基于改进的C4.5算法对车辆加速性能分类研究
陆宝红+陈晨+曹曦文+陈眺+曾洁+史昇+宋雪桦


摘要:
车辆加速性能是衡量驾驶员对车辆驾驶舒适性的一个标准。传统的车辆加速性能是通过判断加速踏板开度衡量的,加速踏板出厂时设置为不能自动调整。采用改进的C4.5算法对车辆加速性能分类,实现自动调整加速踏板开度。首先通过泰勒中值定理对C4.5算法进行简化,然后对车联网数据进行特征提取,生成判断加速性能的决策树分类规则,测试特征提取的并行化运行效率。通过特征提取后的数据集验证了改进的C4.5算法效率和准确率。测试结果表明,改进算法在不降低分类准确率的前提下,有效提高了分类效率。
关键词:
车联网;HBase;MapReduce;C4.5
DOIDOI:10.11907/rjdk.172155
中图分类号:TP391
文献标识码:A文章编号文章编号:1672-7800(2018)001-0184-04
Abstract:Vehicle acceleration performance is a measure of the drivers comfort in driving a vehicle and improving driving comfort is a matter of concern. The traditional vehicle acceleration performance is determined by judging the accelerator pedal opening degree, and the accelerator pedal can not be adjusted automatically when the factory is set up. Therefore, the paper adopts the improved C4.5 algorithm to automatically adjust the accelerator pedal opening degree to the vehicle acceleration performance classification. Firstly, the algorithm of C4.5 is simplified by Taylors mean value theorem, and then the feature extraction of car network data is carried out to generate decision tree classification rules to judge the acceleration performance, parallel operation efficiency of test feature extraction, and finally the data extracted by feature Set to verify the efficiency and accuracy of the improved C4.5 algorithm. The test results show that the improved algorithm effectively improves the efficiency of classification and the classification accuracy is not reduced.
Key Words:car networking; HBase; MapReduce; C4.5
0引言
