基于NLP文字处理的评论有用性探究
钟丁媛 高峥洲 金皓辰 陶昉昀


摘 要:网上购物的普及,在拉动消费经济增长的过程中发挥着日益显著的作用。然而,由于网络购物的局限性,消费者无法了解商品的质量。因此,探索评论有用性有助于消费者做出购买决策,也有助于商家采取相应的销售策略。本文对评论文本进行NLP文本处理,通过提取特征词,建立情感文本语料库,对评论文本的情感极性和主观性进行分类,并验证正确率达到88%。尔后构建评论有用性模型,分析了影响产品口碑的因素,利用亚马逊11470条评论进行验证,得到结论:评星极性越强、可读性越强,有用性越强;帮助度投票与星级之间呈凹形关系。此外,拥有多功能产品的知名品牌更容易受到消费者的青睐。
关键词:NLP情感分析;评论有用性;可读性;Tobit
一、问题背景
(一)互联网和网络购物的快速发展
互联网的出现和快速发展推动着网络购物的迅速普及,拉动全球经济的增长。作为全球最大的电商平台,截至目前,亚马逊在全球20多个国家和地区开展业务,引领全球电商的发展。
(二)商品口碑对消费者网购决策的影响
商品的口碑指人们自愿对商品的性能、質量等方面发表的评论。由于网络购物的局限性,消费者只能通过商品描述、口碑等方式了解商品信息,因此购物存在一定的风险性。
(三)商家竞争不断加大
由于网络销售经营成本低、可复制性强,同行业商家不断涌入,各个行业的商家已趋近饱和状态,因此商家间的行业竞争愈发激烈。为了在竞争中拔得头筹,商家不得不采取相应的销售策略,赢得竞争优势。
二、NLP文字情感分析
数据文件提供了亚马逊市场上微波炉、婴儿奶嘴和吹风机的销售状况和用户评价。首先,对数据进行处理和分析。
(一)数据预处理
清洗冗余数据,并检验是否存在异常数据。由于评论者是否为会员和是否购买商品,只有两种答案,因此对其归一化处理,“是”用1表示;“否”用0表示。
(二)评论文本处理
由于评论文本的词数差异很大,词数最多的评论达到了1569个词,因此必须对评论文本进行处理。
首先引入停用词的概念。停用词是指处理搜索请求时会自动忽略的词,大致分为两类:一是应用广泛词,其不能保证搜索结果正是需要的,难以缩小搜索范围。二是无明确意义的词,如语气词、介词等,只有放入完整的句子中才有意义。
然后,我们对评论文本进行如下处理:
1.基本特征提取
词数:词数影响阅读时间和内容的理解程度。因此将评论句子切分,得到词汇数量。
平均词汇长度:词汇长度越长,人们的理解难度越大。因此将评论所有的单词长度除以单词数,得到平均词汇长度。
停用词数量:计算停用词的数量可以提供额外信息。通过调用NLTK库计算停用词的数量。
2.文本处理
小写转换:为了避免同一单词存在多个副本,将评论中单词均转换为小写。
删除标点:标点在文本中不能提供有效信息,删除标点将减少数据量。
删除停用词:删除停用词可以节省文本的存储空间并提高搜索效率。
分词与向量化:分词指将文本划分成一系列的单词或词组。通过分词,将文本向量化,有助于计算特征词的个数。
计算词频:词频指单词在句子中出现的次数与句子总单词数的比例。
经过处理,我们减少了特征词的数目,但是仍然避免不了有些单词出现频率很高,但不具有代表性。另一方面,若单词出现次数过少,具有强独特性,对特征词无帮助。因此我们去除出现频率高于0.8或出现次数小于3次的单词。经过处理,特征词的数目降到大约4000个。
3.模型训练
随机取75%的评论数据作为训练集,剩下的作为验证集,对模型进行训练。
