交通一卡通清分管理中的全数据查重方法研究
谢振东+陈卫国+徐锋+何建兵+张景奎+罗鸣鸣
摘要:为更好地解决目前普遍存在的数据清分过程中的查重技术效率不高的问题,达到全数据查重流程优化的目的,从查询字段设计、存储过程同步、数据库优化等方面对全数据查重技术进行深入研究和分析,提出一套高效、准确的全数据查重方法及应用方案。实验结果表明,采用该查重方法能大幅提升大数据条件下的查重效率,有效缓解由于大量数据扫描导致系统IO占用过高,从而引发的系统性能下降。因此,该研究将为大数据背景下的一卡通数据清分管理系统提供安全、可靠和快速的数据查重,为企业、商户、客户提供准确的清算结果和报表奠定重要基础。
关键词:交通一卡通;大数据清分;全数据查重;数据库优化
DOIDOI:10.11907/rjdk.172242
中图分类号:TP301
文献标识码:A文章编号文章编号:16727800(2018)001003503
Abstract:In order to better solve the problem of low efficiency in the process of sorting data, and realize the purpose of the full data checking process optimization, This study will conduct indepth study and analysis on the whole data check technology from the aspects of query field design, stored procedure synchronization and database optimization, and presents a set of efficient and accurate data checking method and application.The experimental results show that this method can greatly improve the efficiency of inspection under the condition