基于卷积神经网络的人脸识别研究
解骏+陈玮


摘要:传统的人脸识别多采用浅层结构提取人脸特征,这类方法提取人脸图像能力有限,效果相对较差。针对上述缺陷,提出基于卷积神经网络的高效识别人脸方法。该方法所设计的模型,结合了VGGNet模型的层次结构优势并融合跨层次结构的上采样特征,大大提高了人脸识别的准确性及识别精度。该模型在Caffe下训练出样本集后在MATLAB上得到了验证。
关键词:人脸识别;卷积神经网络;Ubuntu Caffe;MATLAB
DOIDOI:10.11907/rjdk.172221
中图分类号:TP301
文献标识码:A文章编号文章编号:16727800(2018)001002503
Abstract:Traditional face recognition uses shallow structure to extract facial features.This method has limited ability to extract face images, and the effect is relatively poor.With the development of cognitive science and brain science, an efficient face recognition method based on convolutional neural network is proposed.The proposed model combines the hierarchical structure of VGGNet model and combines the sampled features across hierarchical structures,after the model is trained under Caffe, the result is verified on MATLAB.This method greatly improves the accuracy of face recognition and improves the recognition accuracy.
Key Words:face recognition; convolutional neural network; Ubuntu Caffe; MATLAB
0引言
卷積神经网络是近年发展起来的一种高效识别方法。20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时,发现其独特的网络结构可以有效降低反馈神经网络的复杂性,继而提出了卷积神经网络(Convolutional Neural Networks,简称CNN)。现在,CNN已成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了图像前期复杂的预处理,可直接输入原始图像,因而得到了广泛的应用[1]。K.Fukushima在1980年首次提出了新识别机制,随后很多科研工作者对该网络进行了改进[23]。
1神经网络
1.1浅层网络与深层网络
浅层网络通常也叫做传统的神经网络。神经网络来源于尝试寻找生物系统信息处理的数字表示(McCulloch and Pitts,1943;Widrow and Hoff,1960;Rosenblatt,1962;Rumelhart et al.,1986)。这个模型被广泛使用,许多模型过分夸张地宣称其具有生物的可信性[4]。然而,从模式识别的应用角度来说,模仿生物的真实性会带来相当多的限制。因此,应着重研究作为统计模式识别的高效神经网络,即多层感知器[5]。
1.2卷积神经网络
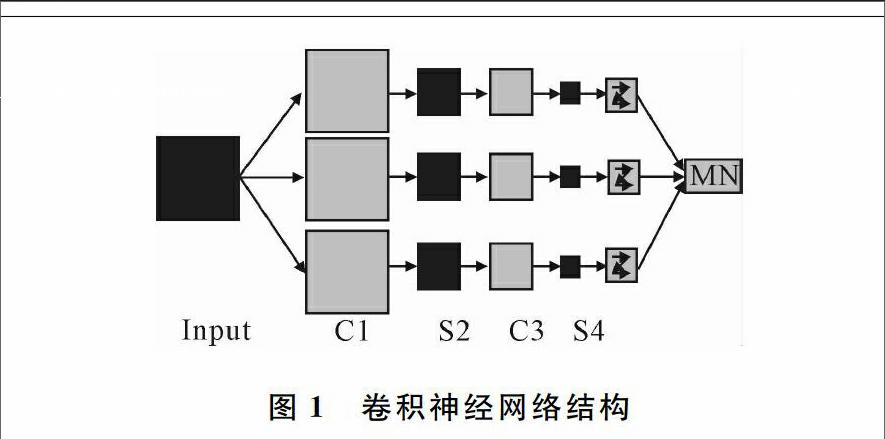
卷积神经网络本质上是一个多层神经网络,但不同于传统的神经网络,每一层上都会有许多的二维平面,并且这些二维平面都含有独立的神经元,大致结构如图1所示[6]。
图1给定一副输入图像,C1层就是卷积神经网络中非常特殊的卷积层。可以看到输入图像经过C1层得到了3张特征映射图,这是因为在C1层上人为设定了3个不同的卷积核,每一张特征映射图都对应于卷积核中的权重[79]。S2层是卷积神经网中常见的下采样层,它通过一个固定窗口对特征图像进行聚合统计,实现特征图像分辨率的下采样。同理,C3层获取更抽象的特征图,S4层继续下采样降低学习难度。最终网络的最后一层或几层设计成全连接层,目的是为了提取更少、更好的特征将其提供给分类器[1011]。
在卷积神经网络中,图1的C层作为特征提取层,该层上输出的每一个神经元与上一层中的局部相连,其值就是上一层中的特征映射值。这样的局部特征只要提取出来,它相对于其它特征的空间位置关系也会确定下来。S层是特征值下采样层,对C层输出的特征映射图中的特征值进行聚合统计[78]。在卷积神经网络中C层和S层的共同作用下,输入图像的特征映射结果具有位移不变性。
由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数,降低了网络参数选择的复杂度。卷积神经网络中的每一个特征提取层(C层)都紧跟一个用来求局部平均与二次提取的计算层(S层),这种特有的两次特征提取结构,使网络在识别时对输入样本有较高的畸变容忍能力[1213]。
