基于分类算法的安卓系统应用识别研究
王学婷+刘尚东+李剑+周玮
摘要:研究安卓系统在连入网络的情况下,手机收发流量基于应用类型的分类情况。通过截取手机收发的流量包,并从中提取具有标志特征的流属性,生成矩阵数据,采用合适的分类算法,进行流关于应用类型的识别划分。
关键词:安卓系统;流量;抓包;应用划分
1引言
随着智能手机和3G、4G网络的普及,流量也成为话费支出的一大巨头。据著名分析机构Strategy Analytics公司发布的一份关于Android用户数据流量使用情况最新调研报告显示,有近四分之_的Android用户被归类为“重度用户(Power User)”,每天使用的数据流量超过300M。日益增长的手机流量消费以及手机流量分类对于运行商改善网络发展规划、提供高能效业务等方面的重大影响,都使得对于手机流量的应用分类成为我们关注的目标。而安卓手机作为手机系统中的主流,自然地被选作了手机系统分类研究的目标。
目前,网络流量的分类已经被广大研究者关注,在流量分类上也取得了较大的成果。本实验的目的就是将网络流量的分类算法引入到安卓手机流量分类中来,基于应用将手机上进出的流量进行识别划分。针对这个目的,我们的工作主要流程是获取安卓手机不同类型应用的报文,提取某些流测度,训练出一个分类器,当安卓手机有应用传输数据时,抓取报文,利用训练出来的分类器进行流量的识别,判断是哪类应用。
每个报文的头部都有相同的指标,但是不同的应用交换的流的指标参数都有其独特的特征,这也是本文将流为划分不同应用的依据。基于正确的分类算法,能够较为准确的判断出应用类别。
检测流的应用分类,本文将其分为以下几个步骤。(1)获取不同类型应用的流的特征参数出训练分类器。(2)用抓包软件抓取手机后台吞吐的流量包,保存,提取特征参数。(3)通过域名地址对应表或分类器进行应用确定。本文监测的流量和训练分类器所用的流量,都是来源于运行配备android系统的手机上的不同应用而捕捉到的。
2相关工作
关于网络流量分类的研究成果,主要可以归纳为4种方法:基于标准端口匹配、基于深度包检测、基于协议解析和基于统计学习方法。每种方法各有优缺点和适用范围。鉴于基于端口和基于协议的局限性,本文将采用较为灵活的基于统计学习的分类算法。前人在此已经有了较为丰富的成果:周剑峰等人改进了C4.5算法,提高决策树的构建速度;林平、雷振明等人通过程序对采集的数据进行特征提取,利用两类流的特征,将单个流检验的正确率大幅度提高,同时也将最终模型从35个特征参数降维到26个,进一步降低了复杂度。