of large data, and effectively alleviate the system IO occupancy due to the large amount of data scanning, which leads to the performance degradation of the system.Therefore, this study will provide a safe, reliable and fast data check for the traffic card data sorting system in the context of large data, and lay an important foundation for the enterprise, businesses, customers to provide accurate accounting results and reports.
Key Words:IC card; big data clearing; data checking; database optimization
0引言
城市交通一卡通清分管理系統在交易数据清算过程中,若需要对数据库中的数据作全量查重,必须先进行全量数据的核查及历史同步两个关键步骤。通过对一卡通数据需求的调研分析可知,一卡通历史数据具有以下两大特点:①数据量庞大。以广东岭南通卡为例,目前约有320亿条历史数据存储在数据库中,成为企业数据分析的重要基础资源;②数据存储方式具有多样性。根据不同的业务应用需求,历史数据分别存储于数据库和文件中。
根据以上两个特点,在数据清分管理机制设计上需进行以下考虑:对历史数据进行实时清分时,要求与全量数据进行实时查重核对,防止重复记录。考虑到未来一卡通业务的增长性,清分系统设计必须达到一定的数据处理能力,如10W/min(每分钟10万条记录)。若按照原有清分方案,即把历史查重数据存放在同一数据库中,将导致查询性能大幅下降。
因此,在新的清分系统中,必须采用合理的存储方案,以提高查询性能,并且支持横向扩展。另外,在存储结构设计上采用单一化方式,对不同存储方式的历史数据进行全量同步,这就要求全量历史交易数据按统一格式构建查重字段,存放于数据库查重表中。
