虚拟语音会议系统设计与实现
赵文杰+陈磊+郑全普+刘镇瑜+霍烁烁
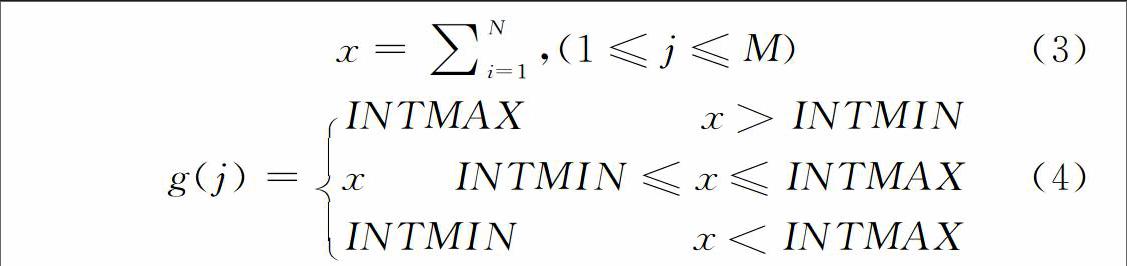
摘要:
将虚拟声技术运用于网络语音会议系统中,利用头相关传递函数对单音频信号进行处理,使之扩展为两路立体声信号,从而对不同的参会者虚拟出带有不同方位感的虚拟声像,模拟出圆桌会议的声像效果,并设计实现了一个简单的基于Windows平台的网络虚拟会议系统。主观测听结果显示,所有测听者均认为添加虚拟声功能后用户体验更好,大部分测听者认为该功能将混乱情况下的语音进行了方位感的梳理,增强了鸡尾酒会效应,使测听人更加容易辨别说话人,也更容易辨识说话人所讲内容。
關键词:虚拟声;头相关传输函数;网络语音通话系统;网络虚拟会议室
DOIDOI:10.11907/rjdk.171849
中图分类号:TP319
文献标识码:A文章编号文章编号:1672-7800(2018)001-0132-03
Abstract:In this paper, the virtual sound technology applied to the network voice conferencing system, the use of head-related transfer function of single-audio signal processing, so that it is extended to two stereo signals, so that different participants virtual out with a different sense of virtual Audio and video, simulation of the round table audio and video effects, and designed to achieve a simple Windows platform based on the virtual network virtual conference system. Subject audiometry results show that all the participants are considered to add virtual sound function after the user experience better, most of the listener that this feature will be chaotic voice of the location of the carding, and enhance the cocktail effect, so that listeners are more likely to identify the speaker, but also easier to identify the speakers content.