情感分析:使用TextBlob判断特征词的极性和主观性。其中,极性取[-1,1]间的浮点数,正数表示积极,负数表示消极。同样地,主观性取值中,0表示客观,1表示主观。我们利用训练集模拟,并预测了对情感分类标记,将预测结果读入scikit-learn测量工具集,得出预测准确率为86.51%。
混淆矩阵:可用来评价精度。由于单看准确率不太全面,因此利用混淆矩阵验证预测的准确率,得出情感分类结果,如图1所示:
由此得出,特征词为正向,预测结果也为正的数量为436;负向且预测也为负的数量为2045,这表明预测正确的特征词数量远高于预测错误的数量。
ROC曲线:反应模型在选取不同阈值时的敏感性和精确性趋势走向。对训练集样本进行排序,计算真正例率和假正例率。AUC是ROC曲线与坐标轴围成的面积,介于0~1之间,值越大则分类越好。得出ROC曲线图,如图2所示:
由此,得到AUC的值为0.88,进一步说明了我们对特征词的分类效果很好。
经过评论文本处理,我们得出了所有评论文本的正负面评价数和情感数,并计算出这些特征词的极性和主观性。如"This item it's been working perfectly fine,I'm glad i ordered!!"中,特征词11个,包含正面评价数2个、正面情感数1个,该评论极性为0.458,评论主观性为0.75。
三、评论有用性模型的建立
通常一条完整的商品评论包含:产品ID、评论ID、评星、有用性投票、评论总投票数和评论文本。高质量的评论可以客观、全面地反应产品的优缺点,直观反应用户的使用体验;低质量的评论对潜在购买者的参考价值不大,还可能存在虚假信息,从而产生误导。
(一)影响评论有用性的因素
1.评论文本
评论字数:一般而言,评论字数越多,包含商品细节越多。但是细节过多会导致信息超载,降低评论可读性。评论字数对有用性的影响存在一个临界点——144个字,一旦超过这个值,字数与有用性的关系变得不显著。[1]
评星:评星是一个更为直观的评价商品好坏的标准。
评论可读性:可读性是基于评论文本的长度、单词复杂度等变量的综合计算,在一定程度上反映评论文本的易理解性。通俗易懂的文字可以提高浏览者的理解度和阅读速度,进而提升评论的有用性。但是,用词复杂的评论往往看起来更加专业,更容易得到读者的信任。从单词极性来看,评论文本特征词中情感词的数量和强度也会影响有用性。
与其他评论的交互作用:评论的呈现顺序会影响消费者对有用性的判断,靠前的评论曝光度高,浏览量大,有用性高。由于人们的从众心理,与大众观点一致的评论更为可信。但与总体评分偏差较大的评论能提供与众不同的观点和体验,也具有参考价值。
2.评论者因素
评论者的身份:评论者言论的可信度水平直接影响到评论有用性。网络购物者用户身份只能通过ID、照片等因素来判断。一般而言,身份信息越明显,评论可信度越高。
是否为会员:基于用户在评论方面所获得的信任,极有可能被邀请成为亚马逊会员,其评论会被认为可信度更高,从而更容易帮助潜在消费者做出决策。
购买经验:亚马逊平台允许未购买商品的用户做出评论,因此用户是否购买商品也应被考虑。
(二)可读性测试
可读性测试的目的是基于文本内容,告诉评论浏览者理解评论的难度,一般用比例的形式表达。目前,计算可读性的主要方式有如下几种:[2]
Gunning FOG Index
该指数可从词数、难度、句子数量和平均句长等方面考察文本阅读难度,将具有两个以上音节的单词作为复杂单词。
以上四个公式均是通过将文本分解成基本结构来评估文本的可读性,然后使用经验回归公式将这些元素组合。FOG和CLI指数衡量的是复杂性,而FK和ARI指数衡量的是阅读难度。由于在数据处理过程中,我们已经得出了以上变量的值,因此可以很方便地计算。
(三)探究因素的相关性