一般而言,一卡通交易数据查重是由以下4个字段组成:交易设备编号(PID)、票卡逻辑卡号(LCN)、脱机交易流水号(PSN)和交易认证码(TAC)。为提升查重效率,系统将不会直接以这4个字段为查询关键字,而是将这些字段拼接成一个完整字段再进行查询。
1全量查重流程设计
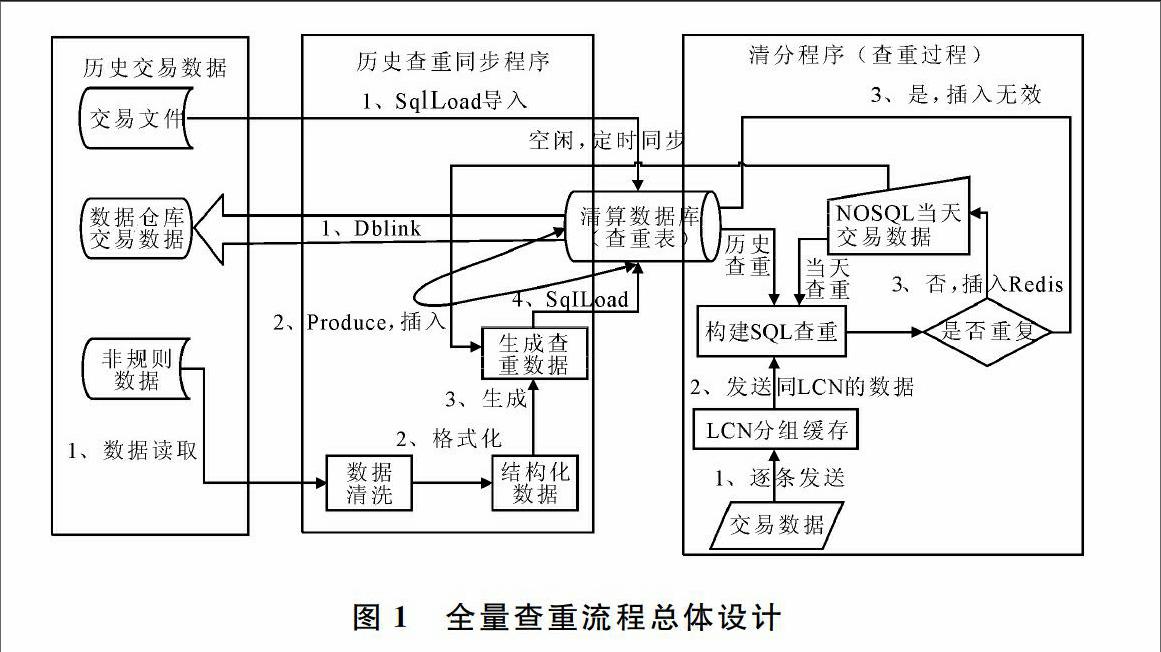
图1从总体设计和构建了存量历史数据、查重同步程序及清分程序等3个阶段的交互方式,展示了历史交易数据同步到全量查重表的方式,以及数据清分过程中对数据进行历史查重的设计流程。
1.1历史查重数据同步
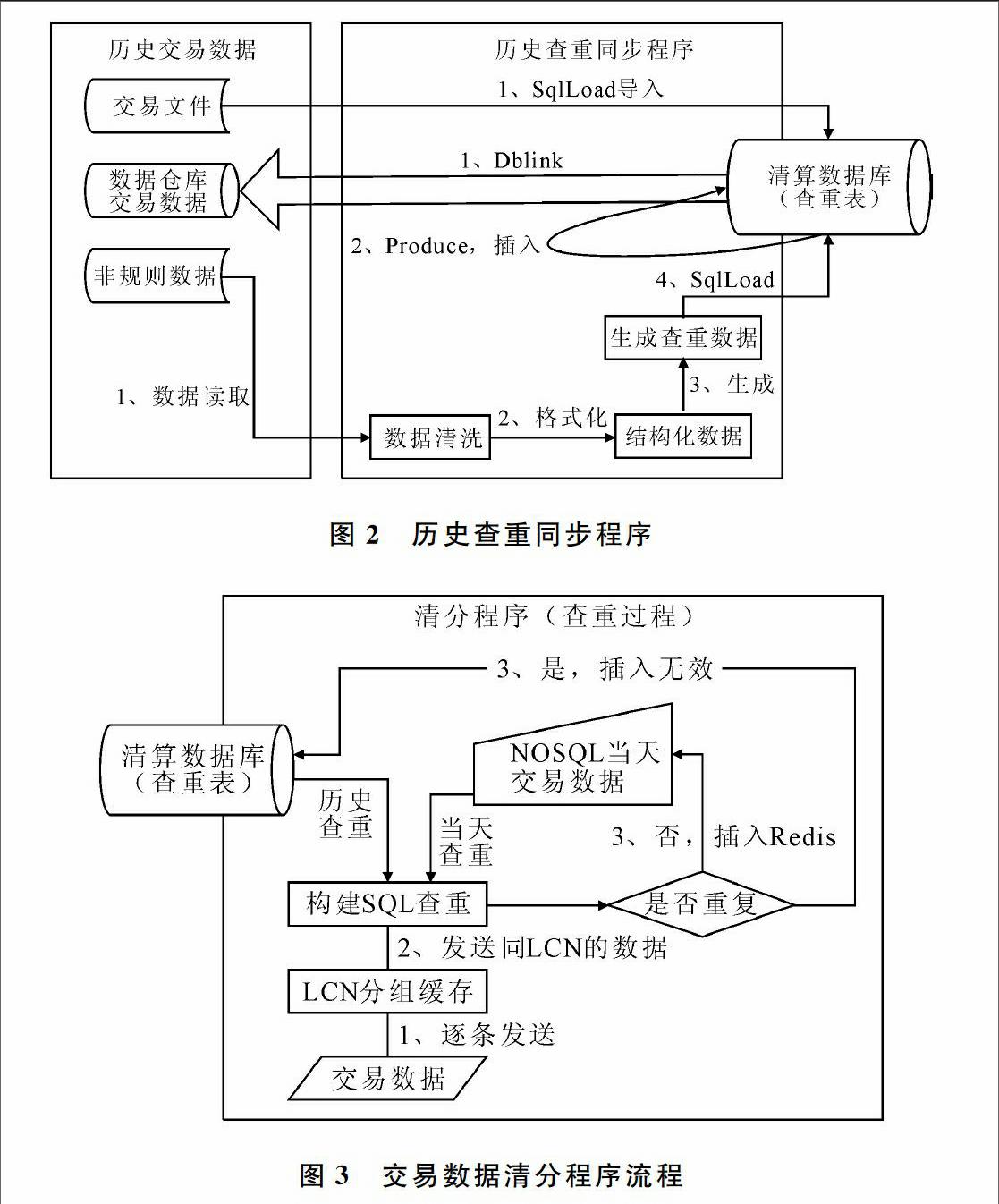
在全量查重之前,首先需要同步以往所有的交易数据,生成符合要求的待查重数据,并保存到查重数据表中,如图2所示。这里所指的历史数据主要来源于3方面,即以往保存的历史交易文件、数据仓库保存的历史交易记录以及其它非规则文件。根据数据来源结构不同,分别采取不同的同步方法:
(1)对于交易文件,其记录格式是固定的,前期可采取SqlLoad快速批量导入。
(2)对于数据仓库交易数据,需在清分数据库中建立Dblink后,创建存储过程完成查重数据同步。
(3)对于非规则数据,利用日志分析引擎读取并分析、查找交易数据,通过数据清洗及结构化后生成查重数据文件,最后利用SqlLoad同步到查重表。
1.2清分过程历史查重
在清分过程中,数据预处理是对每条数据逐一进行处理,通过文件、关键字段检查后才会对交易数据作历史查重。而历史查重的关键是对表数据的查询,因此系统必须对查重表进行优化。为解决海量异构数据存储的问题,可采用一种基于本体概念模型与NoSQL数据库的中间数据存储模型方案[12]。
通过对城市一卡通在公交、地铁的历史消费记录分析得出,同一张交通卡可能出现多笔交易记录。针对这种情况,可把同一张票卡数据组合成一条SQL语句,一次性完成数据查询,以降低数据库服务器的连接开销,如图3所示。
对于输入中的交易数据,在经过以上步骤后已完成了按LCN的排序,因此在LCN分组缓存环节中能快速聚合同一票卡的所有交易记录,将同一票卡的交易数据构建成一条SQL语句,并同时发送到清分数据库和NoSQL数据库中查询,得到查重结果[34]。