Key Words:virtual sound; head-related transfer function; network virtual conference room
0引言
随着互联网和多媒体技术的发展,异地召开语音会议成为现实,且语音会议业务作为一种便利的通信手段,已经被大多数政府部门和企事业单位所接受和采用。目前,立体声网络电话会议系统中通常是将双麦克风所录数据经过网络发送至客户端,再使用多个扬声器进行播放,在两人以上会议中,多人同时发言时会出现声像重叠情况,若发言人数更多将会造成声像重叠、言语混杂,造成与会人员无法听清发言人声音的问题,一些语音会议系统采用的方法是限制同时发言人数。本系统将虚拟声技术运用于语音会议系统中,仅需要一个麦克风录取声音,在播放前将各与会人员的声音虚拟到各用户自定义的方位,进行立体声播放,便可以制造立体声效果。与会者可以自行设置每个发言人的位置,系统根据用户设置,虚拟出一个现实会议中的圆桌会议效果,使语音会议更加真实,同时可在一定程度上解决多人同时发言时的声像混叠问题。
1系统总体设计
1.1系统设计方案
本文设计的局域网虚拟声会议系统主要包含如下功能:①客户端用户向服务器发出登录、注销请求并完成登
陆和注销;②客户端用户采集语音数据,并通过降采样后通过网络传输;③客户端用户可以向其它客户端发送文字信息;④客户端提供可视化界面,用户可以设置其他各参会人的位置信息,系统根据各参会人员的位置信息进行虚拟声的合成和播放;⑤服务器完成参会人员控制,包括用户登录、注销验证及文字、语音信息转发。
1.2系统结构
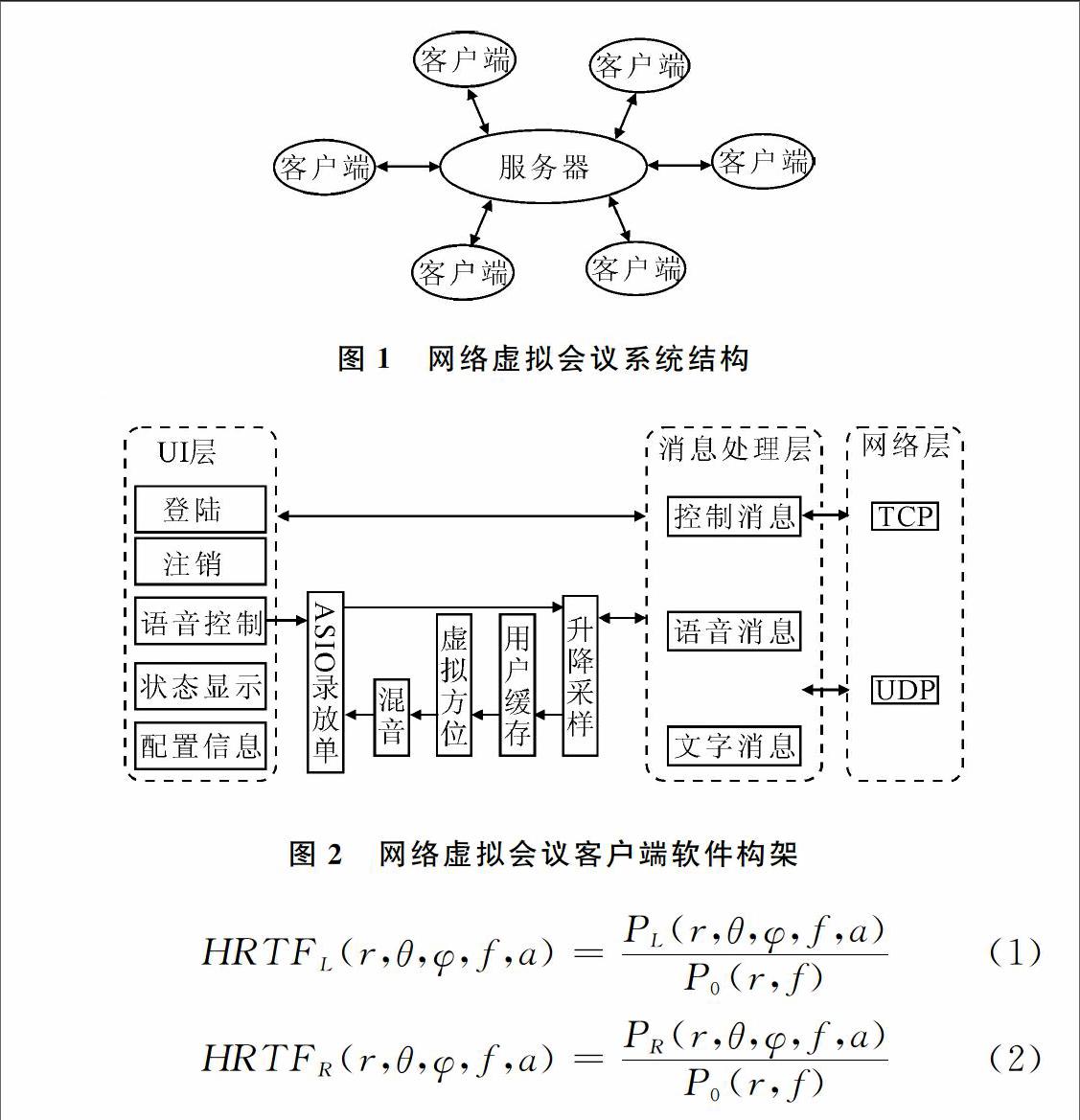
系统主要由服务器和客户端两部分构成,拓扑结构为星型拓扑结构,采用主从式构架,即客户端服务器模式[1]。系统结构如图1所示。
本系统中,服务器端主要功能为验证用户登陆信息,并将已验证用户的文字信息、语音信息等转发到其它各在线客户端。系统客户端主要功能为发送登录请求,验证通过后获取所有在线用户信息,录取语音并发送语音信息至服务器,收到服务器转发其它客户端语音信息后根据客户设置各与会人员位置信息,虚拟出带有方位感的立体声语音信息,进行混音播放。客户端软件构架如图2所示。
