传统情感分类方法与基于深度学习的情感分类方法对比分析
段传明
摘要:
情感分类是自然语言处理的一个重要分支,情感分类方法包括传统的基于情感词典的方法和基于机器学习的方法,以及最新的基于深度学习的方法。为了探索情感分类的实现方法和研究进展,对传统的情感分类方法和基于深度学习的情感分类方法进行对比,并对深度学习LSTM原理进行了简要描述,可以发现基于深度学习的情感分类方法在情感分类上具有更大优势。
关键词:
情感分类;神经网络;深度学习;词向量;word2vec;LSTM
DOIDOI:10.11907/rjdk.172867
中图分类号:TP301
文献标识码:A文章编号文章编号:16727800(2018)001002203
Abstract:Sentiment classification is an important branch of natural language processing.Sentiment classification methods include traditional methods, including the semantic lexicon method,and the machine learning method, and the latest method is based on deep learning. In order to explore the realization method and research progress of sentiment classification, compares the traditional methods and the latest method based on deep learning, and gives a brief description of LSTM principle of deep learning, It can be found that the sentiment classification based on deep learning has a greater advantage.
Key Words:sentiment classification; neural network; deep learning; word embedding; word2vec; LSTM
0引言
情感分类一直是自然语言处理的一个重要分支,其目的是为了找出评论者或作者在某些话题上或针对某一产品的观点态度。情感分析在舆情监控、金融投资等方面均有广泛应用。传统的情感分类主要有基于情感词典的方法和基于机器学习的方法,其中基于情感词典的方法在很多方面受限于情感词典的质量和覆盖度,而基于机器学习的方法又受限于由人工构建、抽取的特征。随着近几年深度学习技术在自然语言处理领域取得了巨大进展,越來越多的研究人员开始采用深度学习处理文本分类方法。
1基于情感词典的文本情感分类
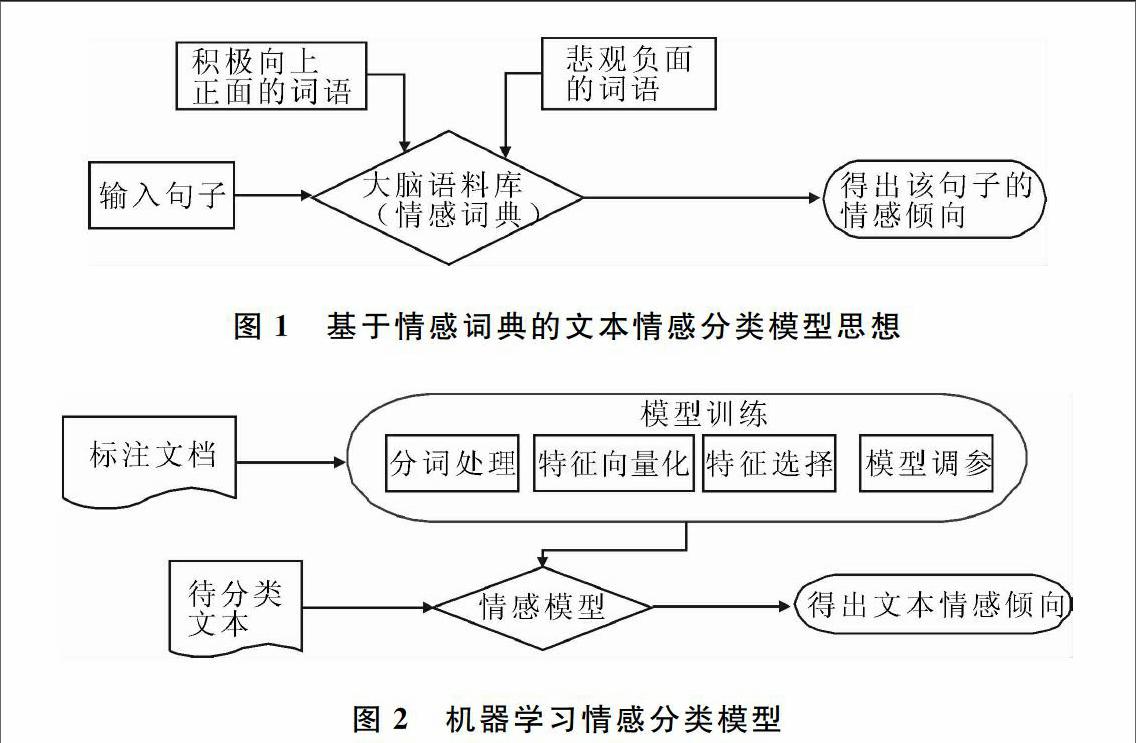
在情感词典的研究方面,2008年,林鸿飞教授等[1]在已颇具成果的研究基础上,构建了一个中文情感词语本题库。基于情感词典的文本分类是对人脑的简单模拟,其核心模式是基于词典和规则,即以情感词典作为判断评论情感极性的主要依据[2]。如图1所示,它是根据以往经验对现有词汇作出评价的一种模型。比如在生活中,通常把糟糕、腻烦归为消极词,把开心、愉悦作为积极词。通过一个句子中出现的感情词,从而判断该句子的感情极性。
根据图1所示的基于情感词典的情感分类方法可以看出,基于情感词典的文本情感分类是容易实现的,其核心在于情感词典(类似于大脑语料库)的训练。基于情感词典感情分类主要依赖于情感词典构建和判断规则质量。而词典构建和判断规则质量两者都需要耗费很多人力,包括人工设计和人们的先验知识。
2基于机器学习的情感分类
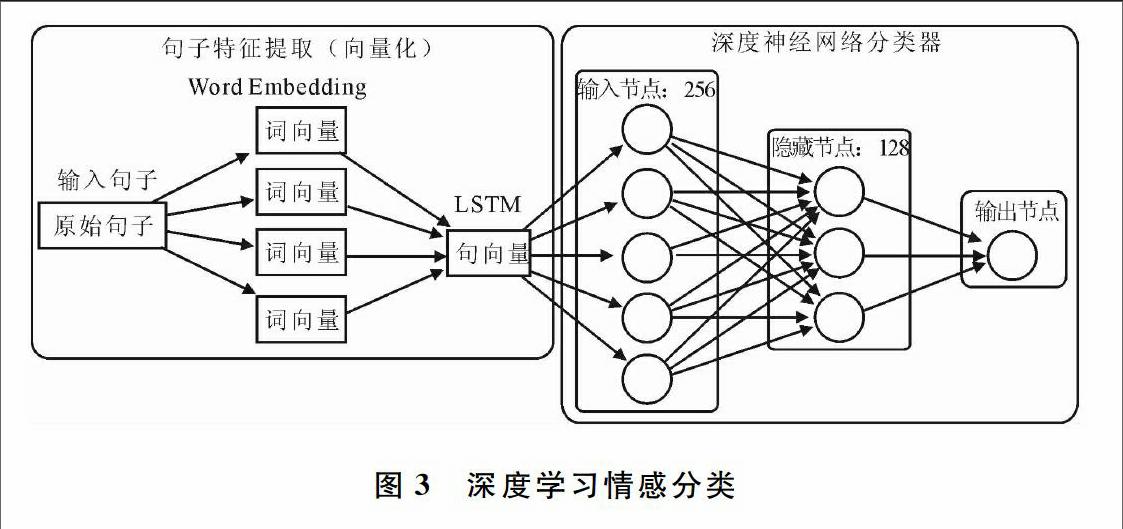
Pang等[3]于2002年初次提出使用标准的机器学习方法解决情感分类问题。由图2可以看出,基于机器学习技术的情感分类研究工作主要需要进行模型的训练。情感分类中常用的特征有Ngram特征、句法特征等[4]。这类方法仍然依赖于人工设计,研究过程中也容易受到人为因素影响。而且人工设计的特征具有领域限制性,在某一领域的特征集不一定适应另一个领域。此外,模型的训练依赖于标注数据集的质量,这些高质量的数据集也需要投入大量人工成本。
3基于深度学习模型的情感分类
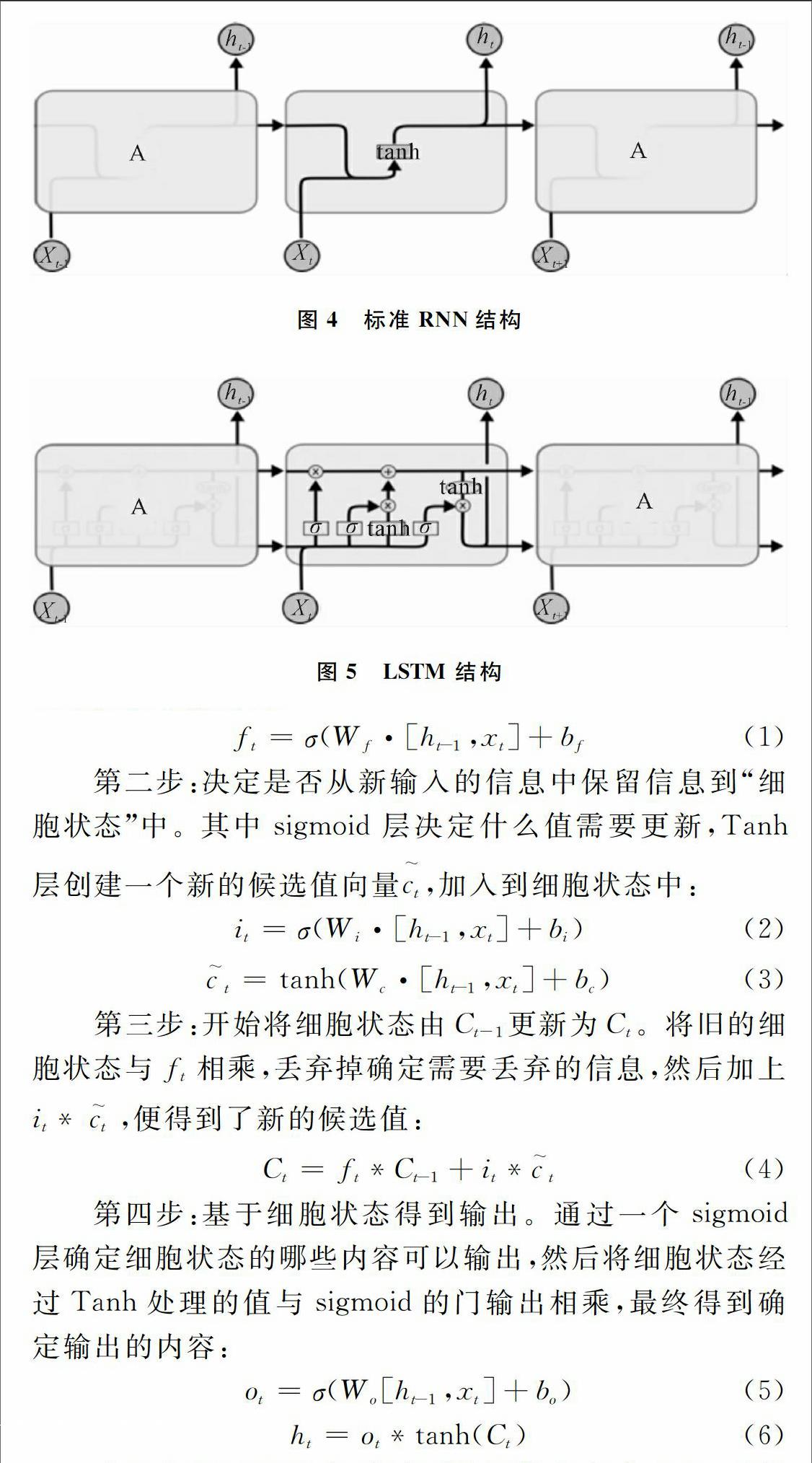