若查询结果显示数据没有重复,则数据须第一时间被缓存至NoSQL当天的交易数据表,以备下一条数据的查重。当完成数据包清分后,NoSQL当天的交易数据须转成查重數据文件,并定时导入到清分数据库查重表中。
2数据库优化设计
为进一步提升全量数据的查询效率,对数据库进行了一定优化。本文从以下3个维度进行探讨:范式优化、索引优化和查询优化。首先通过范式优化从中取优的方式设计一个逻辑,经过多重模式竞争,构建一种更为合理的逻辑结构。在数据库的物理设计上,利用索引优化对数据库的各个属性及相关组合属性进行全面优化,从而得到较为紧密的物理结构。最后一步是数据库查询工作,通过优化查询语句,提升数据查询执行效率[56]。
3实验案例分析
以广东岭南通卡为样本进行实例分析。以下分析所提到CPU卡是指卡片上的芯片含有一个微处理器,可配置COS系统,具有容量大、金融安全级别高的特点;M1卡是一种前期常用的非接触式IC卡,是菲利浦下属子公司恩智浦出品的芯片缩写,全称为NXP Mifare1系列,因价格便宜而获得了广泛应用,但又因安全性不足逐渐被CPU卡取代。CPU卡与M1卡的存储格式和处理机制有所不同。为将数据分析和查询难度降低,本文采用了物理分表和逻辑分表两种方式进行处理。
(1)物理分区。将CPU卡和M1卡的交易数据独立分开,将数据存储到不同的表中,初步减少无关数据的查询。若按320亿数据3∶2的比率预估,CPU为190亿,M1为128亿。
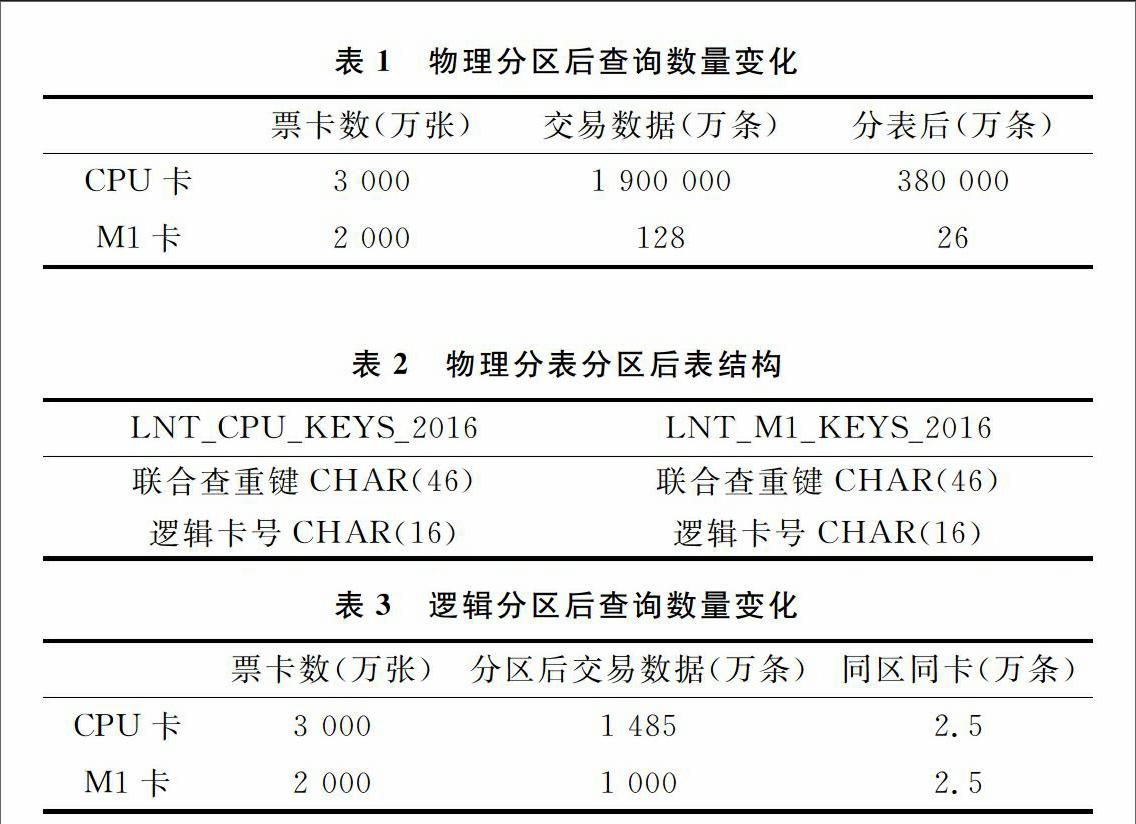
区分了CPU和M1后,各自数据仍十分巨大,再按票卡的发行时间(或首次交易时间)取得年份,按格式“T_LNT_CPU_KEYS_年份”形成表名,将该年的交易数据存储至此表下。按5年交易时间累计,获得CPU卡交易存放的数据表有T_LNT_CPU_KEYS_2012~T_LNT_CPU_KEYS_2016共5张表,每张表的数据约为38亿,而M1为25.6亿,如表1所示。
物理分表分区后表结构如表2所示。