2深度学习框架—Caffe
Caffe支持命令行、python和MATLAB接口,核心语言是C++,它是一种操作简单、执行效率高的深度学习框架,可在CPU和GPU之间无缝切换,其创始人是贾杨清。Caffe问世至今,由于它在使用上简洁方便,执行上效率高效,实现上有着清晰的分层网络定义,具有较强的可读性、可移植性和结构化等特点,使其在深度学习领域广受青睐。
2.1Caffe特点
(1)模块化。模块化设计可达到对网络层、损失函数以及数据格式进行独立扩展。
(2)表示和实现分离。一般利用Protocol Buffer语言将Caffe的模型定义写进配置文件,采用任意有向无环图进行构思。Caffe支持网络架构,可依据网络需要自动调节程序或系统所占内存。通过调用某个函数,实现CPU和GPU的切换。
(3)测试覆盖。在Caffe中,任意一个单一的模块都有一个相对应的测试。
(4)Caffe同时提供Python和MATLAB接口。本实验最后需要在Caffe提供MATLAB接口,然后在MATLAB上实现验证结果。
(5)预训练参考模型。对于视觉项目,Caffe有针对性地提供了一系列参考模型,这些模型仅用于非商业或学术领域,它们的License不是BSD。
2.2Caffe架构
(1)数据存储。Caffe通过“Blobs”方式存储数据,即利用四维数组方式存储与传递数据。采用Blobs方式会有一个统一的内存接口,专门用来操作批量图像(以及其它数据)或更新参数。而Models则以Google Protocol Buffers的方式在磁盘中存储,若有大型数据则存储在LevelDB数据库中[13]。
(2)网络层。Caffe层以一个或多个Blobs输入,随即计算出一个或多个Blobs输出。网络是一个整体的操作,而层有两个主要职责:①前向传播,需要输入并产生输出;②反向传播,获得梯度并将它作为输出,再以参数和输入计算出梯度。Caffe提供了一套完整的层类模型,这些层类模型既简单也实用。
(3)网络運行方式。Caffe保存全部的有向无环层图,以保证训练样本准确无误地进行前向传播及反向传播。Caffe作为一个终端到终端的机器学习系统,起始于数据层,终止于loss层。借助某个单一开关,使其网络在CPU与GPU上有效运行。此外在CPU或GPU上,层于层之间结果相同。
(4)训练网络。Caffe在执行一个训练时,凭借的是高效、精确的随机梯度下降算法。在Caffe模型中,微调作为一个标准的方法,适用于已存在的模型或新的架构及数据。当执行新任务时,Caffe即微调旧的模型权重,再依据开发人员需求,将新的权重参数初始化,最终达到缩短训练时间、提高模型精度的要求。
3实验环境和结果分析
3.1实验目的
本实验在Caffe上调用改进的VGGNet网络模型训练样本集,然后在MATLAB上输入一个样本照片,通过MatCaffe接口在MATLAB上调用Caffe训练好的样本集,从而识别输入样本对应样本集中的哪个人、相似度多少。
图2为VGGNet网络结构模型,在fc1和fc2后加入了dropout算法,通过一定的概率屏蔽部分神经元,从而防止随着网络深度的增加出现过拟合问题。同时通过修改每个神经元的非线性激活函数,为relu加快网络的训练时间。通过加入改进后的算法得到了更好的训练曲线,减少了大量的训练时间。
3.2实验环境及数据
本文在Ubuntu64位系统下调用Caffe框架和MATLAB实验,样本图片基于AR人脸库数据,加上实际人脸采样数据,通过MATLAB把所有图片转换成大小为224×224的jpg格式文件,部分如图3所示。
3.3结果分析
在Caffe框架上通过改进的VGGNet模型,将训练样本完成为二进制文件存储,如图4所示,从左到右依次为训练迭代第40次和训练完成输出结果的二进制文件以及文件内容。
在MATLAB上调用训练好的模型输入图片,识别对应的模型里训练好的人名,并给出相似度,如图5所示。
基于卷积神经网络的训练准确率大大高于传统人脸识别算法,而且受光照等外部条件影响较小,本文提出的改进的VGGNet网络训练出来的结果效率高达98%以上,而且训练速度也较快。
4结语
本文基于深度学习的基础框架(卷积神经网络),对当前机器视觉在目标识别上出现的问题进行了研究。根据自然场景复杂多变的情况,设计了一个适合于这种高度变化的数据集上的一种深度卷积神经网络架构,并利用其监督学习的特点完成了模型的训练过程。
本文的网络结构还有许多可以改进和优化的地方。随着21世纪人工智能在机器视觉上的发展,深度学习将在目标识别的技术层面得到跨越,会出现更多的机器视觉产品。
参考文献:
[1]GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[J]. Computer Science,2014(2):580587.
[2]HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2015,37(9):19041916.
[3]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for largescale image recognition[J]. Computer Science,2014(5):241256.
