不同子种群的个体适应值,对精英集合进行更新。通过进化获取最优个体,得到最终精英集合,将其看作最后得到的径向基神经网络结构,通过得到的径向基神经网络实现期刊分类大数据自动存储。经实验验证,所提方法整体性能高。
〔参考文献〕
[1] 刘先花. 基于群体协同智能聚类的大数据存储系统设计[J]. 现代电子技术, 2017, 40(23):130-133.
[2] 王永贵, 宋真真, 肖成龙. 基于改进聚类和矩阵分解的协同过滤推荐算法[J]. 计算机应用, 2018, 38(4):1001-1006.
[3] 刘岩, 王存睿. 基于抽样融合改进的大数据聚类方法[J]. 微电子学与计算机, 2017, 34(4):17-21,27.
[4] 曹阳, 钱晓东. 基于局部关键节点的大数据聚类算法[J]. 计算机工程与科学, 2016, 38(7):1338-1343.
[5] 杨光, 钟忺, 夏红霞, 喻天宝. 基于分布式处理的关联聚类协同过滤算法[J]. 武汉理工大学学报, 2015, 37(11):84-92,112.
[6] Mai,H. T., Park,K. H., Lee,H. S., Kim, C. S., Lee, M. & Hur, S. J. Dynamic data migration in hybrid main memories for In‐memory big data storage[J]. Etri Journal, 2014, 36(6):988-998.
[7] 卢志茂, 冯进玫, 范冬梅,杨朋,田野. 面向大数据处理的划分聚类新方法[J]. 系统工程与电子技术, 2014, 36(5):1010-1015.
[8] 王兴茂, 张兴明, 吴毅涛, 潘俊池. 基于启发式聚类模型和类别相似度的协同过滤推荐算法[J]. 电子学报, 2016, 44(7):1708-1713.
[9]马蕾, 杨洪雪, 刘建平. 大数据环境下用户隐私数据存储方法的研究[J]. 计算机仿真, 2016, 33(2):465-468.
[10] 张栗粽, 崔园, 罗光春, 陈爱国,卢国明,王晓雪. 面向大数据分布式存储的动态负载均衡算法[J]. 计算机科学, 2017, 44(5):178-183.
[11] 罗弦, 查志勇, 徐焕, 刘芬,詹伟. 基于云计算的大数据自动分类处理系统设计[J]. 计算机测量与控制, 2017, 25(10):278-280,288.
[12] 赵妍, 苏玉召. 一种批量数据处理的云存储方法[J]. 科技通报, 2017, 33(7):81-85.
[13] Yang Fan, Zou Sai, Tang YuLiang & Du XiaoJiang. A multichannel cooperative clusteringbased MAC protocol for V2V communications[J]. Wireless Communications & Mobile Computing, 2016, 16(18):3295-3306.
[14] 王瑞通, 李炜春. 大数据基础存储系统技术研究[J]. 计算机技术与发展, 2017, 27(8):66-72.
[15] 周娇, 傅颖勋, 刘青昆, 舒继武. 一种支持网络硬盘存储系统的大数据传输技术[J]. 小型微型计算机系统, 2014, 35(2):329-333.
- 把握新方位,走好“下半程”
- 城市社区体育文化养老模式探析
- 论城市社区网站在社区建设中的角色与功能
- 大学生志愿组织的社会化发展现状分析
- 京津冀协同治理视域下农民信访问题探源
- 精准扶贫财政政策探索
- 以供给侧改革提升民族贫困地区生态乡村建设的质量
- 基于供给侧改革视角黑龙江省农村妇女就业问题研究
- 中俄合作保护黑龙江沿岸生态环境的建议
- 常用柔性领导方法的理论归纳
- 五大发展理念下如何增强教育的软实力
- 以社会主义核心价值观引领高校社团建设
- 新媒体时代大学生社会主义核心价值观教育审视
- 大学生社会主义核心价值观认同教育的路径研究
- 高职院校红色资源爱国主义教育中的问题与对策
- 红色资源在党校教学中的作用
- 新时期革命纪念馆红色文化的时代价值
- 东北抗联资源专题数据库建设探讨
- 建筑施工企业思想政治工作务实创新新思路
- 大学生思想政治教育机制的实效思考
- 高校加强马克思主义信仰教育的着力点
- 基于人格理论的思想政治教育研究
- 高校大学生党建工作的几点思考
- 信息化时代提升毕业生党员党性修养和科学化管理模式探索
- 全面从严治党视角下党员教育管理探讨
- ophthalmologies
- ophthalmologist
- ophthalmologists
- ophthalmology
- opinion
- opinional
- opinionated
- opinionatedly
- opinionatedness
- opinionatednesses
- opinionation
- opinion leader
- opinionleader
- opinionless
- opinionpoll
- opinion poll
- opinions
- opium
- opiums
- opm
- opp.
- opponent
- opponents
- opportune
- opportunely
- 不防头 不妨头
- 不防这一手
- 不阴不阳
- 不阴又不阳
- 不阶尺土,一人之柄
- 不阿
- 不阿不挠
- 不阿谀逢迎
- 不陂不倚
- 不附声韵
- 不限
- 不限一格
- 不限于一经一论的研究方法
- 不除稂莠,难种嘉禾
- 不随
- 不随便凭一己之见而独断专行
- 不随便发表意见
- 不随便用钱
- 不随便,不马虎
- 不随意
- 不随浊世沉浮
- 不随溜儿
- 不隐讳,如实把话说出来
- 不难
- 不难治理的问题