2系统关键模块设计
2.1虚拟声合成模块
心理声学研究表明,声源产生的(直达声)声波经头部等散射后到达双耳,产生双耳时间差(ITD)和声级差(ILD)。听觉系统利用这些双耳差并与过去的听觉系统经验进行比较,从而判断声源方向。而头部及耳廓等对声波的散射作用以及由此产生的双耳差可用头相关传递函数(Headrelated Transfer Function简称HRTF)表达[2]。
HRTF定义为自由场情况下简谐点声源在左右耳处产生的频域复数声压和头移开后声源在原头部中心位置处的频域复数声压之比[3]。
PL、PR分别是简谐点声源在左、右耳产生的频域复数声压,P0是头移开后在原点中心位置处的频域复数声压。r为声源距离头部中心的距离,θ为方位角,φ为仰角,f为声波的频率,a为个性化因素。它包含了人耳对声源定位所需的双耳时间差、双耳声级差等重要信息。获取HRTF的方法有实验测量和理论计算两种,本系统采用本实验室试验测量的仿真头模BHead210(由中国传媒大学依据中国成年人头面部尺寸的国家标准设计与制作)水平面一周的HRTF数据。
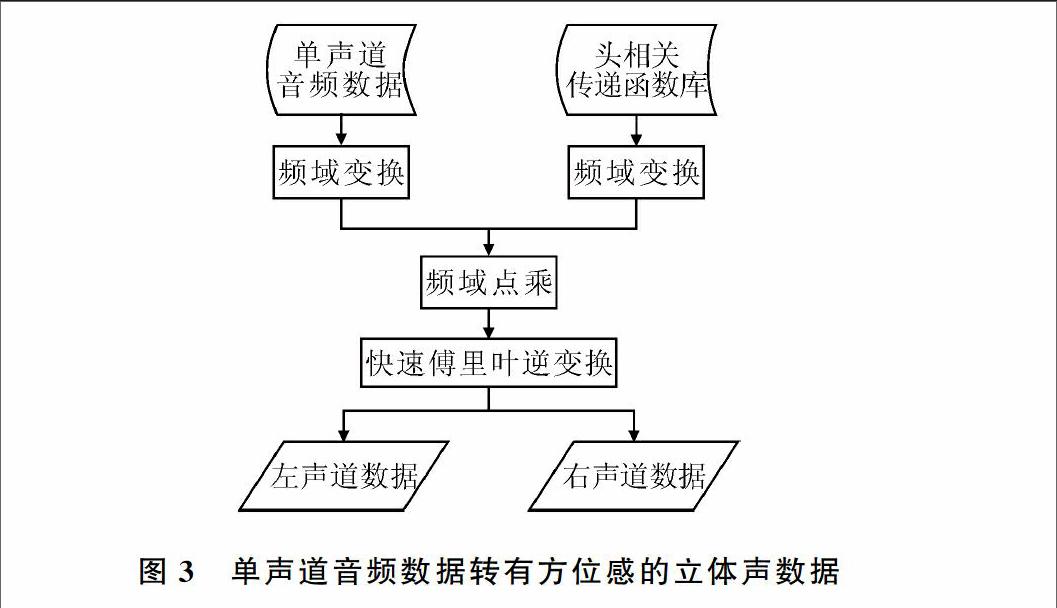
有了头相关传递函数库,将单声道音频数据转换为带方位的立体声数据如图3所示。
生成虚拟声的主要步骤如下:①加载头相关传递函数库,这一步是前提,必须将文件存储形式的头相关传递函数库全部加载到内存中,本系统仅需要水平面一周的头相关传递函数库内容,大小为294 912字节。该步骤需在系统初始化时一同初始化,将全部水平面库一次性载入内存,是为了在程序运行过程中,用户改变方位后能够更快地拿到相应角度的头相关传递函数,不用再重新读取文件而造成系统反应时间增加;②将存放为时域的相应角度的头相关传递函数作频域变换,之所以要变换到频域,是为了提高计算效率,且此步骤每次变换角度后只需作一次变换即可;③将音频数据进行频域变换,此处应注意,每次音频点长度应适中,且必须为512的整数倍。ASIO每次取到的录音数据以及网络发送和接收到的数据长度都是1 024个点,故在此选用1 024个点进行频域转换;④将频域转换后的音频数据分别与相应角度的频域转换后的左右耳头相关传递函数进行频域点乘,分别得到与原音频长度相同的立体声数据。将计算所得音频数据放入ASIO声卡驱动缓存即可播放。
2.2音频驱动模块
音频输入输出模块是系统和声卡的接口,负责系统的双通道立体声录放。这里使用的音频流输入输出接口(Audio Stream Input Output,简称ASIO)(本系统使用的ASIO4ALL是由Wuschel开发出来的一款绿色小巧的ASIO驱动)支持44 100Hz和48 000Hz采样率的声音信号。ASIO接口绕过Windows操作系统对声卡I/O的控制,直接驱动PC声卡,从而具有较高的响应速度和较低的录放延迟。此外,ASIO技术还支持最多32通道录放音功能。