[4]SHELHAMER E, LONG J, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2014,79(10):13371342.
[5]REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, realtime object detection[J]. Computer Science,2016(3):422430.
[6]LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[EB/OL]. http://www.cnblogs.com/zhangyd/p/6596913.html,2015.
[7]KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[J]. Advances in Neural Information Processing Systems,2012,25(2):2029.
[8]REN S, HE K, GIRSHICK R, et al. Faster RCNN: towards realtime object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2016(6):110.
[9]UIJLINGS J R R, SANDE K E A V D. Selective search for object recognition[J]. International Journal of Computer Vision,2013,104(2):154171.
[10]CARREIRA J, RUI C, BATISTA J, et al. Semantic segmentation with secondorder pooling[J]. Lecture Notes in Computer Science,2012,7578(1):430443.
[11]DAN C C, GIUSTI A, GAMBARDELLA L M, et al. Deep neural networks segment neuronal membranes in electron microscopy Images[J]. Advances in Neural Information Processing Systems,2012(25):28522860.
[12]DAI J, HE K, SUN J. Convolutional feature masking for joint object and stuff segmentation[EB/OL]. http://www.taodocs.com/p41599543.html,2014.
[13]盧宏涛,张秦川.深度卷积神经网络在计算机视觉中的应用研究综述[J].数据采集与处理,2016,31(1):117.
(责任编辑:杜能钢)
摘要:传统的人脸识别多采用浅层结构提取人脸特征,这类方法提取人脸图像能力有限,效果相对较差。针对上述缺陷,提出基于卷积神经网络的高效识别人脸方法。该方法所设计的模型,结合了VGGNet模型的层次结构优势并融合跨层次结构的上采样特征,大大提高了人脸识别的准确性及识别精度。该模型在Caffe下训练出样本集后在MATLAB上得到了验证。
关键词:人脸识别;卷积神经网络;Ubuntu Caffe;MATLAB
DOIDOI:10.11907/rjdk.172221
中图分类号:TP301
文献标识码:A文章编号文章编号:16727800(2018)001002503
Abstract:Traditional face recognition uses shallow structure to extract facial features.This method has limited ability to extract face images, and the effect is relatively poor.With the development of cognitive science and brain science, an efficient face recognition method based on convolutional neural network is proposed.The proposed model combines the hierarchical structure of VGGNet model and combines the sampled features across hierarchical structures,after the model is trained under Caffe, the result is verified on MATLAB.This method greatly improves the accuracy of face recognition and improves the recognition accuracy.