(2)逻辑分区。物理分表以后,CPU卡和M1卡的交易查重数据量虽然明显减少,但对于几十亿数据的查询仍存在不少挑战。为进一步减少查询量级,现对各分表建立分区。考虑分区数据最好均匀,因此采用HASH分区,按票卡号(LCN)划分256个分区,数据如表3所示。
按近5年交易年限来算,3 000万CPU卡的交易数据在物理分表分区后,同一张CPU票卡全量查询的数据范围为2.5万=1 485万/(3 000万/5),同理M1为2.5万,查询数据范围得到缩小。
对同一张票卡,所使用的SQL查询语句如下:
SELECT COUNT(1) FROM T_LNT_CPU_KEYS_2016
WHERE LCN=? AND SEQ_KEY=?
通过大量数据测试及分析,对分区表中联合查重键(SEQ_KEY)、逻辑票卡(LCN)建立分区索引,查询速率更高。
如果查询表上只有主键而没有索引,那么很可能会引发全表扫描,特别是当数据量较大时,性能问题将成为瓶颈,导致磁盘IO过高,降低系统吞吐量[79]。
多达数百亿条的历史交易数据若在一个表中完成查重,必然导致查找速度十分缓慢[1011]。为提升效率,必须将数据合理切分。本研究得出的建议是:对于查重表可采用联合查看键、逻辑卡号这两字段,而对于交易数据,可通过SEQ_KEY查询。SEQ_KEY是由本次交易设备编号(PID)+票卡逻辑卡号(LCN)+脱机交易流水号(PSN)+交易认证码(TAC)拼接而成的。
4结语
为更好地适应公共交通领域一卡通快捷交易的需求,城市交通一卡通终端系统通常设置为脱机交易,非实时的脱机交易数据在清分时需要提供全数据查重功能。因此,这些历史海量数据和新增数据需要一套稳定、高效、快速的全数据查重算法技术,以及硬件设备在物理效率上提供支持,使城市一卡通业务的安全性得到保证。
参考文献:
[1]唐洪奎,张程,刘骥.基于NoSQL的物联网数据本体模型存储技术研究与实现[J].软件,2017(3):2733.
[2]张德山,李海浩.海量数据存储管理方法的研究[J].信息化研究,2011,37(4):47.
[3]常广炎,李逦.大数据查询与分析技术——SQL on Hadoop[J].软件导刊,2016,15(4):1315.
[4]沈啸.基于Oracle数据库海量数据的查询优化研究[J].无线互联科技,2016(10):106107.
