基于微博的热点话题跟踪技术研究
徐维林 张晖 殷玉娇 刘金岭

摘要:为了使人们能够更准确地了解所关注微博话题的后续发展情况,针对微博文本具有时序性的特点,定义了时间窗口,对每个时间窗口进行聚类,去除小类别话题,得到热点话题,然后分析热点话题的发展趋势,从而可以进行热点话题跟踪。通过对淮安近两个月来微博文本集实验结果表明,该方法是准确且有效。
关键词:微博;热点话题;跟踪技术
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)13-0186-03
Abstract: In order to enable people to understand more accurately the subsequent development of the microblog concern topic, according to the characteristics of the micro blog this with scheduling, defines the time window, each time window for clustering, remove small categories, get hot topic, and then analyzed the development trend of the hot topics, which can be hot topic tracking. Micro blog by mean of huaian nearly two months in this episode, the experimental results show that the method is accurate and effective.
Key words: Micro blog; hot topic; tracking technology
随着互联网信息技术的快速发展,微博已经成为人们日常生活中信息交流的重要平台。每天微博信息传播着数以万计的信息,信息的正确性及传播范围都无法得到有效控制,舆论热点、焦点层出不穷。由于话题对社会的稳定和众多网民产生了重大影响,因此对网络中话题的有效发现与监控变得非常重要。话题跟踪技术就是根据用户的需求,按照一定的算法,对相关的话题内容进行跟踪,并将跟踪到的结果进行归类整合。当前话题跟踪技术主要包括两种:一是利用检索的思想,根据话题构造查询向量;二是构建话题模型,利用话题模型跟踪后续报道。本文将取得的有时序序列的微博文本序列进行时间窗口分割,对每一个时间窗口的微博文本集进行分类,去掉小类别后得到热点话题的序列,通过对每相邻热点话题发展趋势的分析来进行热点话题的跟踪。
1 相关研究
话题检测与跟踪(Topic Detection and Tracking,TDT)是指从大量的新闻中发现新的话题,并且要为此话题建立一个模型,然后对后续的报道进行辨别和分析,找出已知的这个话题的相关报道或者发现新的话题并为其建立模型。TDT主要深入研究关于事件的发现和追踪技术[1],目前,研究者对TDT的研究很多,成果也不少,国外这方面研究重点也主要集中在如何衡量报道之间的相关性,以确定报道所属的话题,而在相关时,大部分采用的是向量空间模型(VSM)[2]、语言模型(LM)[3]]等方法如(James Allan[4]采用VSM来实现)。而Leek[5]和Yamron[6]则采用LM来解决这个问题。VSM和LM都存在特征空间的数据稀疏性的缺陷,也有研究者采用数据平滑技术来解决这个问题,但是平滑得到的特征权重无法有效描述文本内容上的差异。与国外相比,国内大部分处于起步阶段,不少研究者经常使用不同的方法取得了一定的成果。李树平等人利用KNN分类算法,对新闻报道文本的进行了话题跟踪实验[7];夏春艳等人先是在介绍了话题跟踪的一些基本方法的基础上,改进了KNN算法,提出了GTKNN 算法,减少了数据漂移的问题[8];谌志群等针对论坛数据,综合考虑帖子篇数与帖子热度,提出了基于相对熵的语义距离计算方法,通过构造主题演化图实现论坛热点话题的自动跟踪[9];解放军信息工程大学的邹鸿程利用主题概率思想的LDA模型将话题和微博表示为主题向量,提出 SA-MBLDA算法实现微博话题跟踪。[10] 该算法希望在构建话题模型时考虑语义,但LDA模型的语义单元仍然是词,考虑语义存在一定的局限性。
2 微博的分类及主题提取模型
文[11]中进行了短信文本语义分类及主题提取,稍加改造即可为对微博文本的分类及主题提取算法。假设微博文本集中的文本已经使用香农信息论对给定的每一个短信文本进行特征抽取,进一步进行了分词,词义消岐、去掉了停用词及连词、代词等,转化为向量形式
MB={(Wi1,Wi2,…,Win)|i=1,2,…,s} (1)