Key Words:face recognition; convolutional neural network; Ubuntu Caffe; MATLAB
0引言
卷積神经网络是近年发展起来的一种高效识别方法。20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时,发现其独特的网络结构可以有效降低反馈神经网络的复杂性,继而提出了卷积神经网络(Convolutional Neural Networks,简称CNN)。现在,CNN已成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了图像前期复杂的预处理,可直接输入原始图像,因而得到了广泛的应用[1]。K.Fukushima在1980年首次提出了新识别机制,随后很多科研工作者对该网络进行了改进[23]。
1神经网络
1.1浅层网络与深层网络
浅层网络通常也叫做传统的神经网络。神经网络来源于尝试寻找生物系统信息处理的数字表示(McCulloch and Pitts,1943;Widrow and Hoff,1960;Rosenblatt,1962;Rumelhart et al.,1986)。这个模型被广泛使用,许多模型过分夸张地宣称其具有生物的可信性[4]。然而,从模式识别的应用角度来说,模仿生物的真实性会带来相当多的限制。因此,应着重研究作为统计模式识别的高效神经网络,即多层感知器[5]。
1.2卷积神经网络
卷积神经网络本质上是一个多层神经网络,但不同于传统的神经网络,每一层上都会有许多的二维平面,并且这些二维平面都含有独立的神经元,大致结构如图1所示[6]。
图1给定一副输入图像,C1层就是卷积神经网络中非常特殊的卷积层。可以看到输入图像经过C1层得到了3张特征映射图,这是因为在C1层上人为设定了3个不同的卷积核,每一张特征映射图都对应于卷积核中的权重[79]。S2层是卷积神经网中常见的下采样层,它通过一个固定窗口对特征图像进行聚合统计,实现特征图像分辨率的下采样。同理,C3层获取更抽象的特征图,S4层继续下采样降低学习难度。最终网络的最后一层或几层设计成全连接层,目的是为了提取更少、更好的特征将其提供给分类器[1011]。
在卷积神经网络中,图1的C层作为特征提取层,该层上输出的每一个神经元与上一层中的局部相连,其值就是上一层中的特征映射值。这样的局部特征只要提取出来,它相对于其它特征的空间位置关系也会确定下来。S层是特征值下采样层,对C层输出的特征映射图中的特征值进行聚合统计[78]。在卷积神经网络中C层和S层的共同作用下,输入图像的特征映射结果具有位移不变性。
由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数,降低了网络参数选择的复杂度。卷积神经网络中的每一个特征提取层(C层)都紧跟一个用来求局部平均与二次提取的计算层(S层),这种特有的两次特征提取结构,使网络在识别时对输入样本有较高的畸变容忍能力[1213]。
2深度学习框架—Caffe
Caffe支持命令行、python和MATLAB接口,核心语言是C++,它是一种操作简单、执行效率高的深度学习框架,可在CPU和GPU之间无缝切换,其创始人是贾杨清。Caffe问世至今,由于它在使用上简洁方便,执行上效率高效,实现上有着清晰的分层网络定义,具有较强的可读性、可移植性和结构化等特点,使其在深度学习领域广受青睐。
2.1Caffe特点
(1)模块化。模块化设计可达到对网络层、损失函数以及数据格式进行独立扩展。
(2)表示和实现分离。一般利用Protocol Buffer语言将Caffe的模型定义写进配置文件,采用任意有向无环图进行构思。Caffe支持网络架构,可依据网络需要自动调节程序或系统所占内存。通过调用某个函数,实现CPU和GPU的切换。
(3)测试覆盖。在Caffe中,任意一个单一的模块都有一个相对应的测试。
(4)Caffe同时提供Python和MATLAB接口。本实验最后需要在Caffe提供MATLAB接口,然后在MATLAB上实现验证结果。
(5)预训练参考模型。对于视觉项目,Caffe有针对性地提供了一系列参考模型,这些模型仅用于非商业或学术领域,它们的License不是BSD。
2.2Caffe架构
(1)数据存储。Caffe通过“Blobs”方式存储数据,即利用四维数组方式存储与传递数据。采用Blobs方式会有一个统一的内存接口,专门用来操作批量图像(以及其它数据)或更新参数。而Models则以Google Protocol Buffers的方式在磁盘中存储,若有大型数据则存储在LevelDB数据库中[13]。
(2)网络层。Caffe层以一个或多个Blobs输入,随即计算出一个或多个Blobs输出。网络是一个整体的操作,而层有两个主要职责:①前向传播,需要输入并产生输出;②反向传播,获得梯度并将它作为输出,再以参数和输入计算出梯度。Caffe提供了一套完整的层类模型,这些层类模型既简单也实用。
(3)网络運行方式。Caffe保存全部的有向无环层图,以保证训练样本准确无误地进行前向传播及反向传播。Caffe作为一个终端到终端的机器学习系统,起始于数据层,终止于loss层。借助某个单一开关,使其网络在CPU与GPU上有效运行。此外在CPU或GPU上,层于层之间结果相同。
(4)训练网络。Caffe在执行一个训练时,凭借的是高效、精确的随机梯度下降算法。在Caffe模型中,微调作为一个标准的方法,适用于已存在的模型或新的架构及数据。当执行新任务时,Caffe即微调旧的模型权重,再依据开发人员需求,将新的权重参数初始化,最终达到缩短训练时间、提高模型精度的要求。
