一种Hadoop 集群限量使用模型
汪健 蔡丽

摘要:Hadoop是当今主要的云平台之一,采用Kerberos作为身份认证机制实现单点登录,底层以SLA实现访问授权。该模型可提供基本的安全访问控制,但无法监控用户通过认证授权后的行为。该文提出了一种基于访问统计的控制模型,以限制用户不能过量占用Hadoop集群计算能力。
关键词:Hadoop;访问控制;限量使用;LDAP
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2016)13-0047-02
随着当今社会的发展,所需要处理的信息量越来越大,Hadoop[1]作为一种高可靠、高可用、低成本的集群环境,已经逐渐成为并行处理事实上的标准。致力于高效处理数据的初衷,Hadoop的开发及维护者最初并未将安全问题置于第一位,Hadoop集群管理者将内网和所有主机置于一个绝对安全的封闭环境,所有作业只能由管理员运行,也就是说,基本将Hadoop集群视为与外界隔绝的一台“超级计算机”。随着Hadoop的发展,各种新的应用逐渐出现于Hadoop生态圈中,如Hive、Storm、Hbase等,而不仅仅只限于最初的HDFS和MapReduce[2],单个管理员难以管理越来越多的应用;同时作为一种稀缺资源,开放Hadoop集群的计算能力给多个部门或用户使用也逐渐成为必然。
然而,开放Hadoop集群也同时带来了安全风险[3],因此Hadoop在身份认证方面,采用了Simple(Linux用户/组身份认证)和Kerberos(单点登录)两种方式[4]。在身份认证通过后,对于服务的访问可打开SLA(Service Level Authorization)开关以控制哪些用户可以访问某种服务[5]。Hadoop提供了基本的认证及授权保护,但并未对用户通过授权之后的行为进行限制,一个“贪心”甚至是恶意的用户可能会提交大量的作业或是HDFS操作,从而挤占宝贵的集群资源,使其他用户不能公平地来分享集群。Hadoop YARN中的Fair Scheduler作业调度机制[6]尽可能保证当前每个用户的作业都获得等量的资源份额,可在一定程度上解决该问题,但不能从根本上避免此类问题。因此,我们提出了一种基于“消费”的权限控制手段,在对Hadoop底层机制仅作少量修改、不影响集群运行效率的前提下,统计每个用户在使用集群时耗费的计算资源,从而限制每个用户不能过度的使用集群资源。
1 Hadoop现有的认证授权过程
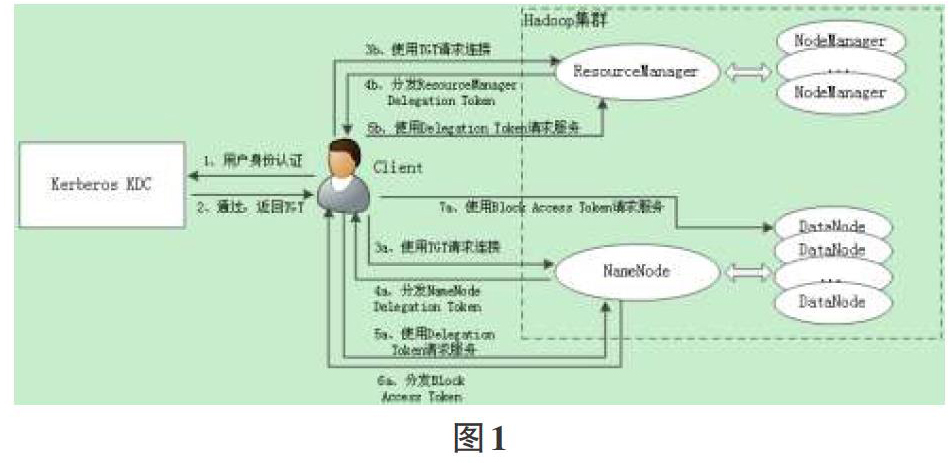
对于开放共享的Hadoop集群,Simple认证方式太过简单,无法起到保护作用,必须使用Kerberos单点登录。Hadoop中基于Kerberos认证的访问过程[7]如图1所示。
1)客户端访问Hadoop服务前,先向Kerberos KDC(Key Distribution Center,密钥分发中心)验证身份。
2)若身份认证通过,KDC返回一个TGT票据(Ticket Granting Ticket),单点登录成功。客户端今后可持该票据向其他服务器表明身份并请求服务。在Hadoop集群中,客户端接下来可向NameNode或ResourceMananger发出服务请求。
先看一下对HDFS的访问流程。
3a. 客户端持TGT与NameNode进行通信,双方互相证明身份,这里双方均需与KDC交互,该过程不做详述。
4a. 如果每次验证都使用TGT,开销较大,因此NameNode第一次验证客户端后,便向向客户端分发一个NameNodeDelegation Token,以后客户端就可以使用开销较小的Token来证明身份。
5a. 客户端接着使用Delegation Token向NameNode请求服务,例如需要对HDFS中某个文件进行读/写,向NameNode发出询问。
6a. NameNode根据MetaData映射表得出文件信息,包括文件对应的Block块以及Block块对应的DataNode信息等,并生成一个Block Access Token分发给用户。
7a. 用户持Block Access Token向相应的DataNode请求服务,DataNode执行读写请求并返回结果。
客户端提交/查询/中止作业需要与ResourceManager进行交互,流程与上类似。
3b. 客户端持TGT与ResourceManager进行通信,双方互相证明身份。