分类问题在数据挖掘领域研究和应用较为广泛[1]。决策树算法分类速度快、精度高、生成的分类规则易于理解。其中,决策树C4.5算法最为经典,具有以下优点:分类规则易于理解,准确率较高;基本解决了ID3存在的多值偏向性问题;可以处理连续数值型属性;可以处理缺失值;能够在决策树构造过程中进行剪枝[2],但C4.5存在构造决策树效率较低的缺陷。
车辆的加速性能以及踏板的开度使用情况反映了驾驶的舒适性,提高加速性能的关键是如何通过整车参数判断加速性能不足,以及油门踏板加速过深或加速过浅。通过设置阈值来判断加速性能的传统方法无法证明其合理性,阈值由于环境及人为因素影响不好准确界定。本文采用改进后的C4.5分类算法对车辆加速性能分类,提高了分类效率。根据C4.5算法分类结果对map进行改进,可有效提高判断的准确性,从而提高驾驶舒适性。
1加速性能分类实现原理
(1)MapReduce是基于批处理的分布式计算框架[3],可并行处理大量原始数据,如合并网络日志,用于模拟用户和网站互动。这项工作如果用串行编程技术处理需要花费很长时间,但是使用MapReduce仅仅需要几分钟就可处理完。
(2)HBase是一个分布式数据库,具有高可靠、高性能、面向列、可伸缩的特点,可在廉價PC上搭建大数据存储集群。HBase源自于谷歌的BigTable, HDFS作为HBase的文件存储系统, MapReduce可以基于HBase进行批量数据处理, HBase采用ZooKeeper作为协调组件[4]。HBase基于横向扩展的设计模式,通过增加廉价的服务器增加集群的存储能力。
2改进的C4.5算法
(1)基于中值定理对C4.5算法进行改进。在C4.5算法中计算熵和信息增益时,都涉及对数的运算,每次都要调用系统函数,运算量较大。通过泰勒中值定理简化计算熵和信息增益,进而改进C4.5算法,从效率方面提升C4.5算法性能[5]。
改进的C4.5算法简要说明:假设训练数据集S分为两类,两类的个数分别为M和N,假设属性A的取值分别为a1,a2,a3,…,al;
把A=ai所得的实例数据集写做Pj,则子集中两个类中的实例个数分别为Mi和Ni。利用泰勒中值定理经过一系列推导,可以计算出按属性A划分S后的样本子集信息熵为:
由此求出信息增益率为:
式(2)消除了所有的对数运算,由加减乘除四则运算组成,算法效率会明显提升。C4.5算法通过比较不同属性之间信息增益率的大小决定决策树的分裂点,而不需要得到信息增益率具体大小,只要找到信息增益率最大值的对应属性。所以,可消除式(2)中相同的部分,也就是固定的那一部分,从而进一步简化信息增益率公式,提高算法运行效率。式(2)可简化为:
(2)C4.5算法并行化实现。MapReduce并行编程模型包括Map和Reduce两个部分。基于MapReduce可以实现大规模数据处理,能在普通的机器集群上处理大规模数据集。通过分析C4.5算法可知,决策树生成的关键是属性选择度量计算,它占用了整个计算过程中的绝大部分计算资源。基于MapReduce对属性选择度量的计算是C4.5算法并行化设计的主要工作。
C4.5算法中,每个属性的信息增益率计算相互独立,完全可以利用并行的MapReduce统计和计算与信息增益率相关的每个属性信息,最后利用这些信息快速计算信息增益率,构造出决策树。
C4.5算法的Map阶段:在生成决策树时,Map阶段的主要任务是对大规模训练样本按照决策树中的某一层节点的划分条件进行切分,划分条件就是该树节点在决策树中已经生成的路径[6]。本算法中,决策树路径的构造方法是基于层次切分数据的广度优先策略。假设对输入的待划分训练集D,划分在决策树同一层的n个节点为:D1,D2,…,Dn,则必定满足D-D0=D1∪D2∪…∪Dn。其中,D0为已生成为叶节点的部分子训练集,且满足:D1∩D2∩…∩Dn=。即Map函数主要负责以单个元组的形式分解数据,并以的形式输出D1,D2,…,Dn,以方便在Reduce阶段对其进行统计计算。key由用于标记不同树节点的临时ID、训练集的某个属性S、该元组对应属性S的值s以及该元组的所属决策类c组成,而value值为1即可。