定义1 对于给定的时间定值t,按t将时间轴划分为连续的小区段,每段时间内含有若干条微博文本,称每个时间段内的微博文本集为时间窗口,记为t。
微博集合的分类及主题提取算法如下:
MC_S_TH算法:
Step1 根据信息论,在MB集合中,利用文[12]算法1计算出每个词的信息量H(Wij),进一步确定特征词Wij,构建微博特征向量
Step2 利用时间轴划分时间窗口t
Step2 利用文[13]算法2对t进行分类,去掉小类别话题得热点话题类别集合[14]
Step3利用文[15]中算法对每一个热点话题THij进行主题特征词提取
3 微博热点话题的演变
对于微博中主线的热话题,随着时间的推移,热点话题会发生变化甚至演变,所以在跟踪的过程中,要根据后续跟踪的微博信息对话题模型(分类模型)进行动态调整。如2015年12月20日广东深圳光明新区一工业园区附近发生山体滑坡事故,致使多栋楼房倒塌、被埋。事件发生之处,微博中谈论的热点一般是事情发生的经过、人员伤亡及财产损失等话题。随着事态发展,人们关注热点也会慢慢发生转移,如事故发生的原因、相关责任人及后续处理情况等话题。
3.1 热点话题模型更新、演变
热点话题模型更新是对初始训练集进行补充,也就是说微博信息谈论的话题仍然是原先的话题,只是关注点发生了变化。话题演变是指当一个初始话题被人们关注时,随着时态变化进入了新的话题,但这个新的话题与初始话题存在一定关联,但并不属于初始话题的范畴。
针对微博的时间序列,考虑所划分的时间窗口内的微博文本集。这样对于跨度小的热点话题,在短时间内会产生大量的相关微博,即在较短的时间内发现突发;相反,对于突发跨度大的热点话题,突发时间段内产生的微博数量相对较少。因为任何热点话题在夜间很少有人关注,因此本文在不正常时间的时间窗口(如晚上11:00-第2天6:00,偶尔几个时间窗口的微博数不符合可以不考虑不需要那么频繁检测,以提高系统的运行效率。
定义2 设按时序的某时间窗口t,则t中所含微博数量称为t的长度,记为|t|,t中所含热点话题HTi所含微博的数量成为话题的HTi强度,记为|HTi|。
3.2 微博热点话题生成与演变过程
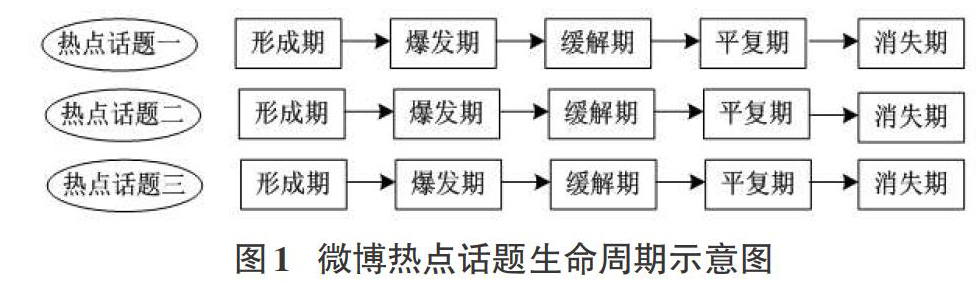
谢耘耕[11]提出了以时序序列为基准的微博热点话题的传播可以视作一个消息循环模型。分为形成期、爆发期、缓解期和平复期四个时段,其实任何热点事件都不会无限期传播下去,应该增加一个消失期,才符合热点话题的生命周期。微博热点话题生命周期示意图如图1所示。
热点话题的演变过程反映到反映到时间窗口上,就是话题强度的变化变化趋势,生命周期内热点话题强度变化趋势如图2所示。
热点话题跟踪就是判定热点话题的走势。
3.3 话题漂移
如前例中,2015年12月20日广东深圳发生山体滑坡事故,随着时间及热点话题的推移,人们的热点话题可能会转移到近几年来的国内有关安全生产上来。一般来讲,如果一个话题漂移为另一个话题,他们的相关度也是比较高的,可以通过两个话题特征词集合所包含的公共特征词数量和主题的相关度[16]反映出来,如从广东深圳发生山体滑坡事故的热点话题漂移到近几年来的国内有关安全生产的热点话题上来,公共特征词如安全、事故、责任等。
定义3 对给定的正整数M,主题相关性阈值,如果热点话题HTi和HTj的特征词集合分别为HTi_W和HTj_W,满足HTi_W∩HTj_W>M,0 4 基于微博的热点话题跟踪 为了研究话题的演变轨迹,我们将后续微博数据按照时间窗口切分,将每个时间窗口中的微博集合先是进行预处理构成向量集,利用SVM_S进行分类,提取每个类别主题,然后根据3.2和3.3的方法进行话题跟踪判定。 定义4 如果时间窗口中i中有热点话题HTij,其下一个相邻时间窗口i+1中有话题HTi+1,k,如果对于给定的主题相关性阈值,满足Sim(HTij,HTi+1,k)> ,则称热点话题HTi+1,k是热点话题的延续。 微博话题跟踪算法如下: MB_TT算法: Step1 抓取微博构成历史数据集 Step2 利用2中介绍的方法对微博历史数据集进行预处理得到微博向量集MB Step3 给定时间定值t,将MB划分为时间窗口 1,2,…,k Step4 对每一个时间窗口i,(i=1,2…,k)利用2中介绍的方法进行分类、主题提取 Step5 对相邻时间窗口k和k+1中热点话题进行比较 Step6 对于给定的主题相关性阈值 if Sim(HTij,HTi+1,k)> If(|HTij|与|HTi+1,k|相差不多)then 热点话题处于缓解期 Else If (|HTij|>>|HTi+1,k|) then 热点话题处于消失期 If (|HTij|<<|HTi+1,k|) then 热点话题处于爆发期 Else if 0 if HTij主题特征词集合∩HTi+1,k主题特征词集合=个数比较多 then 热点话题处于漂移 if HTij主题特征词集合∩HTi+1,k主题特征词集合=个数比较多 then 热点话题HTij结束 5 实验解结果分析 5.1 数据采集 利用Java编写网络爬虫从新浪微博上采集了淮安地区11、12月份以来的每天去掉6:00~11:00之间依微博数据,如图3所示。 