4b. ResourceManager向客户端分发一个ResourceManager Delegation Token。
5b. 客户端使用Delegation Token向ResourceManager发起作业请求,ResourceManager作为资源调度器,分配一个适当的Container运行该作业的ApplicationMaster,再由ApplicationMaster向ResourceManager请求新的Container以运行子任务。客户端只与ResourceManager进行交互。
Hadoop中提供了最基本的系统级权限控制SLA,SLA通过设定权限控制表ACL的方式对Client-DFS、Client-Datanode、Datanode-Namenode等之间的访问进行控制。SLA可通过core-site.xml文件中的hadoop.security.authorization开关打开,并在hadoop-policy.xml文件中设置权限。客户端在单点登录并获取Delegation Token后可以发起请求,ResourceManager/NameNode检查ACL列表核实用户身份是否有请求权限,通过后再调用相关行为函数。在SLA之上,各种应用可具备进一步的访问控制,例如HDFS提供了类似于POSIX的文件和目录权限管理DFS Permission;MapReduce可打开Access Control on Job Queues开关以配置多个队列以及每个队列的的权限;HBase可在表上对用户行为(RWXCA五种权限)进行授权等等。
2 基于访问统计的增强控制模型
为了限制用户对Hadoop集群的过量使用,我们提出了一种对Hadoop中现有访问控制进行增强的模型,如图2所示。
在该模型中,我们引入了用户可用余额(User AvailableQuota,UAQ)的概念,并在集群中增加一个LDAP服务器来存储所有用户的UAQ和其他相关属性。与Hadoop中的其他节点一样,LDAP服务器也是通过keytab文件预先向KDC注册身份。集群中其他服务器通过基于Kerberos身份验证的SASL-GSSAPI接口来访问LDAP目录服务[8]。
如前述可知,客户端发起请求时,ResourceManager/NameNode先查询ACL列表,若通过,再调用相应处理函数。在这中间我们插入一个判定,当ACL权限审核通过后,根据请求的类型,可能还要向LDAP服务器查询并取回用户UAQ相关信息,若LDAP不存在该用户或UAQ不足,则拒绝此请求。有些请求不需要访问LDAP来取得权限,例如作业的杀死和查询。
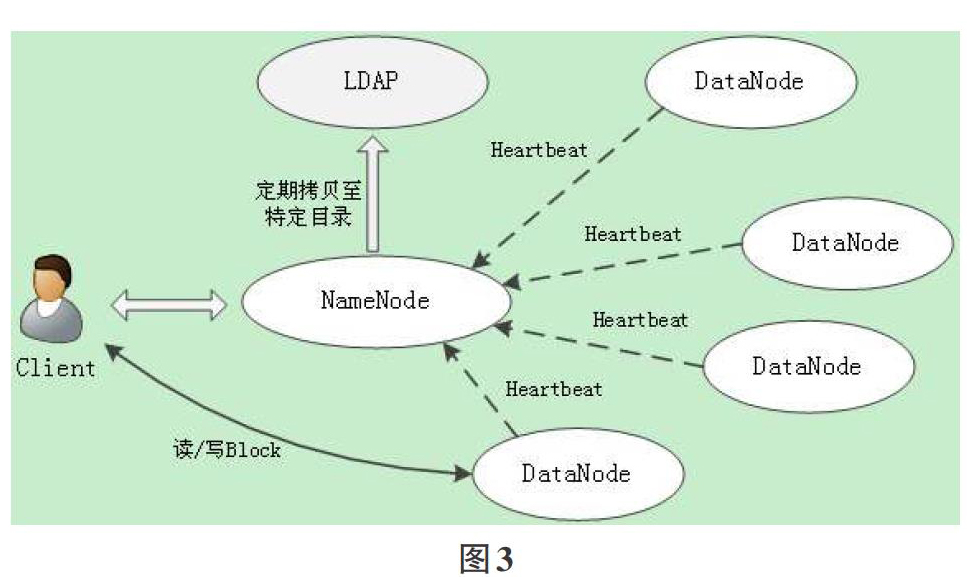
ResourceManager/NameNode除了检查用户UAQ外,还要承担收集用户所消耗的计算资源数量工作,并适时地将该信息发送到LDAP服务器,由LDAP服务器负责更新用户UAQ。NameNode的收集工作如图3所示。
在前面分析可知,客户端先向NameNode发起文件读/写请求,NameNode从MetaData映射表中查询该文件分布的Block块和所在的DataNode,生成Block Access Token分发给客户端。客户端在每次读/写DataNode上的block时,DataNode在UserGroupInformation上下文中可取得用户信息,将此次所做操作和块号存入文件块访问记录BlockAccessRecord={User,Request,BlockId}。由于每个DataNode会周期地向NameNode发送心跳信息(Heartbeat),因此我们在心跳信息中,将这段周期内记录下的所有用户的文件块访问记录表List
ResourceManager的收集工作与NameNode类似。ResourceManager以Container的形式来分配资源,每个Container对应一个RMContainer状态机对象用于维护Container的生命周期。NodeManager通过心跳机制周期地将Container信息汇报给ResourceManager,ResourceManager从而可以修改RMContainer中的状态。RMContainer状态机中共有9种状态,通过修改RMContainer接口的实现类RMContainerImpl,记录状态转换时的时刻,可以得到状态-状态的间隔时间。