C4.5算法的Reduce阶段设计:Reduce阶段的任务相对清晰,即完成对Map输出的进行整理,将带有相同key值的value值累加到value-sum。同时,将统计好的输出到分布式文件系统HDFS中,以供主程序计算各个属性的信息增益率时使用。主控程序在读取这些信息后,会生成一个哈希表,从哈希表中,可以容易查到对于某个节点i,在落在其中的子训练样本集中,在属性S上的取值是s且类标号为c的样本有多少个[7]。利用这些信息,可以很容易地计算出某个节点i在某个属性S上的信息增益率,从而找出最佳分裂属性。
C4.5决策树算法的主程序功能分为两部分:①串行构造决策树C4.5算法执行;②在决策树构造算法需要计算信息增益率时,调用MapReduce程序在大规模训练样本上进行统计,获得各个属性的统计信息,然后利用这些信息计算出属性的信息增益率[8]。
3改进的C4.5算法对车辆加速性能分类
大部分传感器采集的原始数据都会出现数据冗余或缺失等问题,为了保证数据分析结果的有效性和可靠性,必须对原始数据进行数据清洗,也就是数据预处理。本文的原始数据包括标号、车辆加速踏板开度和转速。其中标号相当于每辆车的ID,作为每辆车唯一的标识,时间精确到秒级。
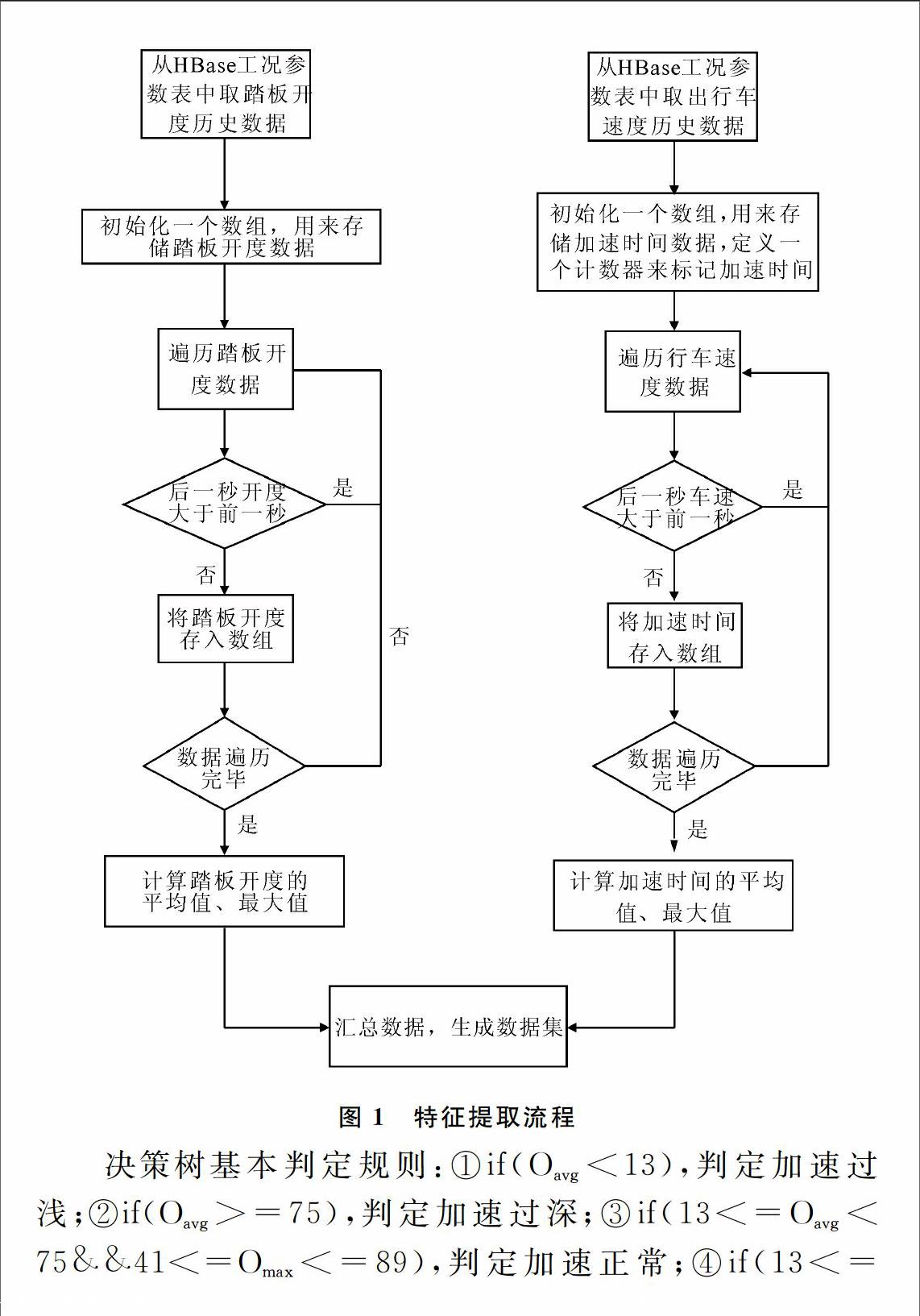
仅仅根据原始数据无法正确判断油门踏板加速情况,因此需要提取每辆车原始数据的数字特征作为新的属性。原始数据包括加速踏板开度、行车速度。加速踏板开度和加速时间特征值和加速性能息息相关,行车速度用来判断加速过程,数字特征提取的关键是提取加速时间的数字特征。数据预处理流程如图1所示。
图1为特征提取流程,主要提取加速踏板开度和加速时间的典型数字特征,通过车辆行驶速度识别车辆加速过程,并且计算加速时间的平均值以及最大值。原始数据从HBase分布式数据库中提取。为了保证数据的可靠性,采集的数据规模要尽可能大,采集1~3天的历史数据生成一个训练集。
训练集均为连续性属性,类标号分为正常加速、加速过深、加速过浅3种加速工况。开度均值指所有时间范围内开度的平均值,用Oavg表示;开度最大值指每次加速过程中的开度最大值的平均值,用Omax表示。时间均值指加速时间的平均值,用Tavg表示,时间最大值指加速时间的最大值,用Tmax表示。其中,开度均值取四舍五入后的近似整数,时间均值近似到小数点后面一位。
利用C4.5算法和训练集、测试集,可以完成车辆加速性能分类,从而判断车辆驱动map是否需要改进。首先,利用训练数据集和改进的C4.5算法完成分类决策树构建,如图2所示。
4实验及分析
实验数据来源于恒驰公司一年的车联网传感数据,共计1GB,上百万条,这些数据包含不同环境、不同路况以及不同驾驶情况下采集的数据。这些数据是原始数据,不能直接用决策树算法进行分类,首先需要进行数字特征提取,预处理整理出5 000多条数据集记录。利用改进的C4.5算法对预处理后的数据集进行分类,實验从算法运行效率和分类准确率两方面进行验证分析。将采集的数据经过数据预处理,提取出表1中的属性作为数据集属
性。将数据分为训练集和测试集,训练集用来构造决策树,测试集用来通过计算分类准确率评价决策树。数据集按照5/5划分,训练集和测试集各占50%。
4.1数据分类准确率