综上,可以总结出基于统计学习的流量分类的内容:基于统计学习的流量分类方法通过计算特定的应用流量的统计信息,利用各种机器学习算法,包括有监督和无监督学习算法,对捕获的数据包进行鉴别。
3数据采集以及特征参数获取
分类器的训练是整个研究的中心和重点,训练分类器的数据是影响分类的准确性的重要因素。为了减少不确定因素,本文用来训练分类器的数据都是通过运行安卓手机应用获取的。获取数据的方法是用电脑建立wifi,将手机连接至电脑,利用电脑的wireshark软件抓取流量包,编写Java程序,提取出所需的三个特征参数,保存为txt文件。本文中为了训练分类器选取了三个特征参数(Time——流持续时间,Packets——流报文总数,Bytes——流字节总数),利用不同应用具有相应的特性的特点,来训练分类器和检测应用。
分类器的训练需要通过大量不同类型应用数据,主要可分为三类。(1)电话应用——由微信软件打电话生成的流参数。(2)语音应用——由微信软件发语音生成的流参数。(3)消息应用——由微信软件发消息生成的流参数。
但是,不同的数据在流特征很小的地方重合度较高,因此,在训练分类器的之前,应该通过数据过滤,将小于某一特定流测度的数据点全部过滤掉,只利用具有代表性特征的数据点去进行训练。在利用训练好的分类器进行判断的时候也可以像这样,对后台的包进行过滤后,再判断其应用类型。
通过图通过排除具有误导性和干扰性的数据后,分类器的精确度会大大提升,为本次实验的成功奠定了基础。
4分类器模型
分类器模型的建立主要是依靠经过处理后分为三类的训练数据以及做出分类的算法。主要是利用图形来表示。
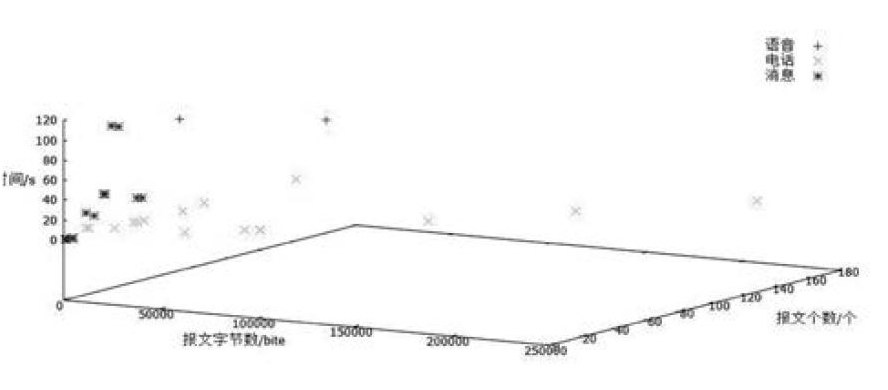
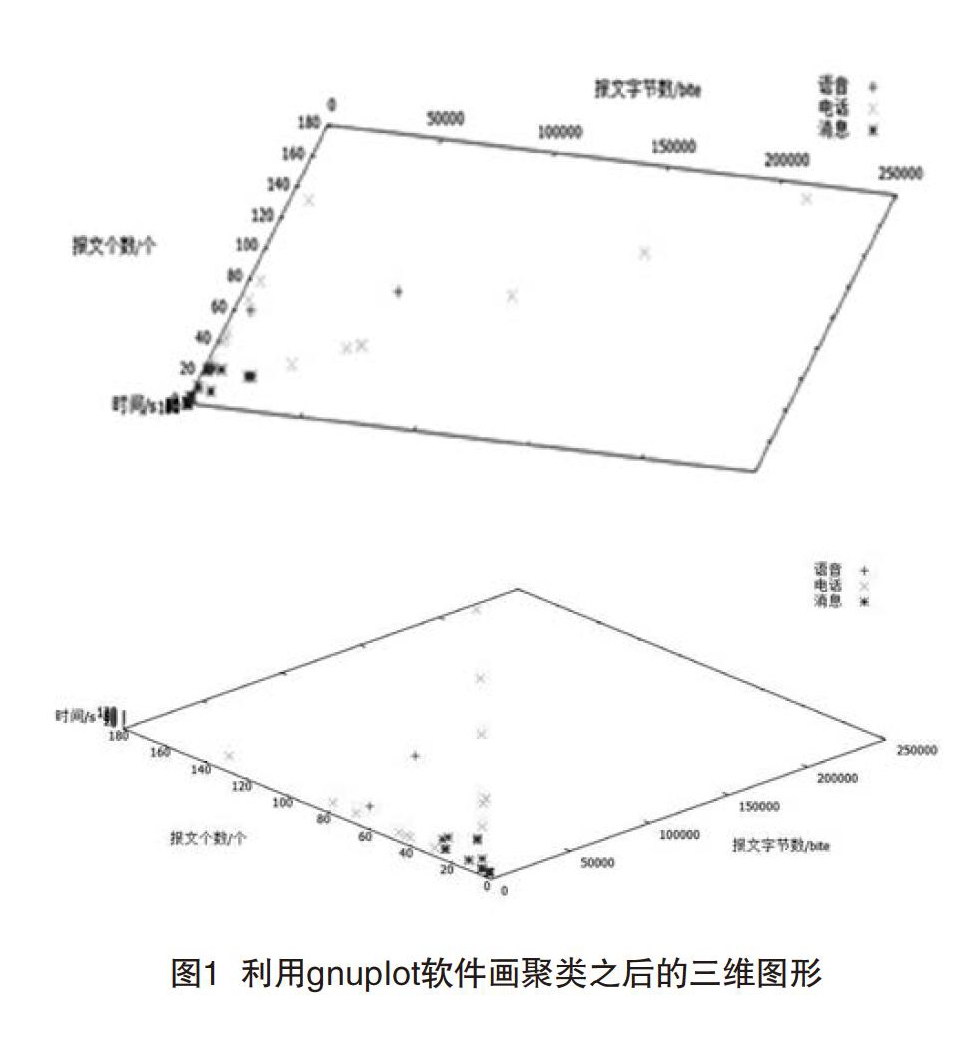
利用gnuplot软件画聚类之后的三维图如图1所示。
可以从图上看出不同类型的数据分散较开,当一组数据过来时,就可以通过观察它的在图中的分布状况,就可以得出它属于哪一类应用。
5结语
文章研究了基于统计学习方法的安卓手机流量分类,从应用这个角度切入,将手机流量大致分为三类一一语音、电话和消息。从上面的实验可以看到不同的统计学习方法具有不同的准确性。
基于统计学习方法的流量分类具有较高的灵活性,操作简便。但是由于基于统计学习的方法对数据的选取要求较高,准确性易受其影响,如果检验采用的流不包含或仅含有较少的具有代表性的报文,将会难以辨别其属于哪一类应用,所以此方法具有一定的局限性。
目前已经做好的分类是仅仅利用了三个流测度来进行划分,而实际应用中流的特征远远不止这些,如果将更多能作为分类依据的特征参数加入到分类的因素中,分类的效果应该会更好、更精确。