对怕取得9954条微博去掉晚上11:00至明天6:00的微博,剩余9739条微博,每半个月划分为一个时间窗口,为四个时间窗口1、2、3、4,本文对微博语料进行分词,采用的是中科院计算所的 ICTCLAS 中文分词工具,利用MC_S_TH算法对i(i=1,…,4)进行分类热点话题和主题提取,本文只对与淮安相关的三个热点话题“淮安有轨电车”、“淮安楼盘”、“公务员考试”(分别记为HT电、HT楼、HT员)三个话题进行跟踪实验。实验结果如图4所示。 由图4可以看出,人们对“淮安有轨电车”话题关注度较大,分析器原因,从11月18日起,淮安现代有轨电车开展了连续20天的列车模拟试运营(跑图)工作,19日进行了首次载客试跑,于12月28日正式载客运营。楼盘在10月份、11月份较热,是因为淮阴区内9月底推新的三家楼盘分别为金鼎国际花园、联众光辉乾城及鼎泰公,清河区内东祺金域华府10月底推出多套楼盘,中天华庭自9月27日二期房源首开后,11月又推出多层洋房及小高层,新天地荣府决定于11月7日迎来首开盘,… 。到12月底就很少有微博信息了。公务员考试关注度较低,在12月低出现了上升期,查了相关政府网得知2016年江苏公务员考试报名时间为2016年1月11日9∶00至1月17日16∶00。从图4的折线图可以看出三个热点话题的2016年1月份发展趋势:“淮安有轨电车”话题处于缓解期,“淮安楼盘”话题处于消失期,“公务员考试”话题处于博发期。
6 结束语
话题跟踪作为信息处理领域中的一项重要问题,自提出以来就受到了广泛的关注,尤其用于舆情分析等领域后,更显现出它的应用价值[17]。目前,大多数的话题跟踪系统研究都是针对新闻信息、博客信息等长文本,关于微博等社交网络短文本信息的研究还比较少。本文针对微博文本具有时序性的特点,将时间轴划分为等距时间片,定义了时间窗口,对每个时间窗口进行聚类,去除小类别话题,得到热点话题,然后分析热点话题的发展趋势,从而可以可以进行热点话题跟踪。本文中采集了新浪网淮安地区的近11-12月份的微博文本进行实验取得了较理想的效果。
参考文献:
[1] 刘星星,何婷婷,龚海军.网络热点事件发现系统的设计[J].中文信息学报,2008,22(6):80-85.
[2] 姚清耘,刘功申,李翔.基于向量空间模型的文本聚类算法[J].计算机工程,2008,34(18):39-44.
[3] 骆卫华,刘群,白硕.面向大规模语料的语言模型研究新进展[J].计算机研究与发,2009,46(10):1704-1712.
[4] 任晓东,张永奎,薛晓飞.基于K-Modes聚类的自适应话题追踪技术[J].计算机工程,2009(9).
[5] 张晓艳,王挺,梁晓波.LDA模型在话题追踪中的应用[J].计算机科学,2011(10).
[6] 席耀一,林琛,李弼程,等.基于语义相似度的论坛话题追踪方法[J].计算机应用,2011(1).
[7] 李树平,夏春艳,李胜东,等.基于KNN的话题跟踪研究[J].微计算机信息,2012,10:264-265.
[8] 夏春艳,崔广才,李树平.话题跟踪方法的研究[J].计算机工程与应用,2012,15:129-132.
[9] 谌志群,徐宁,王荣波.基于主题演化图的网络论坛热点跟踪[J].情报科学,2013,03:147-150.
[10] 邹鸿程.微博话题检测与追踪技术研究[D].郑州:解放军信息工程大学,2012.
[11] 刘金岭.基于降维的短信文本语义分类及主题提取[J].计算机工程与应用,2010,46(23):159-161, 174.
[12] 刘金岭,倪晓红,王新功.手机短信文本信息流的自动文摘生成[J].现代图书情报技术,2013(2):43-49.
[13] 刘金岭.基于语义的高质量中文短信文本聚类算法[J].计算机工程,2009,35(10):201-205.
[14] 刘金岭,王新功.基于中文短信文本聚类的热点事件发现[J].情报杂志,2013,32(2):30-33.
[15] 刘金岭,严云洋.基于上下文的短信文本分类方法[J].计算机工程,2011,37(10):41-43.
[16] 刘金岭.基于主题的中文短信文本分类研究[J].计算机工程,2010,36(4):30-32.
[17] 谢耘耕,荣婷.微博舆论生成演变机制和舆论引导策略[J].现代传播,2011,178(5):70-74.