选择数据预处理后的5 500条数据记录作为测试样本,分析分类准确率,分别对比传统C4.5算法和改进的C4.5算法的准确率。本文将基于泰勒中值定理简化的C4.5算法称为MC4.5算法,基于MapReduce并行化的算法称为HC4.5算法,基于MapReduce并行化的MC4.5算法称为HMC4.5算法。将5 500条数据组成的样本分为5等分,分别计算4个小数据集的分类准确率,并计算各个算法的平均准确率。4种算法处理车联网数据的准确率如表2所示。
从表2可知,对于不同的数据子集,4种算法的准确率在70%左右,MC4.5、HC4.5、HMC4.5与传统C4.5算法在分类准确率方面基本没有差别。
4.2数据分类效率对比实验
取原始数据整理后的5 000条记录,由于数据量不是太大,无法验证C4.5算法并行化的优势,所以本文将5 000条记录复制,增加数据量。C4.5算法和MC4.5算法单机运行,HC4.5算法和HMC4.5算法将在5节点的Hadoop集群上运行。比较C4.5算法和MC4.5算法以及C4.5算法和HMC4.5算法在处理不同数据量时的效率。表3记录了几个算法在处理不同数据量时的运行时间。为保证实验数据的可靠性,排除外部环境干扰,实验的结果取多次实验的平均值。
表3给出了4种算法运行效率的对比结果。从表中可以看出,基于泰勒中值定理改进的C4.5算法(MC4.5)在运行效率上有一定的提升,在处理相同数据集的情况下,算法执行时间略低于传统的C4.5算法,平均提升约5%左右。从基于泰勒中值定理改进的C4.5算法(MC4.5)和其并行化实现的算法(HMC4.5)对比情况看,并行化实现的处理效率远远高于串行实现,几乎随着集群中计算节点数量成倍增长。但是效果不是很理想,因为并行算法在处理过程中会因为I/O而消耗一部分计算资源。综上所述,在对车辆加速性能分类的应用中,本文改进的C4.5算法(HMC4.5)在效率方面远远高于传统的C4.5算法。
5结语
本文基于改进的C4.5算法对车辆加速性能进行分类。基于泰勒中值定理对传统C4.5算法进行了改进,简化了属性选择度量的计算,从而提高了C4.5算法的运行效率。对改进的C4.5算法并行化设计,对Map阶段、Reduce阶段以及主函数3个部分进行了详细设计,进一步提高了算法的执行效率。对原始数据基于MapReduce进行特征提取,生成数据集。将改进后的C4.5算法应用在加速性能判断上,生成決策树模型,并对决策树规则进行阐述。与原C4.5算法相比,在分类准确率没有降低的情况下,改进后的C4.5算法提高了分类效率。
参考文献:
[1]吴旖雯.分类规则挖掘在金融中的应用[D].杭州:浙江大学,2016.
[2]JIAWEI HAN. Data mining:concepte and techniques[M]. America:Elsevier Inc,2012.
[3]TOM, WHITE. Hadoop:the definitive guide[M]. America:O'Reilly Media,Inc,2010.
[4]LARS, GEORGE. HBase:the definitive guide[M]. America:Posts&Telecom Press,2011.
[5]WATHIQ, LAFTAH, AI YASEEN. Hybrid modified K-Means with C4.5 for intrusion dectection systems in multiagent systems[J]. The Scientific World Journal,2015(4):33-34.
[6]PIERO, GIACOMELLI. Mahout cookbook[M]. America:Packt Publishing, 2014.
[7]毛国君,胡殿军,谢松燕.基于分布式数据流的大数据分类模型和算法[J].计算机学报,2017(1):9-12.