本系统将ASIO的初始化、启动录放、获取录音数据、放入放音数据、停止录放、释放资源等操作封装到多个函数中。系统开始运行之后ASIO随即进行初始化:设定录放音通道数、一次录放音的帧长、音频I/O采样率等。ASIO启动录放后将在连续录取近端声音的同时,播放从远端接收到的声音数据,由于ASIO内部录音缓冲切换速度极快,近端的录音数据块必须及时保存;同时接收到的远端声音数据需要被保存到一个声音接收缓存中,缓存的长度和初始指针位置必须严格设定,避免ASIO放音时由于网络拥塞等原因导致话音断断续续。
2.3网络通信模块
网络通信模块主要负责客户端和服务器之间的数据交换。其主要任务是发送和接收登录、注销、开始语音、结束语音等命令信息,以及文字和语音信息。
系统采用Windows操作系统提供的网络套接字(SOCKET)接口实现实时双端网络通信。SOCKET接口通过IP地址和端口定位远端,可在面向连接的传输控制协议(TCP)和面向无连接的用户数据包协议(UDP)之上顺利工作。考虑到系统客户端与服务器端命令信息需要无差错可靠传输以及TCP面向连接的可靠性特点,本系统使用TCP传输系统间命令信息。考虑到音频数据的实时性要求和可少量丢帧的限制及UDP协议本身的特点,本系统采用UDP协议传输语音信息[4]。
2.4混音模块
混音算法的最终目的是将输入的多路语音混合成一路语音输出,但由于实际应用环境不理想,在算法设计过程中需要着重考虑质量与效率兼顾的问题。由于语音会议中传输的是实时语音,如果网络延时过大或者需要处理时间过长就会影响到会议参与者的正常交流。网络时延问题非算法所能解决,这要求算法在特定的网络环境下保持较高的效率,使延时保证在用户可以忍受的范围内,同时语音质量也不能太差[5]。因此,混音算法需要同时兼顾语音质量和算法效率,需要在二者之间做好平衡。基于对常见混音算法的了解及实验验证,并考虑到会议系统中同时可分辨的发言人数有限,本系统的混音处理使用钳位法[6]。
钳位法是效率最高的混音算法之一,基本做法如同线性叠加法,仅在混音过程中对样本的溢处部分进行处理,将超过上限的样本值用上限值代替,超过下限的样本值用下限代替[7]。例如,用32bit的存储空间保存一个采样值,即C语言中的int类型(int最大值表示为INTMAX,最小值表示为INTMIN),处理叠加方法如下:
在溢出情况很少发生的情况下,此方法输出波形保真度高,语音质量良好。
3实验结果分析
经过对16位测听人员的主观测听结果分析可知,虚拟声功能在本系统中对方位感的模拟是有效的,100%的人体会到了方位感,且均认为此功能的添加对用户体验效果良好,但声像方位的准确度存在一定差距,这与头中定位有很大关系,若要提高准确度,需增加混响等算法辅助,此问题有待后续研究。
对虚拟声功能在2~4人同时讲话时辨识度的测听中,尤其对2~3人同时讲话时,100%的测听者选择了好于无虚拟声功能时的效果;4人同时讲话时,75%的测听者选择了好于无虚拟声功能时的效果,25%的测听者认为没有明显效果;在添加虚拟声功能后音质变化上,仅有1人认为音质变差了,其余15人认为并无明显变化,认为无明显变化的占总体的93.75%。总体评价中,100%的人认为添加虚拟声功能后用户体验更好,其中43.75%的测听者认为此功能的用户体验很好,大部分测听者认为此功能将混乱情况下的语音进行了方位感梳理,增强了鸡尾酒会效应,使测听人更加容易辨别说话人,也更容易辨识说话人所讲内容。
4结语
本系统旨在将虚拟声技术运用于语音会议系统中,以尽量增加与会者的现场感和真实感,并在一定程度上解决多人同时发言造成的声像混叠问题。因此,本系统不考虑会议系统的回声抵消问题和多扬声器播放时为保证正确声像而带来的串声消除问题。
虚拟声技术的运用,增加了系统的计算复杂度和系统设计难度,且由于本系统客户端需要获取每个参会人员的声音,这考验着网络的负载能力,因此就目前而言,本系统仅适用于召开少于10人的语音会议。但从未来趋势看,语音会议系统的复杂度越来越高,在基本功能实现的基础上增加与会者的现场感和真实感将是语音会议系统的发展方向。
参考文献:
[1]罗伟.大容量VoIP电话会议系统的研究与实现[D].西安:西安电子科技大学,2008.
[2]谢菠荪.头相关函数与虚拟听觉[M].北京:国防工业出版社,2007.
[3]谢菠荪,管善群.虚拟声技术及其应用(上)[J].应用声学,2004,23(4):43-47
[4]沈鑫剡.多媒體传输网络与VoIP系统设计[M].北京:人民邮电出版社,2005.
[5]殷晓虎,周娟,张静.基于会议系统混音算法的研究与应用[J].电声技术,2014,38(3):53-55.
[6]OHSHIMA K.A teleconferencing system with high-speed stream mixing for voice over IP[Z]. Wikipedia,2004.
[7]蒙肖雷.基于SIP的企业语音通话系统设计与实现[D].西安:西安电子科技大学,2014.
