社会化标签系统中基于本体的个性化推荐方法研究
闫婧
摘要:[目的]捕捉用户兴趣的动态性变化,优化个性化信息推荐效果。[应用背景]高效的个性化信息推荐方法可以根据用户行为特征主动为用户提供合适的信息资源,使信息的获取和利用更加快捷、准确。[方法]以“新浪微博”为例,通过挖掘用户及其关注者的微博数据,提取标签,计算二者兴趣相似度及亲密度,确定用户兴趣标签并优化标签描述,从而构建用户个性化“轻量级”本体,使得语义网资源能够准确地投放到用户界面。[结果]有效缓解了信息爆炸式增长所造成的“信息迷航”现象。[局限]微博数据中的杂音(广告转发、多语言描述)、数据不充分等,可能影响标签提取的准确性。关键词:标签本体;个性化推荐;社交网络
1 引言
随着Web2.0的发展,互联网从信息传播的媒介逐渐转变为信息资源共享和社会交流的平台。用户既是信息的使用者,也是信息的创造者。用户和信息的爆炸式增长,为人们带来丰富信息资源的同时,也造成用户难以准确找到感兴趣的资源。高效的个性化信息推荐方法可以根据用户行为特征主动为用户提供合适信息,使信息的获取和利用更加快捷、准确。
社会化标签方法是一种更强调“感知性”的信息组织方法,它由用户自发对资源进行标注所产生的标签组成,为发现用户关注点、进行个性化信息推荐提供了重要的数据基础。与此同时,标签本身所暴露出的描述不规范、无序化、多样性、缺乏语义关系等,很大程度上制约了其在提取个性化信息方面所发挥的作用。而本体是共享概念模型的明确形式化规范说明,能系统地表示概念间的内在语义关系,是语义构建的重要手段,可以有效地弥补上述缺陷。目前,在个性化信息推荐方面有关应用标签和本体的研究相互间比较孤立,缺少将两者结合起来建立模型的思想。本文以主流社交网络“新浪微博”为例,提供了一种在社会化标签系统中基于本体的个性化信息推荐方法,用以捕捉用户兴趣的动态性变化,优化个性化信息推荐效果。
2 相关研究
标签是用户主观地对感兴趣的资源进行发布时所使用的关键词,它在体现用户兴趣取向的同时,也反映了资源本身的特征属性。标签在由用户、标签、资源三者组成的社会化标签系统中扮演着核心角色,是用户与资源之间的桥梁。规范标签的使用、实现标签语义的明确化表述,是降低标签滥用率、提高检索效率的有效手段。
近年来,针对个性化推荐方法的研究不胜枚举。根据推荐算法的不同,YooDonghee等提出了UCTag新型标注方法,设计了基于Web的文件管理系统原型,用户提交某一标签后,根据相应的规则得到的标签本体,系统会自动推荐一系列符合用户兴趣的标签。Kawakubo等提出一种基于Folksonomy的图片本体的自动构建模型,并利用Flickr网站的数据进行实验旧。张云中提出一种基于FCA的半自动构建本体方法,使用造格算法将形式背景转化成相应概念格,再由知识工程师对概念格进行分析,将结果上传到社区,经由社区成员对本体校正或补充得出改进后的本体模型,重新应用到社区中。