[5]孟瑞军.数据库优化策略分析[J].探索科技,2016(12):5556.
[6]曾明霏,刘强.基于SQL和表设计的Oracle数据库开发审计研究[J].软件导刊,2016,15(12):136138.
[7]刘阳成,周俭,谢玉.海量数据存储管理技术研究[J].网络新媒体技术,2011,32(10):3336.
[8]王铭坤,袁少光,朱永利,等.基于Storm的海量数据实时聚类[J].计算机应用,2014,34(11):30783081.
[9]侯建,帅仁俊,侯文,等.基于云计算的海量数据存储模型[J].通信技术,2011,44(5):163165.
[10]周显春,肖衡.Spark 2.0平台在大数据处理中的应用研究[J].软件导刊,2017,16(5):149151.
[11]张昕,曾鹏,张瑞,等.交通大数据的特征及价值[J].软件导刊,2016,15(3):130132.
(责任编辑:黄健)
摘要:为更好地解决目前普遍存在的数据清分过程中的查重技术效率不高的问题,达到全数据查重流程优化的目的,从查询字段设计、存储过程同步、数据库优化等方面对全数据查重技术进行深入研究和分析,提出一套高效、准确的全数据查重方法及应用方案。实验结果表明,采用该查重方法能大幅提升大数据条件下的查重效率,有效缓解由于大量数据扫描导致系统IO占用过高,从而引发的系统性能下降。因此,该研究将为大数据背景下的一卡通数据清分管理系统提供安全、可靠和快速的数据查重,为企业、商户、客户提供准确的清算结果和报表奠定重要基础。
关键词:交通一卡通;大数据清分;全数据查重;数据库优化
DOIDOI:10.11907/rjdk.172242
中图分类号:TP301
文献标识码:A文章编号文章编号:16727800(2018)001003503
Abstract:In order to better solve the problem of low efficiency in the process of sorting data, and realize the purpose of the full data checking process optimization, This study will conduct indepth study and analysis on the whole data check technology from the aspects of query field design, stored procedure synchronization and database optimization, and presents a set of efficient and accurate data checking method and application.The experimental results show that this method can greatly improve the efficiency of inspection under the condition of large data, and effectively alleviate the system IO occupancy due to the large amount of data scanning, which leads to the performance degradation of the system.Therefore, this study will provide a safe, reliable and fast data check for the traffic card data sorting system in the context of large data, and lay an important foundation for the enterprise, businesses, customers to provide accurate accounting results and reports.
Key Words:IC card; big data clearing; data checking; database optimization