随着神经网络成为目前关注的热点,越来越多学者开始尝试使用深度学习解决情感分类问题。深度学习模型在不同应用问题上的推广能力已得到一定验证[5],情感分析作为自然语言理解的重要应用之一,也受到人们关注。传统神经网络无法处理前后关联的问题(例如一个句子),而深度学习模型RNN解决了该问题。然而,随着距离与先验知识的增加,RNN会出现梯度消息或梯度爆炸的情况,因而无法解决长久依赖的问题。而长短记忆神经网络的引入——通常称为LSTM,解决了以上问题。现有的深度学习方法主要分为两个步骤:①将需要分类的评论语料表达称为语义词向量(Word Embedding);②通过不同的语义合成方法用词向量得到所对应句子或文档的特征表达式,最后通过深度神经网络进行分类。具体过程如图3所示。
3.1语义词向量表达
在自然语言处理中,很重要的一个问题是如何将一个句子用向量表示。传统的文档表示方法几乎都是基于BOW(Bag of Words)的方法。词袋模型最初用在文本分类中,将文档表示成一种特征矢量。它的核心思想是对于一个文本,假定忽略文本中的次序和语法、句法,仅看成这些词汇的排列组合,并且文本中的词汇没有任何关系。简单而言就是将每篇文档都看成一个袋子,然后看袋子里有些什么词汇,并将其分类。所以传统的词袋模型方法存在以下问题:①极高的维度。文本向量的维数与训练数据集中出现的所有单词数目一样多,会造成维度过高,而且如果某一词汇在训练集中未出现过,则会忽视这个词,在测试集中无法成为该文本特征;②基于词袋表示的文档向量极度稀疏,不利于一些自然语言处理任务;③由于词袋法认为词与词之间没有关系,因此它很难表示一个句子或一篇短文的语义;④在不同的语境下,词袋法很难区分同一个词的意义[6]。
随着深度学习的发展,研究人员Mikolov[78]提出了word2vec模型,使传统的词袋模型问题在很大程度上得到改善。Word2vec的思想概括而言即通过高维向量表示词语,而且相近词语会放在相近位置。所以word2vec适合处理序列数据,因为序列局部间的数据有着很大关联。通过word2vec即可训练语料库模型,获得词向量,而且词向量的高维性解决了词语多方向发散问题,从而保证了模型的稳定性。
Word2vec模型有两种,分别是CBOW模型与Skipgram模型。其中CBOW模型通过上下文估测当前词,Skip_gram模型则相反,通过当前词估测上下文[78]。