3实验环境和结果分析
3.1实验目的
本实验在Caffe上调用改进的VGGNet网络模型训练样本集,然后在MATLAB上输入一个样本照片,通过MatCaffe接口在MATLAB上调用Caffe训练好的样本集,从而识别输入样本对应样本集中的哪个人、相似度多少。
图2为VGGNet网络结构模型,在fc1和fc2后加入了dropout算法,通过一定的概率屏蔽部分神经元,从而防止随着网络深度的增加出现过拟合问题。同时通过修改每个神经元的非线性激活函数,为relu加快网络的训练时间。通过加入改进后的算法得到了更好的训练曲线,减少了大量的训练时间。
3.2实验环境及数据
本文在Ubuntu64位系统下调用Caffe框架和MATLAB实验,样本图片基于AR人脸库数据,加上实际人脸采样数据,通过MATLAB把所有图片转换成大小为224×224的jpg格式文件,部分如图3所示。
3.3结果分析
在Caffe框架上通过改进的VGGNet模型,将训练样本完成为二进制文件存储,如图4所示,从左到右依次为训练迭代第40次和训练完成输出结果的二进制文件以及文件内容。
在MATLAB上调用训练好的模型输入图片,识别对应的模型里训练好的人名,并给出相似度,如图5所示。
基于卷积神经网络的训练准确率大大高于传统人脸识别算法,而且受光照等外部条件影响较小,本文提出的改进的VGGNet网络训练出来的结果效率高达98%以上,而且训练速度也较快。
4结语
本文基于深度学习的基础框架(卷积神经网络),对当前机器视觉在目标识别上出现的问题进行了研究。根据自然场景复杂多变的情况,设计了一个适合于这种高度变化的数据集上的一种深度卷积神经网络架构,并利用其监督学习的特点完成了模型的训练过程。
本文的网络结构还有许多可以改进和优化的地方。随着21世纪人工智能在机器视觉上的发展,深度学习将在目标识别的技术层面得到跨越,会出现更多的机器视觉产品。
参考文献:
[1]GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[J]. Computer Science,2014(2):580587.
[2]HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2015,37(9):19041916.
[3]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for largescale image recognition[J]. Computer Science,2014(5):241256.
[4]SHELHAMER E, LONG J, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2014,79(10):13371342.
[5]REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, realtime object detection[J]. Computer Science,2016(3):422430.
[6]LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[EB/OL]. http://www.cnblogs.com/zhangyd/p/6596913.html,2015.
[7]KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[J]. Advances in Neural Information Processing Systems,2012,25(2):2029.
[8]REN S, HE K, GIRSHICK R, et al. Faster RCNN: towards realtime object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2016(6):110.
[9]UIJLINGS J R R, SANDE K E A V D. Selective search for object recognition[J]. International Journal of Computer Vision,2013,104(2):154171.
[10]CARREIRA J, RUI C, BATISTA J, et al. Semantic segmentation with secondorder pooling[J]. Lecture Notes in Computer Science,2012,7578(1):430443.
[11]DAN C C, GIUSTI A, GAMBARDELLA L M, et al. Deep neural networks segment neuronal membranes in electron microscopy Images[J]. Advances in Neural Information Processing Systems,2012(25):28522860.
[12]DAI J, HE K, SUN J. Convolutional feature masking for joint object and stuff segmentation[EB/OL]. http://www.taodocs.com/p41599543.html,2014.
[13]盧宏涛,张秦川.深度卷积神经网络在计算机视觉中的应用研究综述[J].数据采集与处理,2016,31(1):117.
(责任编辑:杜能钢)