[8]CHONGQING WU. MReC4.5:C4.5 ensemble classify-cation with MapReduce[C]. Fourth ChinaGrid Annual Conference,2013:250-251.
(责任编辑:杜能钢)
摘要:
车辆加速性能是衡量驾驶员对车辆驾驶舒适性的一个标准。传统的车辆加速性能是通过判断加速踏板开度衡量的,加速踏板出厂时设置为不能自动调整。采用改进的C4.5算法对车辆加速性能分类,实现自动调整加速踏板开度。首先通过泰勒中值定理对C4.5算法进行简化,然后对车联网数据进行特征提取,生成判断加速性能的决策树分类规则,测试特征提取的并行化运行效率。通过特征提取后的数据集验证了改进的C4.5算法效率和准确率。测试结果表明,改进算法在不降低分类准确率的前提下,有效提高了分类效率。
关键词:
车联网;HBase;MapReduce;C4.5
DOIDOI:10.11907/rjdk.172155
中图分类号:TP391
文献标识码:A文章编号文章编号:1672-7800(2018)001-0184-04
Abstract:Vehicle acceleration performance is a measure of the drivers comfort in driving a vehicle and improving driving comfort is a matter of concern. The traditional vehicle acceleration performance is determined by judging the accelerator pedal opening degree, and the accelerator pedal can not be adjusted automatically when the factory is set up. Therefore, the paper adopts the improved C4.5 algorithm to automatically adjust the accelerator pedal opening degree to the vehicle acceleration performance classification. Firstly, the algorithm of C4.5 is simplified by Taylors mean value theorem, and then the feature extraction of car network data is carried out to generate decision tree classification rules to judge the acceleration performance, parallel operation efficiency of test feature extraction, and finally the data extracted by feature Set to verify the efficiency and accuracy of the improved C4.5 algorithm. The test results show that the improved algorithm effectively improves the efficiency of classification and the classification accuracy is not reduced.
Key Words:car networking; HBase; MapReduce; C4.5
0引言
分类问题在数据挖掘领域研究和应用较为广泛[1]。决策树算法分类速度快、精度高、生成的分类规则易于理解。其中,决策树C4.5算法最为经典,具有以下优点:分类规则易于理解,准确率较高;基本解决了ID3存在的多值偏向性问题;可以处理连续数值型属性;可以处理缺失值;能够在决策树构造过程中进行剪枝[2],但C4.5存在构造决策树效率较低的缺陷。
车辆的加速性能以及踏板的开度使用情况反映了驾驶的舒适性,提高加速性能的关键是如何通过整车参数判断加速性能不足,以及油门踏板加速过深或加速过浅。通过设置阈值来判断加速性能的传统方法无法证明其合理性,阈值由于环境及人为因素影响不好准确界定。本文采用改进后的C4.5分类算法对车辆加速性能分类,提高了分类效率。根据C4.5算法分类结果对map进行改进,可有效提高判断的准确性,从而提高驾驶舒适性。
1加速性能分类实现原理
(1)MapReduce是基于批处理的分布式计算框架[3],可并行处理大量原始数据,如合并网络日志,用于模拟用户和网站互动。这项工作如果用串行编程技术处理需要花费很长时间,但是使用MapReduce仅仅需要几分钟就可处理完。