1.商品总体满意度
用户对商品的评星反映了顾客的总体满意度。吹风机的总体满意度为4.12分,微波炉为3.44分,奶嘴为4.30分。用户具体评星分布如图3所示:
投票中5星的数量最多,然后是4星和1星。在对商品进行评星时,人们、使用单一指标评价,往往会给出极性强的结果。因为极性强的评论,传达的信息是片面的,比提供双边消息容易。
2.帮助度和星级的关系
本文将认为评论有帮助的投票数作为评论的帮助度。并没有常规地使用帮助率,是因为考虑了主观性。对于帮助率为75%的评论而言,4人中3人赞同与100人中75人赞同的评论,人们往往认为后者可信度更高。
对于吹风机而言,其11470条评论中,得到帮助度反馈的共有4329条。其帮助率分布如图4所示:
由图可知,这些评论中,2280条得到了评论浏览者的满分,占52.67%,这表明超过一半的评论受到高度赞扬。另一方面,630条极端反对,占14.55%,这部分评论被浏览评论的人认为没有帮助。
将帮助率具体划分到五个评星中,计算各个星级的频次。其中,认为评论完全帮助的人数遠大于其他人数,认为评论完全没帮助的人数仅次于它,且不同星级评论的帮助度分布具有一致性。此外,帮助度与星级存在凹评级关系,即极性评星的频数大,非极性评论的频数小。
3.因素相关性
Spearman相关系数用来根据等级研究两个变量间相关性,计算两列成对等级的各对等级数之差。对于样本容量为n的样本,n个原始数据被转换为等级数据,计算其相关系数。
为了防止文本极性和评星极性不匹配,我们探究评论文本极性、主观性和评星间的相关性。计算相关系数得出,三者存在较高的相关性。
对样本进行Spearman非参数项间相关性分析,以评估不同因素间的相互关系。通过计算各指标间间的相关系数,得到这些因素间存在显著的相关性,其中,星级与其余因素呈负相关,其他均呈正相关。值得注意的是,四个可读性测试指标间显示了较高的相关性。也进一步证实了帮助度受文本可读性影响。
(四)模型建立
1.评论帮助度模型建立
下面进一步探究文本结构对帮助度的影响,及其与评论人数的关系。换句话说,探究极端评论高曝光度对可读性的影响。为此建立如下模型:
表中r2给出了模型的预测能力。模型1显示,评分对帮助率的二次效应无显著性,可能是由于数据中存在过多的强积极性评论,与强消极性评论的差值过大,使得凹关系不显著。单词数量显著却对帮助率没有影响;而评价等级有显著影响。
模型2考虑到评论文本结构和风格对帮助率的影响,评价等级的影响效果略有下降,但模型的拟合度提高,且四个可读性系数的值都比字数高,这意味着可读性比评论长度对有用性的影响更大。
模型3的拟合度增加了38.53%。表明虽然总票数和有帮助投票数的二次效应不显著,但是模型的拟合度增加。
四、评论有用性模型的检验
(一)评论特征对有用性影响的检验
接下来我们想探究帮助率是否反作用于评论特征。为此,我们将数据按照帮助率和评星数划分为以下几类:
(1)评论帮助率低于或高于0.5。
(2)评论帮助率低于0.25或高于0.75。
(3)低星评论(1-2星)或高星评论(4-5星)。
(4)极性强的评论,即一星或五星评论。
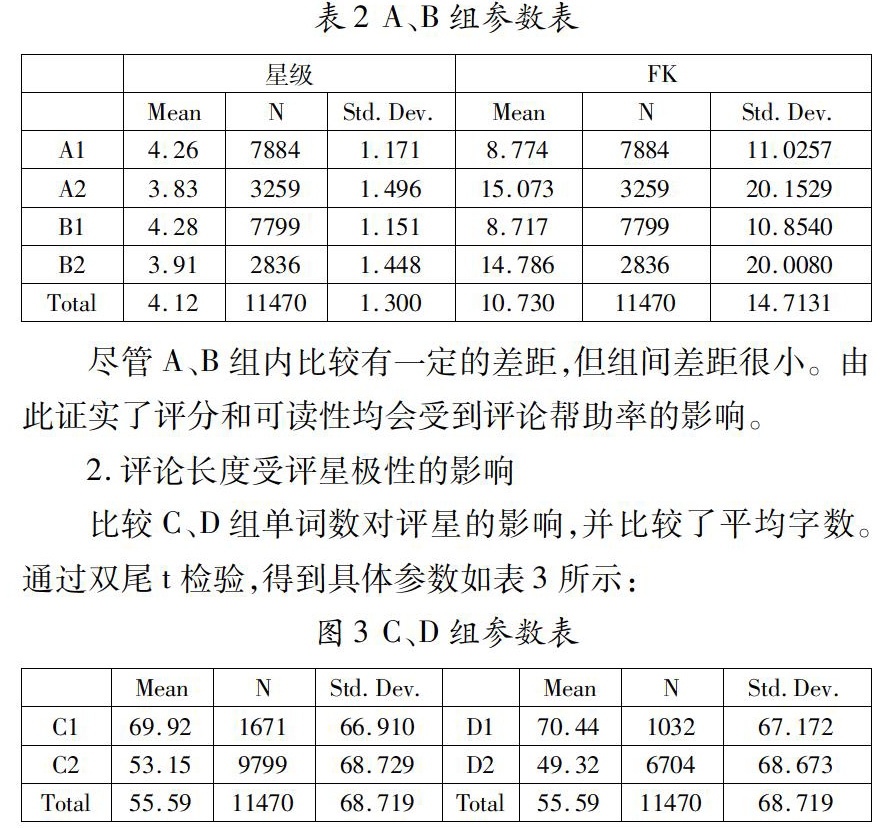
1.评论极性和可读性对有用性的影响
尽管组内的单词数和均值有一定的差距,但组间差距很小。由此证实了评论长度受评星的影响。从文本中包含的单词数量可以看出,评星积极的评论往往包含更多的文本信息。
(二)品牌对有用性的影响