目前大多数应用标签系统进行个性化信息推荐的研究集中在推荐算法的设计优化上,没有考虑标签本身的局限性,降低了个性化信息推荐的准确性。本文将本体与标签相结合,用以提高社会化标注系统的推荐效果。
3 研究方法
本文将用户Ul及其关注用户V发布的微博数据作为研究样本,分别对样本进行预处理、提取标签。计算用户Ul的标签集IU1中的每一个兴趣i与用户V标签IV1、IV2……IVn间的相似度及亲密度来判断二者间的社会相关度,从而得到可以代表用户Ul兴趣的标签集。该标签集是从用户及其关注者发布微博的内容角度入手,得到的结果集是无层次结构;而本体是一类规范的集合,具有层次结构和语义性。因而,将标签与本体相结合,对用户兴趣标签集进行规范化、层次化处理、通过分析标签之间的语义关系,建立能够反映用户兴趣的标签概念空间模型,构建用户自身的“轻量级本体”,映射已标记语义网资源的标签集,系统自动将匹配Top-k标签的资源信息反馈给用户。
4 基于本体的个性化信息推荐模型
4.1 构建模型
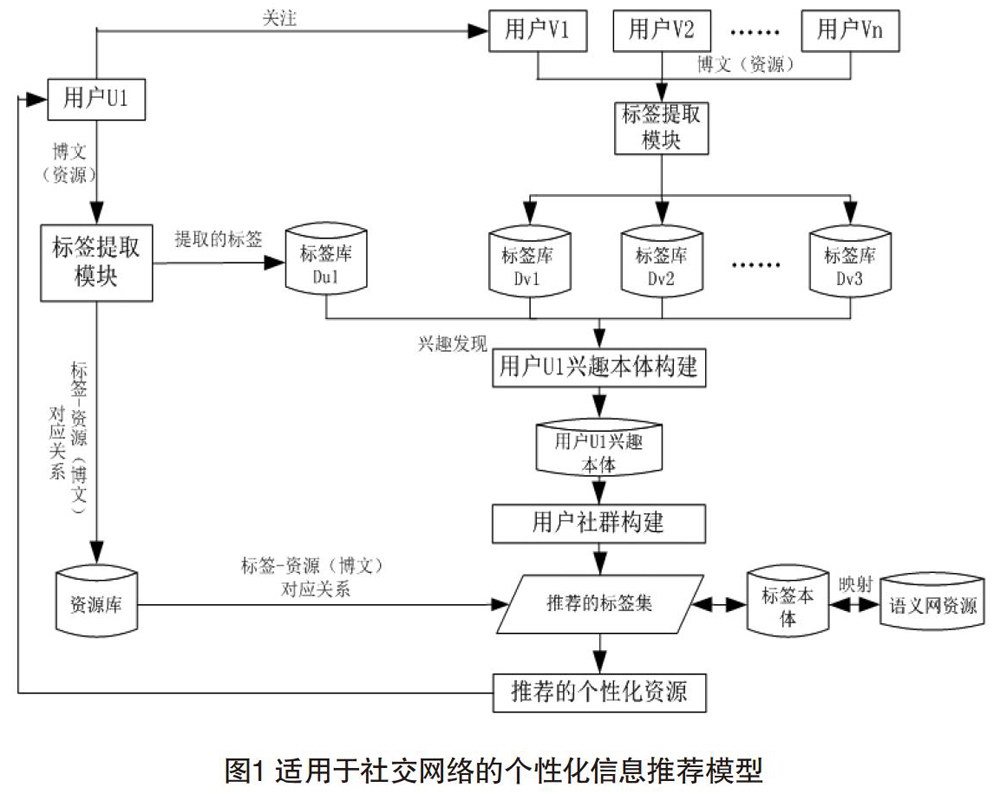
本文将标签系统与本体二者相结合,构建了一种适用于社交网络的个性化信息推荐模型,如图1所示。该模型对社会化标签的含义做了进一步扩展,使标签不再是用户以标注某个资源为目的去标注的,而是用户在进行正常的网络社交活动中,系统自动根据用户的活动数据信息进行提取的,这种方式在很大程度上提高了标签的容错性和准确性,能够实时、准确地监测用户兴趣变化,更加高效地向用户提供所需资源,优化了社交网络中个性化信息推荐服务的效果。
4.2 标签提取模块
如图1所示,根据用户微博内容,提取关键词作为该用户的标签。本文采用哈尔滨工业大学语言技术开发平台LTP对原始微博数据进行句法分析,具体分为:(1)提取微博语句中的无动宾结构时语句的核心谓语以及动宾结构下的核心谓语和宾语的中心词。例如,“我下午去打球”提取“打球”和“他昨天下午去打羽毛球了”中的“打羽毛球”。(2)构建趋向动词表对核心谓语和宾语中心词进行修正,该表包含“上”“下”“来”“去”等趋向动词。例如上例中的“去”这个干扰动词。(3)提取修正有无动宾结构时的核心谓语。(4)将全部提取的核心谓语和宾语构建成动名词关键词表,即该用户的初始兴趣标签集。
4.3 用户兴趣发现模块
评论一个字词在文档中的重要程度,多采用TF-IDF统计方法。其公式为:
tf-idf=tf x logN/n
其中tf表示词语t在文档d中出现的次数,idf=logN/n表示逆文档频率,是一个词语普遍重要性的度量;N表示总文档数;n表示包含词语t的文档数。