0引言
城市交通一卡通清分管理系統在交易数据清算过程中,若需要对数据库中的数据作全量查重,必须先进行全量数据的核查及历史同步两个关键步骤。通过对一卡通数据需求的调研分析可知,一卡通历史数据具有以下两大特点:①数据量庞大。以广东岭南通卡为例,目前约有320亿条历史数据存储在数据库中,成为企业数据分析的重要基础资源;②数据存储方式具有多样性。根据不同的业务应用需求,历史数据分别存储于数据库和文件中。
根据以上两个特点,在数据清分管理机制设计上需进行以下考虑:对历史数据进行实时清分时,要求与全量数据进行实时查重核对,防止重复记录。考虑到未来一卡通业务的增长性,清分系统设计必须达到一定的数据处理能力,如10W/min(每分钟10万条记录)。若按照原有清分方案,即把历史查重数据存放在同一数据库中,将导致查询性能大幅下降。
因此,在新的清分系统中,必须采用合理的存储方案,以提高查询性能,并且支持横向扩展。另外,在存储结构设计上采用单一化方式,对不同存储方式的历史数据进行全量同步,这就要求全量历史交易数据按统一格式构建查重字段,存放于数据库查重表中。
一般而言,一卡通交易数据查重是由以下4个字段组成:交易设备编号(PID)、票卡逻辑卡号(LCN)、脱机交易流水号(PSN)和交易认证码(TAC)。为提升查重效率,系统将不会直接以这4个字段为查询关键字,而是将这些字段拼接成一个完整字段再进行查询。
1全量查重流程设计
图1从总体设计和构建了存量历史数据、查重同步程序及清分程序等3个阶段的交互方式,展示了历史交易数据同步到全量查重表的方式,以及数据清分过程中对数据进行历史查重的设计流程。
1.1历史查重数据同步
在全量查重之前,首先需要同步以往所有的交易数据,生成符合要求的待查重数据,并保存到查重数据表中,如图2所示。这里所指的历史数据主要来源于3方面,即以往保存的历史交易文件、数据仓库保存的历史交易记录以及其它非规则文件。根据数据来源结构不同,分别采取不同的同步方法:
(1)对于交易文件,其记录格式是固定的,前期可采取SqlLoad快速批量导入。
(2)对于数据仓库交易数据,需在清分数据库中建立Dblink后,创建存储过程完成查重数据同步。
(3)对于非规则数据,利用日志分析引擎读取并分析、查找交易数据,通过数据清洗及结构化后生成查重数据文件,最后利用SqlLoad同步到查重表。
1.2清分过程历史查重
在清分过程中,数据预处理是对每条数据逐一进行处理,通过文件、关键字段检查后才会对交易数据作历史查重。而历史查重的关键是对表数据的查询,因此系统必须对查重表进行优化。为解决海量异构数据存储的问题,可采用一种基于本体概念模型与NoSQL数据库的中间数据存储模型方案[12]。
通过对城市一卡通在公交、地铁的历史消费记录分析得出,同一张交通卡可能出现多笔交易记录。针对这种情况,可把同一张票卡数据组合成一条SQL语句,一次性完成数据查询,以降低数据库服务器的连接开销,如图3所示。
对于输入中的交易数据,在经过以上步骤后已完成了按LCN的排序,因此在LCN分组缓存环节中能快速聚合同一票卡的所有交易记录,将同一票卡的交易数据构建成一条SQL语句,并同时发送到清分数据库和NoSQL数据库中查询,得到查重结果[34]。
若查询结果显示数据没有重复,则数据须第一时间被缓存至NoSQL当天的交易数据表,以备下一条数据的查重。当完成数据包清分后,NoSQL当天的交易数据须转成查重數据文件,并定时导入到清分数据库查重表中。
2数据库优化设计
为进一步提升全量数据的查询效率,对数据库进行了一定优化。本文从以下3个维度进行探讨:范式优化、索引优化和查询优化。首先通过范式优化从中取优的方式设计一个逻辑,经过多重模式竞争,构建一种更为合理的逻辑结构。在数据库的物理设计上,利用索引优化对数据库的各个属性及相关组合属性进行全面优化,从而得到较为紧密的物理结构。最后一步是数据库查询工作,通过优化查询语句,提升数据查询执行效率[56]。
3实验案例分析
