查找问题中的算法


编者按:教育部颁布的《普通高中信息技术课程标准(2017年版)》在“必修模块1”中用专门的单元谈论了算法,这说明,新课程要求高中信息技术在教学中应当以算法为要旨,强化算法的重要性。
本刊从本期起开设“算法园地”专栏,特邀北京大学计算机系原系主任李晓明教授、南京大学计算机系原系主任陈道蓄教授撰写有关算法的文章,为读者提供一些既有思想性又有实用性的材料。
专栏的读者定位是对算法问题有兴趣的中小学教师,内容的铺陈将努力做到通俗性、趣味性和严谨性相结合。每月介绍一个算法,每期独立成篇,大体按照以下六个方面展开:应用背景、算法描述、实例模拟、性质分析、思考问题、参考代码。你以前如果学过算法,在这里会看到一种不同的视野;你以前如果没有学过算
法,则可以通过对每月一个算法的学习,既领悟到算法思想的精髓,又形成算法实战的能力。
现实生活中,每个人都有需要在一堆东西里找出某件特定物品的经历。一番努力后,可能找到,也可能没找到。此外,当我们新得到某件物品(如一本书)时,有时也会为把它在放在什么位置而纠结,希望将它放到一个今后找起来方便的地方。
计算机中与这种生活现象对应的,就是对数据的两种基本操作:“查找”(search)和“插入”(insert)。选择适当位置插入的目的主要就是便于今后的查找。查找和插入操作,其本身有直接的应用,同时也是计算机中许多其他复杂操作和功能的基础。由于其基础性,计算机科学家有不少专著对它们进行了系统介绍,最经典的是Donald Knuth的The Art of Computer Programming Vol. 3: Sorting and Searching,其中用了190页来讨论查找算法。
一般来说,讨论查找和插入操作,我们总是面对一个数据元素集合A={a1,a2,…,an}和一个数据元素x,问x是否在A中。当发现x不在A中的时候,如果需要的话,则把x放入A中。
这样的操作,如果十分频繁,且随着时间的积累A变得很大(如n>109)的时候,效率就是值得重视的一个问题了。关键归纳为两点,一是如何组织A中的数据,二是如何平衡查找和插入操作之间的效率。后面这一点即是说,如果预计查找是频繁的,插入是稀少的,则可以在插入操作上花更多的时间,以换取查找上时间的减少。而关于A中数据的组织,在计算机中涉及采用不同数据结构的考量,也是本文展开的线索。具体来说,下面安排有四个小节:(1)无序元素列表上的查找与插入;(2)有序元素列表上的查找与插入;(3)搜索二叉树上的查找与插入;(4)平衡二叉树上的查找与插入。
● 无序元素列表上的查找与插入
这是最基本也是最简单的一种情况。集合A={a1,a2,…,an}的元素任意放在一个列表(Python)或数组A中,对于需要查找的数据元素x,执行如图1所示的算法。
算法逻辑直截了当,挨个和A的元素比较,发现了有相等的就报告成功;若比较完了还没看到x,就报告失败,接着把x放到A的末尾(插入操作)。
可见,这里的插入操作很简单,O(1)。但查找操作最坏的情况需要做n次比较,即O(n),适合插入较多(即新元素较多)、查找较少的应用场合。
● 有序元素列表上的查找与插入
当查找很频繁,且n很大时,实质性地减少查找需要的计算量就变得很有意义了。脑筋就动在数据的组织上,即要让A的元素按某种特定方式组织,便利查找的过程。一种简单的方式就是让它的元素有序,从而可以支持所谓“对分查找”的算法。原理很直观,就是利用列表元素有序(不妨设增序)的特点,如果发现x
算法用low和high控制需要查找的范围,每次通过mid=(low+high)//2确定“中点”(所谓“对分查找”由此而来),在偶数个元素的场合则是取中间靠左的一个。如果x和A[mid]不相等,就需要移动low或者high,对应的“mid+1”和“mid-1”保证了查找范围总是应该包含low和high指示的元素,与初值设定的含义一致。