3.2句子向量
通过不同的语义合成(Semantic Composition)方法用词向量得到所对应句子或文档的特征表达。现有合成方法主要基于语义合成性原理(Principle of Compositionality)[9],该原理指出,长文本(如一个句子、一篇文档)的语义由其子成分(如词汇、短语)语义按不同规则组合而成。本质上讲,语义合成就是利用原始词向量合成更高层次的文本特征向量[10]。
3.3LSTM
LSTM是一种RNN的特殊类型,可以学习长久依赖信息。所有RNN都具有一种重复神经网络模块的链式形式。在标准的 RNN 中,该重复模块只有一个非常简单的结构,例如一个Tanh层,如图4所示。而LSTM的“记忆细胞”通过刻意设计避免了长期依赖问题,如图5所示。
LSTM通过一种精心设计称为门(gate)的结构控制cell状态,直接在整个并向中删减或增加信息。一个LSTM有3个门控制cell的状态,关键门的主要操作有以下步骤,其中it、ft、ot和Ct分别表示t时刻对应的3种门结构和细胞状态。
第一步:忘记门,决定从“细胞状态中丢弃什么信息”,这个决定是通过 sigmoid 中的“遗忘层”实现的。以当前层的输入xt和上一层的输出ht-1作为输入,在t-1时刻的细胞状态输出为:
由于LSTM通过各种“门”从细胞状态中忘记、更新信息,从而可以更好地解决长期依赖问题,对于一段文字也可以更好地学习句子前后的语义,因而已被成功应用于情感分类问题中。
4传统情感分类与深度学习情感分类比较
传统情感分类与基于深度学习的情感分类总结如表1所示。
5结语
本文对传统情感分类方法与基于深度学习的情感分类方法进行对比分析,可以得到以下结论:①基于情感词典的文本情感分类方法过度依赖于情感词典质量,此外情感词典的构建费时又费力,而基于机器学习的情感分类方法需要高质量的特征构造和选取。这些都是传统情感分类的一些弊端;②基于深度学习抽象特征,可避免人工提取特征的工作,而且通过word2vec技术模拟词语之间的联系,有局部特征抽象化以及记忆功能,在情感分类中具有很大优势。
参考文献:
[1]徐琳宏,林鸿飞,赵晶. 情感语料库的构建和分析[J]. 中文信息学报,2008(1):116122.