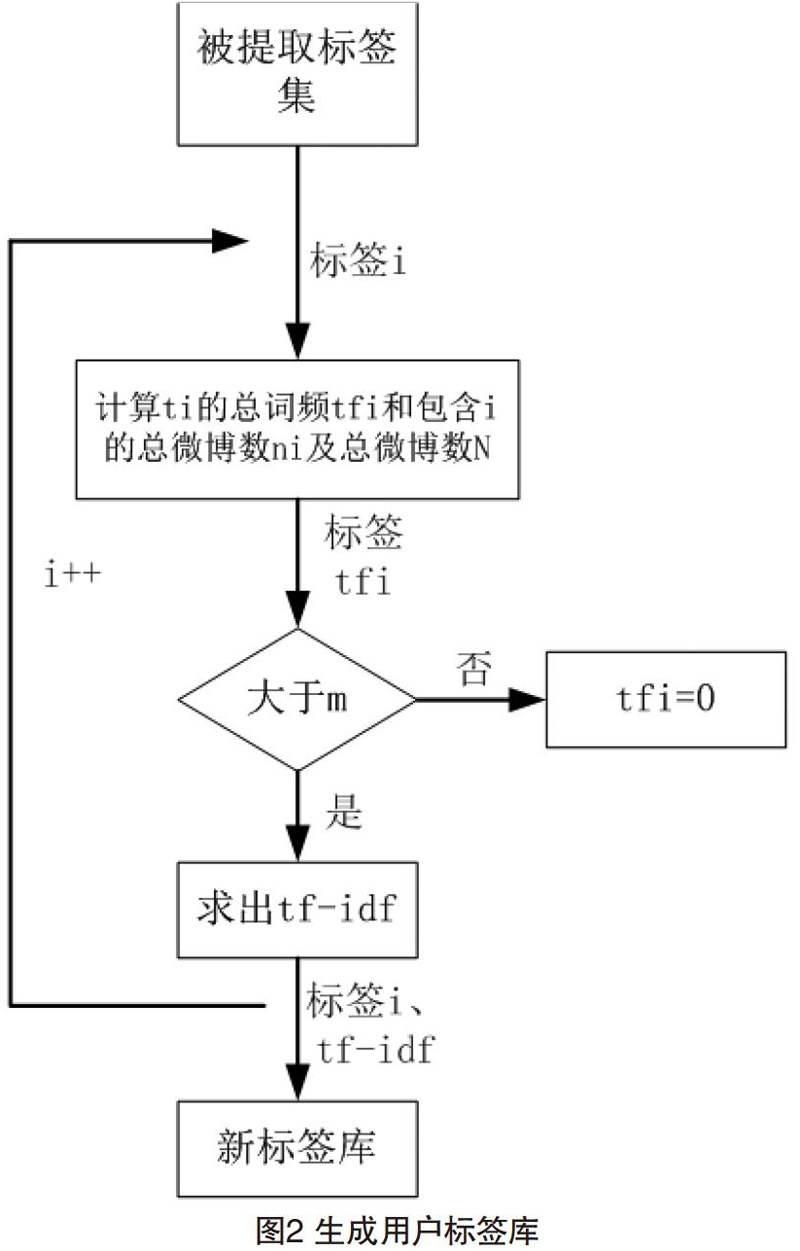
从中不难看出,词语t的重要程度与它出现在当前文档中的频率成正比,与文档集合中出现的频率成反比。这对于微博社交网络而言,可能因为用户发表的微博数量不足,而导致兴趣误判。针对这个问题,本文为tf设定一个阈值m,当tf>m时保留tf,否则tf取“0”,具体流程如图2所示。最后取新标签集中的Top-k为用户U1的标签库Du1,利用同种方式求出用户关注用户的Du2……Dun。
利用标签库信息,求出用户U1的关注用户V与U1标签库中标签的亲密度及相似度,发现用户U1的兴趣集。
4.4 用户兴趣本体构建模块
用户兴趣本体是提供个性化信息服务的基础,其质量直接决定推荐内容的准确性。用户兴趣本体的建立是依托于语义网中的领域本体,在描述概念间关系的同时,也为术语赋予了相应的语义网背景知识,因为有利于知识的复用与共享,改善传统用户模型标签描述随意性的缺陷。构建用户个体的轻量级兴趣本体主要通过对标签进行聚类分析,构造自顶向下的概念树模型。表示用户兴趣的大类表现在高层节点,兴趣的颗粒度划分表现在底层节点,原始提取的用户标签表现在最底层节点。在构建用户兴趣本体时,系统根据用户不同时期发布文章的标签提取出不同的兴趣标签集,这种方法可以及时有效地捕捉用户兴趣的动态性变化,保证兴趣本体的准确性。
4.5 用户社群构建模块
具有相同或相似兴趣的用户聚集而成的群体称为用户社群。利用本文描述的用户兴趣本体,结合社会复杂网络技术、聚类组合等方式可以构建用户间的社群网络。反过来,通过社群网络,系统会根据用户兴趣向用户推荐同类兴趣的社群,供用户可以快速地找到并加入适合自己的群体。
4.6 个性化推荐模块
该模块主要向用户推送相关个性化信息资源。系统根据资源库所提供的资源与标签的对应关系,将用户兴趣集中的个性化标签与语义网中的资源进行语义匹配,得到符合用户兴趣的资源集合,最后将推荐结果在用户主页推荐模块中进行展示,提供给用户。个人应用最广泛的有:好友推荐、兴趣社区推荐、文章推荐等。商业方面,可以进行准确的广告投放,在同等的成本消耗下,使广告的回报率达到最大值。
5 结语
社交网络中的个性化推荐是学界的一个研究热点,但很少有学者将个性化推荐与社会化标签和本体联系起来。文章从用户的直观表述出发,提取文章关键词作为用户兴趣的标签的同时,参考用户关注者的兴趣标签,将二者综合,高效地获取反应用户兴趣的标签,并生成独特的能够反映用户兴趣的轻量级本体。建立了基于本体的个性化信息推荐模型。但是,文章只是对该模型进行了理论上的探讨,并没有在实践中建模验证它的推荐准确度。在接下来的实践过程中,对于微博数据的提取、语义网中资源的标注等问题,都是值得进一步去关注和解决的。