以广东岭南通卡为样本进行实例分析。以下分析所提到CPU卡是指卡片上的芯片含有一个微处理器,可配置COS系统,具有容量大、金融安全级别高的特点;M1卡是一种前期常用的非接触式IC卡,是菲利浦下属子公司恩智浦出品的芯片缩写,全称为NXP Mifare1系列,因价格便宜而获得了广泛应用,但又因安全性不足逐渐被CPU卡取代。CPU卡与M1卡的存储格式和处理机制有所不同。为将数据分析和查询难度降低,本文采用了物理分表和逻辑分表两种方式进行处理。
(1)物理分区。将CPU卡和M1卡的交易数据独立分开,将数据存储到不同的表中,初步减少无关数据的查询。若按320亿数据3∶2的比率预估,CPU为190亿,M1为128亿。
区分了CPU和M1后,各自数据仍十分巨大,再按票卡的发行时间(或首次交易时间)取得年份,按格式“T_LNT_CPU_KEYS_年份”形成表名,将该年的交易数据存储至此表下。按5年交易时间累计,获得CPU卡交易存放的数据表有T_LNT_CPU_KEYS_2012~T_LNT_CPU_KEYS_2016共5张表,每张表的数据约为38亿,而M1为25.6亿,如表1所示。
物理分表分区后表结构如表2所示。
(2)逻辑分区。物理分表以后,CPU卡和M1卡的交易查重数据量虽然明显减少,但对于几十亿数据的查询仍存在不少挑战。为进一步减少查询量级,现对各分表建立分区。考虑分区数据最好均匀,因此采用HASH分区,按票卡号(LCN)划分256个分区,数据如表3所示。
按近5年交易年限来算,3 000万CPU卡的交易数据在物理分表分区后,同一张CPU票卡全量查询的数据范围为2.5万=1 485万/(3 000万/5),同理M1为2.5万,查询数据范围得到缩小。
对同一张票卡,所使用的SQL查询语句如下:
SELECT COUNT(1) FROM T_LNT_CPU_KEYS_2016
WHERE LCN=? AND SEQ_KEY=?
通过大量数据测试及分析,对分区表中联合查重键(SEQ_KEY)、逻辑票卡(LCN)建立分区索引,查询速率更高。
如果查询表上只有主键而没有索引,那么很可能会引发全表扫描,特别是当数据量较大时,性能问题将成为瓶颈,导致磁盘IO过高,降低系统吞吐量[79]。
多达数百亿条的历史交易数据若在一个表中完成查重,必然导致查找速度十分缓慢[1011]。为提升效率,必须将数据合理切分。本研究得出的建议是:对于查重表可采用联合查看键、逻辑卡号这两字段,而对于交易数据,可通过SEQ_KEY查询。SEQ_KEY是由本次交易设备编号(PID)+票卡逻辑卡号(LCN)+脱机交易流水号(PSN)+交易认证码(TAC)拼接而成的。
4结语
为更好地适应公共交通领域一卡通快捷交易的需求,城市交通一卡通终端系统通常设置为脱机交易,非实时的脱机交易数据在清分时需要提供全数据查重功能。因此,这些历史海量数据和新增数据需要一套稳定、高效、快速的全数据查重算法技术,以及硬件设备在物理效率上提供支持,使城市一卡通业务的安全性得到保证。
参考文献:
[1]唐洪奎,张程,刘骥.基于NoSQL的物联网数据本体模型存储技术研究与实现[J].软件,2017(3):2733.
[2]张德山,李海浩.海量数据存储管理方法的研究[J].信息化研究,2011,37(4):47.
[3]常广炎,李逦.大数据查询与分析技术——SQL on Hadoop[J].软件导刊,2016,15(4):1315.
[4]沈啸.基于Oracle数据库海量数据的查询优化研究[J].无线互联科技,2016(10):106107.
[5]孟瑞军.数据库优化策略分析[J].探索科技,2016(12):5556.
[6]曾明霏,刘强.基于SQL和表设计的Oracle数据库开发审计研究[J].软件导刊,2016,15(12):136138.
[7]刘阳成,周俭,谢玉.海量数据存储管理技术研究[J].网络新媒体技术,2011,32(10):3336.
[8]王铭坤,袁少光,朱永利,等.基于Storm的海量数据实时聚类[J].计算机应用,2014,34(11):30783081.
[9]侯建,帅仁俊,侯文,等.基于云计算的海量数据存储模型[J].通信技术,2011,44(5):163165.
[10]周显春,肖衡.Spark 2.0平台在大数据处理中的应用研究[J].软件导刊,2017,16(5):149151.
[11]张昕,曾鹏,张瑞,等.交通大数据的特征及价值[J].软件导刊,2016,15(3):130132.
(责任编辑:黄健)