网上销售中,人们往往会注重商品品牌和功能。筛选出吹风机销量大于100的商品,并根据品牌进行合并,得出位于前四个的品牌是Conair,Andis,Remington和Revlon。其中Conair的销量为3315,Andis为2162,远高于其他品牌。这四个品牌中,最热门的单品销量分别为535,555,587,297,前三热销商品销量没有太大区别,但Conair和Andis商品型号多、功能强,造成销量差距。
考虑到商品口碑的因素,我们根据用户的评价及评星,统计出词频最高的词,如图5、6所示:
由此得出商品销售的启示:在商品标题中标明功率、颜色、质地等关键词,以便消费者更直观地做出购买决策。
五、结语
从单个因素来看:评论字数越多,提供细节越多,有用性越强。但评论字数超过144个时,字数与有用性的关系不显著。评星极性越强、可读性越高,有用性越强。评论的呈现顺序越靠前,曝光度越大,有用性越强。考虑到不同因素的相关性:评论文本的极性、主观性和评论星级间存在较高的相关性,显著性强。极性评论可读性更强,有用性更强。评论帮助度受积极评论影响:随着评星增加,帮助度有一个显著的上升趋势。评论的帮助度与星级具有凹评级关系,即极性星级频数大,非极性评论频数小;但评分对帮助度的二次效应没有显著性。可读性测试指标间显示了较高的相关性。此外,商品品牌和功能也影响着评论有用性。商品型号多、功能丰富,能滿足广大用户的购买需求,因此其商品评论有用性强。
这一结论有助于企业采取干预策略,提高自身的市场竞争力,如:加强良好的产品宣传,打造有吸引力的产品名称,不断优化产品设计,更加贴近市场需求;注重售后服务体系的完善和优质客户的培养。
参考文献:
[1]Albert H.Huang,Kuanchin Chen,David C.Yen,Trang P.Tran.A study of factors that contribute to online review helpfulness[J].Computers in Human Behavior,2015,48.
[2]NikolaosKoratis,ElenaGarcía-Bariocanal,SalvadorSánchez-Alonso.Evaluatingcontentqualityandhelpfulness of online product reviews:The interplay of review helpfulness vs.review content[J].Electronic CommerceResearchandApplications,2012,11(3).
基金项目:2020年1月国家自然科学基金面上项目“Navier-Stokes-Allen-Cahn方程组的数学理论研究”(项目编号:11971234);2017年5月南京林业大学“国际教育学院中外合作办学高水平示范”(项目编号:164101005);2017年7月南京林业大学“2017年教学质量提升工程”(项目编号:163101812);2018年7月南京林业大学“高等教育研究所通过数学建模竞赛提高创新性人才培养研究”(项目编号:163101147);2018年7月南京林业大学“基于数据分析的“智能化”新庄立交交通的研究和建模”(项目编号:201810298062Z);2019年6月南京林业大学“Imiracle”——多维学习研讨与辅助教学小程序的研发”(项目编号:2019NFUSPITP1040);2019年6月南京林业大学“多维学习研讨与辅助教学小程序的研发”(项目编号:201910298203T)
作者简介:钟丁媛(1999—),女,汉族,江苏扬州人,南京林业大学理学院2017级在读本科生,研究方向:应用数学。