[2]NASUKAWA T,YI J.Sentiment analysis: capturing favorability using natural language processing[C].Proc of Int Conf on Knowledge Capture.New York:ACM,2003:7077.
[3]PANG B, LEE L, VAITHYANATHAN S. Thumbs up?:sentiment classification using machine learning techniques[C].Proc of Empirical Methods in Natural Language Processing. Cambridge, MA:MIT Press,2002: 7986.
[4]余凱,贾磊,陈雨强,等. 深度学习的昨天、今天和明天[J]. 计算机研究与发展,2013,50(9):17991804.
[5]冯时,付永陈,阳锋,等.基于依存句法的博文情感倾向分析研究[J].计算机研究与发展,2012,49(11):23952406.
[6]唐明,朱磊,邹显春.基于Word2Vec的一种文档向量表示[J]. 计算机科学,2016,43(6):214217,269.
[7]MIKOLOV T,CHEN K, CORRADO G, et al.Efficient estimation of word representations in vector space[J].Computer Science,2013.
[8]MIKOLOV T,YIH W,ZWEIG G.Liguistic regularities in continuous space word representations[C].HLTNAACL,2013:746751.
[9]FREGE G.On sense and nominatum[J]. Philosophy of Science,1949,59(16):3539.
[10]陈龙,管子玉,何金红,等. 情感分类研究进展[J]. 计算机研究与发展,2017,54(6):11501170.
(责任编辑:黄健)
摘要:
情感分类是自然语言处理的一个重要分支,情感分类方法包括传统的基于情感词典的方法和基于机器学习的方法,以及最新的基于深度学习的方法。为了探索情感分类的实现方法和研究进展,对传统的情感分类方法和基于深度学习的情感分类方法进行对比,并对深度学习LSTM原理进行了简要描述,可以发现基于深度学习的情感分类方法在情感分类上具有更大优势。
关键词:
情感分类;神经网络;深度学习;词向量;word2vec;LSTM
DOIDOI:10.11907/rjdk.172867
中图分类号:TP301
文献标识码:A文章编号文章编号:16727800(2018)001002203
Abstract:Sentiment classification is an important branch of natural language processing.Sentiment classification methods include traditional methods, including the semantic lexicon method,and the machine learning method, and the latest method is based on deep learning. In order to explore the realization method and research progress of sentiment classification, compares the traditional methods and the latest method based on deep learning, and gives a brief description of LSTM principle of deep learning, It can be found that the sentiment classification based on deep learning has a greater advantage.