如果某次比较相等,就报告成功,结束。若x不在A中,最后一次比较对应high=low的情况,此时mid=low=high,若还不成功,等价地就是置low←high+1或者high←low-1,也就是while循环不再执行的条件。
报告失敗,把x插入到A中,不再像前面那么简单了。需要有点讲究,对应最后4行代码,取决于最后一次比较时x小还是大,分别插入到mid的当前位置或后面,以保证A中元素的有序性。更重要的是,这里的插入要涉及后面元素的移动,对效率是有影响的。Python列表的插入操作对程序员屏蔽了那些数据的移动,但在程序运行中实际会发生。大多数编程语言都需要程序员在程序中表达数据移动的过程。
综合起来,基于有序元素的列表,对分查找的查找效率高,得出判断的复杂性是O(log2n),这与O(n)相比是实质性的提高。不过代价也是明显的,即在没找到又需要插入的时候,最坏情况下要在列表上往后移动n个数据,即O(n),适合查找较多、插入较少(即新元素较少)的应用场合。
● 搜索二叉树上的查找与插入
前面介绍的两种方法总的来说都比较简单明了,各有千秋,也各有不足。有没有办法综合它们的优点,避免它们的缺点呢?理想目标就是,判断x是否存在于A中,希望能有O(log2n)的效率(类似于对分查找),而如果x不在A中,为插入x涉及的数据移动操作为常数量级[类似于顺序查找中的A.append(x)]。
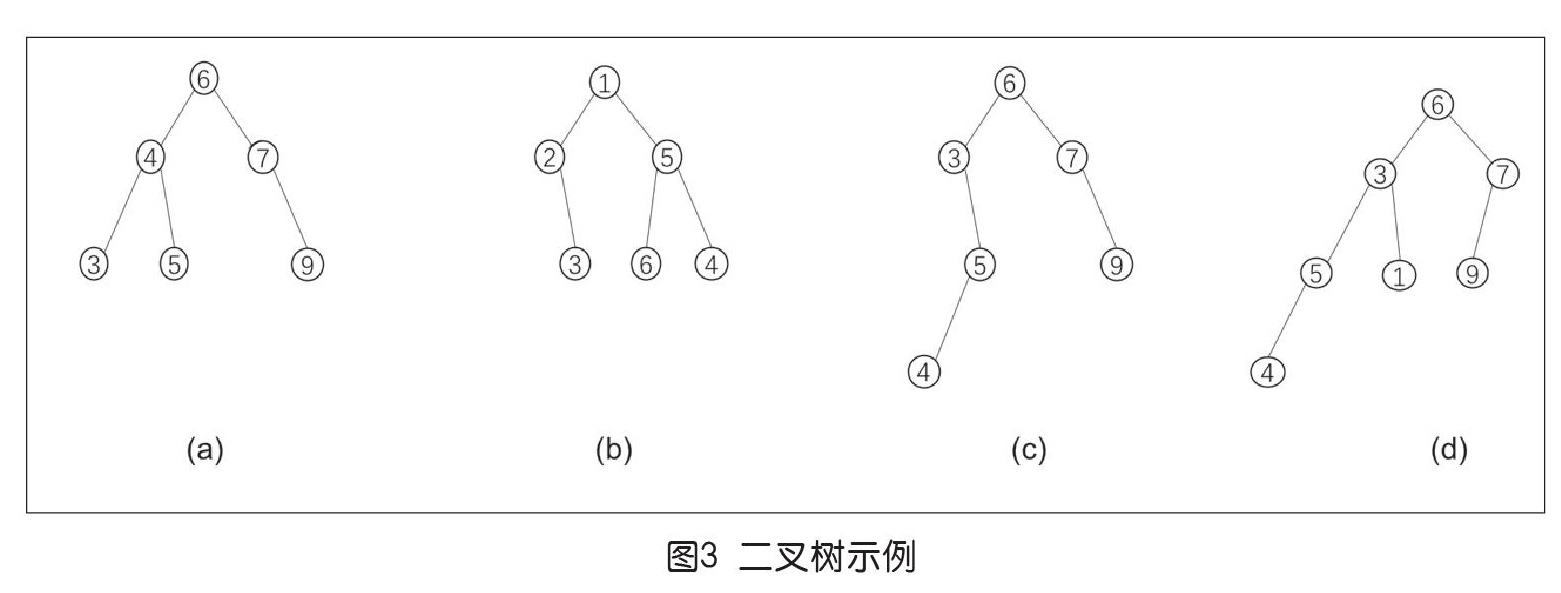
采用二叉树数据结构是实现这一追求的基本途径。二叉树是一种重要的数据结构,核心概念为“树根”“左子树”“右子树”和“递归定义”。我们假设读者对它已有所了解,图3所示为几个例子。
在应用中,二叉树中的节点常用于存放数据。当我们将数据之间的大小关系与树中节点的结构性关系做某种对应的时候,就可能导致令人兴奋的算法结果。搜索二叉树(亦称“查找二叉树”)就是这方面的一个例子。
上述“数据之间的大小关系与树中节点的结构性关系”的对应,在搜索二叉树上即是:根节点的数值不小于左子树节点的值,不大于右子树节点的值。在图3中,(a)和(c)是搜索二叉树,(b)和(d)则不是。
这样的搜索二叉树对我们的查找任务有什么好处呢?仔细体会一下,它与二分查找的精神十分相近。当我们把数据集合A的元素按照搜索二叉树的要求放好之后,查找x是否在A中,就是从根节点开始比较,如果x较小,则意味着它比右子树的所有节点都要小,不用再去查了(相当于对分查找中不用再关注mid右边的元素),只需关注左子树就可以了(相当于图2中做的high=mid-1)。
如果查找失败,需要把x插入到A中,如何保证能插入到正确的位置呢?在前面讨论对分查找的时候,我们已经明确将新元素插入到数据集合的适当位置是一件需要仔细确定的事情,目的就是要保证得到的数据结构具有相同的性质。在那里,就是元素之间的顺序,在这里,就是搜索二叉树的要求。
我们注意到,查找不成功的结论总是出现在与二叉树中某个节点a比较不相等,按规则不能再进展之时(a可能是叶节点,也可能是一边子树为空的非叶节点),如果xa的情形类似。
这样做达到本小节提出的目标了吗?注意到n个节点的二叉树的高度最低可达log2n,这意味着查找效率可能做到O(log2n)。同时我们也看到,这里的插入操作很简单,即在查找不成功的时候在当前节点上生成一个子节点,效率就是常数量级的,O(1)。一个十分接近可执行程序段的伪代码描述如上页图4所示。
如此,查找问题似乎就圆满解决了。采用搜索二叉树作为数据结构,既可能得到查找的高效率,也有插入的高效率。然而,依然还有一个潜在的问题,那就是上述方法不能保证二叉树的高度为O(log2n)。事实上,大量如上所述的简单插入操作很容易导致一棵“病态的”二叉树,其高度不是log2n,而是更接近n,从而无法体现其优势了。下一节的内容即是针对这种问题的一个解决方案。
● 平衡二叉树上的查找与插入