(2)HBase是一个分布式数据库,具有高可靠、高性能、面向列、可伸缩的特点,可在廉價PC上搭建大数据存储集群。HBase源自于谷歌的BigTable, HDFS作为HBase的文件存储系统, MapReduce可以基于HBase进行批量数据处理, HBase采用ZooKeeper作为协调组件[4]。HBase基于横向扩展的设计模式,通过增加廉价的服务器增加集群的存储能力。
2改进的C4.5算法
(1)基于中值定理对C4.5算法进行改进。在C4.5算法中计算熵和信息增益时,都涉及对数的运算,每次都要调用系统函数,运算量较大。通过泰勒中值定理简化计算熵和信息增益,进而改进C4.5算法,从效率方面提升C4.5算法性能[5]。
改进的C4.5算法简要说明:假设训练数据集S分为两类,两类的个数分别为M和N,假设属性A的取值分别为a1,a2,a3,…,al;
把A=ai所得的实例数据集写做Pj,则子集中两个类中的实例个数分别为Mi和Ni。利用泰勒中值定理经过一系列推导,可以计算出按属性A划分S后的样本子集信息熵为:
由此求出信息增益率为:
式(2)消除了所有的对数运算,由加减乘除四则运算组成,算法效率会明显提升。C4.5算法通过比较不同属性之间信息增益率的大小决定决策树的分裂点,而不需要得到信息增益率具体大小,只要找到信息增益率最大值的对应属性。所以,可消除式(2)中相同的部分,也就是固定的那一部分,从而进一步简化信息增益率公式,提高算法运行效率。式(2)可简化为:
(2)C4.5算法并行化实现。MapReduce并行编程模型包括Map和Reduce两个部分。基于MapReduce可以实现大规模数据处理,能在普通的机器集群上处理大规模数据集。通过分析C4.5算法可知,决策树生成的关键是属性选择度量计算,它占用了整个计算过程中的绝大部分计算资源。基于MapReduce对属性选择度量的计算是C4.5算法并行化设计的主要工作。
C4.5算法中,每个属性的信息增益率计算相互独立,完全可以利用并行的MapReduce统计和计算与信息增益率相关的每个属性信息,最后利用这些信息快速计算信息增益率,构造出决策树。
C4.5算法的Map阶段:在生成决策树时,Map阶段的主要任务是对大规模训练样本按照决策树中的某一层节点的划分条件进行切分,划分条件就是该树节点在决策树中已经生成的路径[6]。本算法中,决策树路径的构造方法是基于层次切分数据的广度优先策略。假设对输入的待划分训练集D,划分在决策树同一层的n个节点为:D1,D2,…,Dn,则必定满足D-D0=D1∪D2∪…∪Dn。其中,D0为已生成为叶节点的部分子训练集,且满足:D1∩D2∩…∩Dn=。即Map函数主要负责以单个元组的形式分解数据,并以
C4.5算法的Reduce阶段设计:Reduce阶段的任务相对清晰,即完成对Map输出的
C4.5决策树算法的主程序功能分为两部分:①串行构造决策树C4.5算法执行;②在决策树构造算法需要计算信息增益率时,调用MapReduce程序在大规模训练样本上进行统计,获得各个属性的统计信息,然后利用这些信息计算出属性的信息增益率[8]。
3改进的C4.5算法对车辆加速性能分类
大部分传感器采集的原始数据都会出现数据冗余或缺失等问题,为了保证数据分析结果的有效性和可靠性,必须对原始数据进行数据清洗,也就是数据预处理。本文的原始数据包括标号、车辆加速踏板开度和转速。其中标号相当于每辆车的ID,作为每辆车唯一的标识,时间精确到秒级。
仅仅根据原始数据无法正确判断油门踏板加速情况,因此需要提取每辆车原始数据的数字特征作为新的属性。原始数据包括加速踏板开度、行车速度。加速踏板开度和加速时间特征值和加速性能息息相关,行车速度用来判断加速过程,数字特征提取的关键是提取加速时间的数字特征。数据预处理流程如图1所示。
图1为特征提取流程,主要提取加速踏板开度和加速时间的典型数字特征,通过车辆行驶速度识别车辆加速过程,并且计算加速时间的平均值以及最大值。原始数据从HBase分布式数据库中提取。为了保证数据的可靠性,采集的数据规模要尽可能大,采集1~3天的历史数据生成一个训练集。
训练集均为连续性属性,类标号分为正常加速、加速过深、加速过浅3种加速工况。开度均值指所有时间范围内开度的平均值,用Oavg表示;开度最大值指每次加速过程中的开度最大值的平均值,用Omax表示。时间均值指加速时间的平均值,用Tavg表示,时间最大值指加速时间的最大值,用Tmax表示。其中,开度均值取四舍五入后的近似整数,时间均值近似到小数点后面一位。
利用C4.5算法和训练集、测试集,可以完成车辆加速性能分类,从而判断车辆驱动map是否需要改进。首先,利用训练数据集和改进的C4.5算法完成分类决策树构建,如图2所示。
4实验及分析