Key Words:sentiment classification; neural network; deep learning; word embedding; word2vec; LSTM
0引言
情感分类一直是自然语言处理的一个重要分支,其目的是为了找出评论者或作者在某些话题上或针对某一产品的观点态度。情感分析在舆情监控、金融投资等方面均有广泛应用。传统的情感分类主要有基于情感词典的方法和基于机器学习的方法,其中基于情感词典的方法在很多方面受限于情感词典的质量和覆盖度,而基于机器学习的方法又受限于由人工构建、抽取的特征。随着近几年深度学习技术在自然语言处理领域取得了巨大进展,越來越多的研究人员开始采用深度学习处理文本分类方法。
1基于情感词典的文本情感分类
在情感词典的研究方面,2008年,林鸿飞教授等[1]在已颇具成果的研究基础上,构建了一个中文情感词语本题库。基于情感词典的文本分类是对人脑的简单模拟,其核心模式是基于词典和规则,即以情感词典作为判断评论情感极性的主要依据[2]。如图1所示,它是根据以往经验对现有词汇作出评价的一种模型。比如在生活中,通常把糟糕、腻烦归为消极词,把开心、愉悦作为积极词。通过一个句子中出现的感情词,从而判断该句子的感情极性。
根据图1所示的基于情感词典的情感分类方法可以看出,基于情感词典的文本情感分类是容易实现的,其核心在于情感词典(类似于大脑语料库)的训练。基于情感词典感情分类主要依赖于情感词典构建和判断规则质量。而词典构建和判断规则质量两者都需要耗费很多人力,包括人工设计和人们的先验知识。
2基于机器学习的情感分类
Pang等[3]于2002年初次提出使用标准的机器学习方法解决情感分类问题。由图2可以看出,基于机器学习技术的情感分类研究工作主要需要进行模型的训练。情感分类中常用的特征有Ngram特征、句法特征等[4]。这类方法仍然依赖于人工设计,研究过程中也容易受到人为因素影响。而且人工设计的特征具有领域限制性,在某一领域的特征集不一定适应另一个领域。此外,模型的训练依赖于标注数据集的质量,这些高质量的数据集也需要投入大量人工成本。
3基于深度学习模型的情感分类
随着神经网络成为目前关注的热点,越来越多学者开始尝试使用深度学习解决情感分类问题。深度学习模型在不同应用问题上的推广能力已得到一定验证[5],情感分析作为自然语言理解的重要应用之一,也受到人们关注。传统神经网络无法处理前后关联的问题(例如一个句子),而深度学习模型RNN解决了该问题。然而,随着距离与先验知识的增加,RNN会出现梯度消息或梯度爆炸的情况,因而无法解决长久依赖的问题。而长短记忆神经网络的引入——通常称为LSTM,解决了以上问题。现有的深度学习方法主要分为两个步骤:①将需要分类的评论语料表达称为语义词向量(Word Embedding);②通过不同的语义合成方法用词向量得到所对应句子或文档的特征表达式,最后通过深度神经网络进行分类。具体过程如图3所示。
3.1语义词向量表达
在自然语言处理中,很重要的一个问题是如何将一个句子用向量表示。传统的文档表示方法几乎都是基于BOW(Bag of Words)的方法。词袋模型最初用在文本分类中,将文档表示成一种特征矢量。它的核心思想是对于一个文本,假定忽略文本中的次序和语法、句法,仅看成这些词汇的排列组合,并且文本中的词汇没有任何关系。简单而言就是将每篇文档都看成一个袋子,然后看袋子里有些什么词汇,并将其分类。所以传统的词袋模型方法存在以下问题:①极高的维度。文本向量的维数与训练数据集中出现的所有单词数目一样多,会造成维度过高,而且如果某一词汇在训练集中未出现过,则会忽视这个词,在测试集中无法成为该文本特征;②基于词袋表示的文档向量极度稀疏,不利于一些自然语言处理任务;③由于词袋法认为词与词之间没有关系,因此它很难表示一个句子或一篇短文的语义;④在不同的语境下,词袋法很难区分同一个词的意义[6]。
随着深度学习的发展,研究人员Mikolov[78]提出了word2vec模型,使传统的词袋模型问题在很大程度上得到改善。Word2vec的思想概括而言即通过高维向量表示词语,而且相近词语会放在相近位置。所以word2vec适合处理序列数据,因为序列局部间的数据有着很大关联。通过word2vec即可训练语料库模型,获得词向量,而且词向量的高维性解决了词语多方向发散问题,从而保证了模型的稳定性。
Word2vec模型有两种,分别是CBOW模型与Skipgram模型。其中CBOW模型通过上下文估测当前词,Skip_gram模型则相反,通过当前词估测上下文[78]。