(责任编辑:孙娟)
摘要:
将虚拟声技术运用于网络语音会议系统中,利用头相关传递函数对单音频信号进行处理,使之扩展为两路立体声信号,从而对不同的参会者虚拟出带有不同方位感的虚拟声像,模拟出圆桌会议的声像效果,并设计实现了一个简单的基于Windows平台的网络虚拟会议系统。主观测听结果显示,所有测听者均认为添加虚拟声功能后用户体验更好,大部分测听者认为该功能将混乱情况下的语音进行了方位感的梳理,增强了鸡尾酒会效应,使测听人更加容易辨别说话人,也更容易辨识说话人所讲内容。
關键词:虚拟声;头相关传输函数;网络语音通话系统;网络虚拟会议室
DOIDOI:10.11907/rjdk.171849
中图分类号:TP319
文献标识码:A文章编号文章编号:1672-7800(2018)001-0132-03
Abstract:In this paper, the virtual sound technology applied to the network voice conferencing system, the use of head-related transfer function of single-audio signal processing, so that it is extended to two stereo signals, so that different participants virtual out with a different sense of virtual Audio and video, simulation of the round table audio and video effects, and designed to achieve a simple Windows platform based on the virtual network virtual conference system. Subject audiometry results show that all the participants are considered to add virtual sound function after the user experience better, most of the listener that this feature will be chaotic voice of the location of the carding, and enhance the cocktail effect, so that listeners are more likely to identify the speaker, but also easier to identify the speakers content.
Key Words:virtual sound; head-related transfer function; network virtual conference room
0引言
随着互联网和多媒体技术的发展,异地召开语音会议成为现实,且语音会议业务作为一种便利的通信手段,已经被大多数政府部门和企事业单位所接受和采用。目前,立体声网络电话会议系统中通常是将双麦克风所录数据经过网络发送至客户端,再使用多个扬声器进行播放,在两人以上会议中,多人同时发言时会出现声像重叠情况,若发言人数更多将会造成声像重叠、言语混杂,造成与会人员无法听清发言人声音的问题,一些语音会议系统采用的方法是限制同时发言人数。本系统将虚拟声技术运用于语音会议系统中,仅需要一个麦克风录取声音,在播放前将各与会人员的声音虚拟到各用户自定义的方位,进行立体声播放,便可以制造立体声效果。与会者可以自行设置每个发言人的位置,系统根据用户设置,虚拟出一个现实会议中的圆桌会议效果,使语音会议更加真实,同时可在一定程度上解决多人同时发言时的声像混叠问题。
1系统总体设计
1.1系统设计方案
本文设计的局域网虚拟声会议系统主要包含如下功能:①客户端用户向服务器发出登录、注销请求并完成登
陆和注销;②客户端用户采集语音数据,并通过降采样后通过网络传输;③客户端用户可以向其它客户端发送文字信息;④客户端提供可视化界面,用户可以设置其他各参会人的位置信息,系统根据各参会人员的位置信息进行虚拟声的合成和播放;⑤服务器完成参会人员控制,包括用户登录、注销验证及文字、语音信息转发。