为了收集用户消耗的计算资源,这里我们可记录Container从实际分配到任务结束的时间,即ACQUIRED到COMPLETED状态的时间,ResourceManager从RMContainer对象中读取所需信息,生成Container使用记录ContainerRecord={User,ContainerId,NodeId,Resource{CPU,Memory},Period},并以文件形式存放在本地磁盘中,定期将该文件拷贝至LDAP服务器特定目录。若该Container因某种原因未能正常结束,可视为未占用资源。
LDAP服务器作最后的统计工作,每隔一段时间从上传文件中读取BlockAccessRecord和ContainerRecord记录,从而统计每个用户在这段时间内消耗的资源量,并刷新用户的UAQ属性。UAQ消耗后需要恢复,用户才能再次使用Hadoop资源,可以设置每天恢复一定的数量,或者由管理员手动恢复。
3分析
该模型并未对Hadoop底层机制做任何修改,仅在ResourceManager和NameNode正常工作过程中加入少许记录功能以及增加与LDAP进行通信环节,因此不会对Hadoop的性能有影响。LDAP具有良好的查询性能,基于目录的管理也较为方便,在大规模集群管理中应用较多,Hadoop中的Hive、Impala等都可以配置LDAP工作,因此这里选用LDAP来管理用户UAQ也方便将来Hadoop集群的集中管理。
在模型中,LDAP中的UAQ并不是实时更新的,这不仅是为了减少与LDAP的通信,更重要的是防止作业在执行中因为UAQ不足而中断。在此前提下,UAQ可以为负值,意味着用户可以预支额度,在当前作业完成之后,需要等待UAQ恢复才能进行下一次作业的提交。
在系统搭建时,需要增加一台LDAP服务器,NameNode和ResourceManager服务器需要安装LDAP客户端环境,所增加的安装工作并不多。传送的数据量较小,因此也不会对网络流量造成影响。
存在的问题主要在于所耗费资源量的计算标准,对于Container以占用的CPU、内存量和时间来衡量,由于ResourceManager对CPU和内存资源的分配仅是最大阀值而非实际值,而操作系统线程实际运行情况未可知,这样对实际的耗费量会有一定误差。
4 结束语
Hadoop安全机制较为简陋,无法满足多用户下的安全保护需求。本文通过提出基于访问统计的限量使用模型,在一定程度上对用户行为进行限制,增强了现有安全模型,减轻Hadoop管理工作。今后还可在此基础上进一步实现更细粒度的资源使用统计。
参考文献:
[1] Apache Hadoop [EB/OL].http://hadoop.apache.org,2016-2-13
[2] Dean J, GhemawatS. MapReduce:Simplified data processingon large clusters[J]. Communications of the ACM, 2008, 51(1).
[3] Zissis D,Lekkas D. Addressing cloud computing security issues[J]. Future Generation Computer Systems, 2012, 28(3).
[4] 朱建波, 李萍, 于炯,等. 改进的Kerberos协议在HDFS环境下的研究[J]. 计算机工程与设计, 2014, 35(10).
[5] Apache Hadoop. Service Level Authorization Guide [EB/OL]. (2014-11-14).http://hadoop.apache.org/docs/r2.5.2/hadoop-proje ct-dist/hadoop-common/ServiceLevelAuth.html.
[6] Amr M Elkholy, Elsayed A H,Sallam.Self adaptiveHadoop scheduler for heterogeneous resources[C]. Computer Engineering & Systems(ICCES), 2014, 9th International Conference on, 2014.
[7] 刘莎, 谭良. Hadoop云平台中基于信任的访问控制模型[J]. 计算机科学, 2014, 41(5).
[8] 郑之华. 基于SASL框架下身份认证机制的研究[J]. 长春大学学报, 2015, 25(2).