目标很明确,就是希望让二叉树的高度总保持在log2n量级。途径也清楚,就是允许插入操作适当复杂一些,每当完成插入的时候,不仅要保持搜索二叉树节点间的数值关系正确,还要根据需要对二叉树的结构做平衡调整,保证每一个节点左右子树的高度之差不超过1。我们称这样的二叉树为“平衡二叉树”。
以图3中的4棵二叉树为例,(c)就是不平衡的,因为节点3的左子树高度为0,右子树的高度为2,高度差超过了1。我们同时注意到,(a)是一棵平衡二叉树,它的内容和(c)完全一致,结构上则有局部调整(节点6的左子树)。如何在发现(c)的情况出现时做代价不大的调整以达到(a)的结果,就是我们要讨论的问题。下面通过一个例子来学习一种方法。
以一棵平衡二叉树为基础,按照前述搜索二叉树的方式,在插入一个新节点后,每一个节点将具有如下五种状态之一:(1)两棵子树的高度一样,称为完全平衡,用0表示。(2)左子树高度比右子树高1,称为左沉(但依然平衡),用-1表示。(3)右子树高度比左子树高1,称为右沉(但依然平衡),用+1表示。(4)左子树高度比右子树高2,称为左失衡,用-2表示。(5)右子树高度比左子树高2,称为右失衡,用+2表示。
以图3(c)为例,对应节点6、3、7、5、9、4,就有-1、+2、+1、-1、0、0。而在图3(a)中,节点7的状态为+1,其他节点状态都是0。显然,插入一个节点后,若每个节点都处于0、-1或+1状态,就不需要做任何事情。调整发生在有节点的状态变成了-2或+2时。
如果一个节点(X)的状态变成了+2(-2的情况对称,只需要把下面两点描述中的“左”和“右”互换即可,此处从略),有两种情况需要考虑。
第一种情况,若X失衡的原因是其右子树的右子树上插入了一个节点,则令X的右儿子(Y)为根,令X为Y的左儿子,同时令Y原先的左子树为X的右子树。这个操作称为“左旋”。
第二种情况,若X失衡的原因是其右子树的左子树上插入了一个节点[对应图3(c)中的节点3],那就先以右儿子(Y)为轴做一个“右旋”,让它的左儿子“上位”(成为这棵子树的根节点,即占据原来节点5的位置),接着再以X为轴做一个左旋。图3(c)据此操作后即得图3(a)。
按照这种方法得到的二叉搜索树(平衡二叉树)称为“AVL树”注,也是最早(1962年)被发明出来的一种平衡二叉树,它保证了树高为O(log2n),于是前面提到的“病态”情况不再出现,查找操作的效率得以保持为O(log2n)。其代价则是要记录节点的平衡状态(包括增加了数据结构的复杂性和每次插入一個节点后的状态更新),以及根据状态做上述平衡调整。其中,平衡调整本身是常数量级的操作,但节点平衡状态维护的计算量是和树高log2n成比例的。综上所述,对于带插入功能的查找操作,我们可以得出结论:(1)基于列表的效率为O(n),无论元素有序还是无序;(2)采用搜索二叉树,理想效率为O(log2n),但很可能做不到;(3)而采用AVL树,效率保证为O(log2n)。
前面,我们分四小节讨论了查找问题,它们之间除了在目标追求上有递进的关系外,还展示了一种技术上的共性,即在算法过程中始终要保证数据结构上某种性质的满足。在对分查找中,要保证列表元素的有序;在搜索二叉树查找中,要保证任何时候都满足搜索二叉树上节点位置与元素值大小的特定关系;在平衡二叉树查找中,则除了搜索二叉树的性质外,还要保证二叉树的平衡。如果这些性质不能得到一致的保证,算法就失去了正确的基础,一些计算代价正是为得到这些保证而付出的。
参考文献:
[1]Donald Knuth.The Art of Computer Programming, Second Edition, Vol 3[M].Addison-Wesley,1998.
[2]邓俊辉.数据结构(第3版)[M].北京:清华大学出版社,2018.
注:AVL由两位发明人Georgy Adelson-Velsky和Evgenii Landis的姓氏头字母组合而成。