1.2系统结构
系统主要由服务器和客户端两部分构成,拓扑结构为星型拓扑结构,采用主从式构架,即客户端服务器模式[1]。系统结构如图1所示。
本系统中,服务器端主要功能为验证用户登陆信息,并将已验证用户的文字信息、语音信息等转发到其它各在线客户端。系统客户端主要功能为发送登录请求,验证通过后获取所有在线用户信息,录取语音并发送语音信息至服务器,收到服务器转发其它客户端语音信息后根据客户设置各与会人员位置信息,虚拟出带有方位感的立体声语音信息,进行混音播放。客户端软件构架如图2所示。
2系统关键模块设计
2.1虚拟声合成模块
心理声学研究表明,声源产生的(直达声)声波经头部等散射后到达双耳,产生双耳时间差(ITD)和声级差(ILD)。听觉系统利用这些双耳差并与过去的听觉系统经验进行比较,从而判断声源方向。而头部及耳廓等对声波的散射作用以及由此产生的双耳差可用头相关传递函数(Headrelated Transfer Function简称HRTF)表达[2]。
HRTF定义为自由场情况下简谐点声源在左右耳处产生的频域复数声压和头移开后声源在原头部中心位置处的频域复数声压之比[3]。
PL、PR分别是简谐点声源在左、右耳产生的频域复数声压,P0是头移开后在原点中心位置处的频域复数声压。r为声源距离头部中心的距离,θ为方位角,φ为仰角,f为声波的频率,a为个性化因素。它包含了人耳对声源定位所需的双耳时间差、双耳声级差等重要信息。获取HRTF的方法有实验测量和理论计算两种,本系统采用本实验室试验测量的仿真头模BHead210(由中国传媒大学依据中国成年人头面部尺寸的国家标准设计与制作)水平面一周的HRTF数据。
有了头相关传递函数库,将单声道音频数据转换为带方位的立体声数据如图3所示。
生成虚拟声的主要步骤如下:①加载头相关传递函数库,这一步是前提,必须将文件存储形式的头相关传递函数库全部加载到内存中,本系统仅需要水平面一周的头相关传递函数库内容,大小为294 912字节。该步骤需在系统初始化时一同初始化,将全部水平面库一次性载入内存,是为了在程序运行过程中,用户改变方位后能够更快地拿到相应角度的头相关传递函数,不用再重新读取文件而造成系统反应时间增加;②将存放为时域的相应角度的头相关传递函数作频域变换,之所以要变换到频域,是为了提高计算效率,且此步骤每次变换角度后只需作一次变换即可;③将音频数据进行频域变换,此处应注意,每次音频点长度应适中,且必须为512的整数倍。ASIO每次取到的录音数据以及网络发送和接收到的数据长度都是1 024个点,故在此选用1 024个点进行频域转换;④将频域转换后的音频数据分别与相应角度的频域转换后的左右耳头相关传递函数进行频域点乘,分别得到与原音频长度相同的立体声数据。将计算所得音频数据放入ASIO声卡驱动缓存即可播放。
2.2音频驱动模块
音频输入输出模块是系统和声卡的接口,负责系统的双通道立体声录放。这里使用的音频流输入输出接口(Audio Stream Input Output,简称ASIO)(本系统使用的ASIO4ALL是由Wuschel开发出来的一款绿色小巧的ASIO驱动)支持44 100Hz和48 000Hz采样率的声音信号。ASIO接口绕过Windows操作系统对声卡I/O的控制,直接驱动PC声卡,从而具有较高的响应速度和较低的录放延迟。此外,ASIO技术还支持最多32通道录放音功能。
本系统将ASIO的初始化、启动录放、获取录音数据、放入放音数据、停止录放、释放资源等操作封装到多个函数中。系统开始运行之后ASIO随即进行初始化:设定录放音通道数、一次录放音的帧长、音频I/O采样率等。ASIO启动录放后将在连续录取近端声音的同时,播放从远端接收到的声音数据,由于ASIO内部录音缓冲切换速度极快,近端的录音数据块必须及时保存;同时接收到的远端声音数据需要被保存到一个声音接收缓存中,缓存的长度和初始指针位置必须严格设定,避免ASIO放音时由于网络拥塞等原因导致话音断断续续。
2.3网络通信模块
网络通信模块主要负责客户端和服务器之间的数据交换。其主要任务是发送和接收登录、注销、开始语音、结束语音等命令信息,以及文字和语音信息。