3.2句子向量
通过不同的语义合成(Semantic Composition)方法用词向量得到所对应句子或文档的特征表达。现有合成方法主要基于语义合成性原理(Principle of Compositionality)[9],该原理指出,长文本(如一个句子、一篇文档)的语义由其子成分(如词汇、短语)语义按不同规则组合而成。本质上讲,语义合成就是利用原始词向量合成更高层次的文本特征向量[10]。
3.3LSTM
LSTM是一种RNN的特殊类型,可以学习长久依赖信息。所有RNN都具有一种重复神经网络模块的链式形式。在标准的 RNN 中,该重复模块只有一个非常简单的结构,例如一个Tanh层,如图4所示。而LSTM的“记忆细胞”通过刻意设计避免了长期依赖问题,如图5所示。
LSTM通过一种精心设计称为门(gate)的结构控制cell状态,直接在整个并向中删减或增加信息。一个LSTM有3个门控制cell的状态,关键门的主要操作有以下步骤,其中it、ft、ot和Ct分别表示t时刻对应的3种门结构和细胞状态。
第一步:忘记门,决定从“细胞状态中丢弃什么信息”,这个决定是通过 sigmoid 中的“遗忘层”实现的。以当前层的输入xt和上一层的输出ht-1作为输入,在t-1时刻的细胞状态输出为:
由于LSTM通过各种“门”从细胞状态中忘记、更新信息,从而可以更好地解决长期依赖问题,对于一段文字也可以更好地学习句子前后的语义,因而已被成功应用于情感分类问题中。
4传统情感分类与深度学习情感分类比较
传统情感分类与基于深度学习的情感分类总结如表1所示。
5结语
本文对传统情感分类方法与基于深度学习的情感分类方法进行对比分析,可以得到以下结论:①基于情感词典的文本情感分类方法过度依赖于情感词典质量,此外情感词典的构建费时又费力,而基于机器学习的情感分类方法需要高质量的特征构造和选取。这些都是传统情感分类的一些弊端;②基于深度学习抽象特征,可避免人工提取特征的工作,而且通过word2vec技术模拟词语之间的联系,有局部特征抽象化以及记忆功能,在情感分类中具有很大优势。
参考文献:
[1]徐琳宏,林鸿飞,赵晶. 情感语料库的构建和分析[J]. 中文信息学报,2008(1):116122.
[2]NASUKAWA T,YI J.Sentiment analysis: capturing favorability using natural language processing[C].Proc of Int Conf on Knowledge Capture.New York:ACM,2003:7077.
[3]PANG B, LEE L, VAITHYANATHAN S. Thumbs up?:sentiment classification using machine learning techniques[C].Proc of Empirical Methods in Natural Language Processing. Cambridge, MA:MIT Press,2002: 7986.
[4]余凱,贾磊,陈雨强,等. 深度学习的昨天、今天和明天[J]. 计算机研究与发展,2013,50(9):17991804.
[5]冯时,付永陈,阳锋,等.基于依存句法的博文情感倾向分析研究[J].计算机研究与发展,2012,49(11):23952406.
[6]唐明,朱磊,邹显春.基于Word2Vec的一种文档向量表示[J]. 计算机科学,2016,43(6):214217,269.
[7]MIKOLOV T,CHEN K, CORRADO G, et al.Efficient estimation of word representations in vector space[J].Computer Science,2013.
[8]MIKOLOV T,YIH W,ZWEIG G.Liguistic regularities in continuous space word representations[C].HLTNAACL,2013:746751.
[9]FREGE G.On sense and nominatum[J]. Philosophy of Science,1949,59(16):3539.
[10]陈龙,管子玉,何金红,等. 情感分类研究进展[J]. 计算机研究与发展,2017,54(6):11501170.
(责任编辑:黄健)