实验数据来源于恒驰公司一年的车联网传感数据,共计1GB,上百万条,这些数据包含不同环境、不同路况以及不同驾驶情况下采集的数据。这些数据是原始数据,不能直接用决策树算法进行分类,首先需要进行数字特征提取,预处理整理出5 000多条数据集记录。利用改进的C4.5算法对预处理后的数据集进行分类,實验从算法运行效率和分类准确率两方面进行验证分析。将采集的数据经过数据预处理,提取出表1中的属性作为数据集属
性。将数据分为训练集和测试集,训练集用来构造决策树,测试集用来通过计算分类准确率评价决策树。数据集按照5/5划分,训练集和测试集各占50%。
4.1数据分类准确率
选择数据预处理后的5 500条数据记录作为测试样本,分析分类准确率,分别对比传统C4.5算法和改进的C4.5算法的准确率。本文将基于泰勒中值定理简化的C4.5算法称为MC4.5算法,基于MapReduce并行化的算法称为HC4.5算法,基于MapReduce并行化的MC4.5算法称为HMC4.5算法。将5 500条数据组成的样本分为5等分,分别计算4个小数据集的分类准确率,并计算各个算法的平均准确率。4种算法处理车联网数据的准确率如表2所示。
从表2可知,对于不同的数据子集,4种算法的准确率在70%左右,MC4.5、HC4.5、HMC4.5与传统C4.5算法在分类准确率方面基本没有差别。
4.2数据分类效率对比实验
取原始数据整理后的5 000条记录,由于数据量不是太大,无法验证C4.5算法并行化的优势,所以本文将5 000条记录复制,增加数据量。C4.5算法和MC4.5算法单机运行,HC4.5算法和HMC4.5算法将在5节点的Hadoop集群上运行。比较C4.5算法和MC4.5算法以及C4.5算法和HMC4.5算法在处理不同数据量时的效率。表3记录了几个算法在处理不同数据量时的运行时间。为保证实验数据的可靠性,排除外部环境干扰,实验的结果取多次实验的平均值。
表3给出了4种算法运行效率的对比结果。从表中可以看出,基于泰勒中值定理改进的C4.5算法(MC4.5)在运行效率上有一定的提升,在处理相同数据集的情况下,算法执行时间略低于传统的C4.5算法,平均提升约5%左右。从基于泰勒中值定理改进的C4.5算法(MC4.5)和其并行化实现的算法(HMC4.5)对比情况看,并行化实现的处理效率远远高于串行实现,几乎随着集群中计算节点数量成倍增长。但是效果不是很理想,因为并行算法在处理过程中会因为I/O而消耗一部分计算资源。综上所述,在对车辆加速性能分类的应用中,本文改进的C4.5算法(HMC4.5)在效率方面远远高于传统的C4.5算法。
5结语
本文基于改进的C4.5算法对车辆加速性能进行分类。基于泰勒中值定理对传统C4.5算法进行了改进,简化了属性选择度量的计算,从而提高了C4.5算法的运行效率。对改进的C4.5算法并行化设计,对Map阶段、Reduce阶段以及主函数3个部分进行了详细设计,进一步提高了算法的执行效率。对原始数据基于MapReduce进行特征提取,生成数据集。将改进后的C4.5算法应用在加速性能判断上,生成決策树模型,并对决策树规则进行阐述。与原C4.5算法相比,在分类准确率没有降低的情况下,改进后的C4.5算法提高了分类效率。
参考文献:
[1]吴旖雯.分类规则挖掘在金融中的应用[D].杭州:浙江大学,2016.
[2]JIAWEI HAN. Data mining:concepte and techniques[M]. America:Elsevier Inc,2012.
[3]TOM, WHITE. Hadoop:the definitive guide[M]. America:O'Reilly Media,Inc,2010.
[4]LARS, GEORGE. HBase:the definitive guide[M]. America:Posts&Telecom Press,2011.
[5]WATHIQ, LAFTAH, AI YASEEN. Hybrid modified K-Means with C4.5 for intrusion dectection systems in multiagent systems[J]. The Scientific World Journal,2015(4):33-34.
[6]PIERO, GIACOMELLI. Mahout cookbook[M]. America:Packt Publishing, 2014.
[7]毛国君,胡殿军,谢松燕.基于分布式数据流的大数据分类模型和算法[J].计算机学报,2017(1):9-12.
[8]CHONGQING WU. MReC4.5:C4.5 ensemble classify-cation with MapReduce[C]. Fourth ChinaGrid Annual Conference,2013:250-251.
(责任编辑:杜能钢)