系统采用Windows操作系统提供的网络套接字(SOCKET)接口实现实时双端网络通信。SOCKET接口通过IP地址和端口定位远端,可在面向连接的传输控制协议(TCP)和面向无连接的用户数据包协议(UDP)之上顺利工作。考虑到系统客户端与服务器端命令信息需要无差错可靠传输以及TCP面向连接的可靠性特点,本系统使用TCP传输系统间命令信息。考虑到音频数据的实时性要求和可少量丢帧的限制及UDP协议本身的特点,本系统采用UDP协议传输语音信息[4]。
2.4混音模块
混音算法的最终目的是将输入的多路语音混合成一路语音输出,但由于实际应用环境不理想,在算法设计过程中需要着重考虑质量与效率兼顾的问题。由于语音会议中传输的是实时语音,如果网络延时过大或者需要处理时间过长就会影响到会议参与者的正常交流。网络时延问题非算法所能解决,这要求算法在特定的网络环境下保持较高的效率,使延时保证在用户可以忍受的范围内,同时语音质量也不能太差[5]。因此,混音算法需要同时兼顾语音质量和算法效率,需要在二者之间做好平衡。基于对常见混音算法的了解及实验验证,并考虑到会议系统中同时可分辨的发言人数有限,本系统的混音处理使用钳位法[6]。
钳位法是效率最高的混音算法之一,基本做法如同线性叠加法,仅在混音过程中对样本的溢处部分进行处理,将超过上限的样本值用上限值代替,超过下限的样本值用下限代替[7]。例如,用32bit的存储空间保存一个采样值,即C语言中的int类型(int最大值表示为INTMAX,最小值表示为INTMIN),处理叠加方法如下:
在溢出情况很少发生的情况下,此方法输出波形保真度高,语音质量良好。
3实验结果分析
经过对16位测听人员的主观测听结果分析可知,虚拟声功能在本系统中对方位感的模拟是有效的,100%的人体会到了方位感,且均认为此功能的添加对用户体验效果良好,但声像方位的准确度存在一定差距,这与头中定位有很大关系,若要提高准确度,需增加混响等算法辅助,此问题有待后续研究。
对虚拟声功能在2~4人同时讲话时辨识度的测听中,尤其对2~3人同时讲话时,100%的测听者选择了好于无虚拟声功能时的效果;4人同时讲话时,75%的测听者选择了好于无虚拟声功能时的效果,25%的测听者认为没有明显效果;在添加虚拟声功能后音质变化上,仅有1人认为音质变差了,其余15人认为并无明显变化,认为无明显变化的占总体的93.75%。总体评价中,100%的人认为添加虚拟声功能后用户体验更好,其中43.75%的测听者认为此功能的用户体验很好,大部分测听者认为此功能将混乱情况下的语音进行了方位感梳理,增强了鸡尾酒会效应,使测听人更加容易辨别说话人,也更容易辨识说话人所讲内容。
4结语
本系统旨在将虚拟声技术运用于语音会议系统中,以尽量增加与会者的现场感和真实感,并在一定程度上解决多人同时发言造成的声像混叠问题。因此,本系统不考虑会议系统的回声抵消问题和多扬声器播放时为保证正确声像而带来的串声消除问题。
虚拟声技术的运用,增加了系统的计算复杂度和系统设计难度,且由于本系统客户端需要获取每个参会人员的声音,这考验着网络的负载能力,因此就目前而言,本系统仅适用于召开少于10人的语音会议。但从未来趋势看,语音会议系统的复杂度越来越高,在基本功能实现的基础上增加与会者的现场感和真实感将是语音会议系统的发展方向。
参考文献:
[1]罗伟.大容量VoIP电话会议系统的研究与实现[D].西安:西安电子科技大学,2008.
[2]谢菠荪.头相关函数与虚拟听觉[M].北京:国防工业出版社,2007.
[3]谢菠荪,管善群.虚拟声技术及其应用(上)[J].应用声学,2004,23(4):43-47
[4]沈鑫剡.多媒體传输网络与VoIP系统设计[M].北京:人民邮电出版社,2005.
[5]殷晓虎,周娟,张静.基于会议系统混音算法的研究与应用[J].电声技术,2014,38(3):53-55.
[6]OHSHIMA K.A teleconferencing system with high-speed stream mixing for voice over IP[Z]. Wikipedia,2004.
[7]蒙肖雷.基于SIP的企业语音通话系统设计与实现[D].西安:西安电子科技大学,2014.
(责任编辑:孙娟)
