基于深度神经网络的在线协作学习交互文本分类方法
甄园宜 郑兰琴
摘要:有效的在线协作学习可显著改善在线教学质量,而对在线协作学习过程的实时分析、监控和干预是促进协作学习行为有效发生的关键,这有赖于对在线协作学习交互文本的精准分类。为避免人工编码和传统机器学习方法分类效果欠佳的不足,采用基于深度神经网络的卷积神经网络(CNN)、长短时记忆(LSTM)、双向长短时记忆(Bi-LSTM)等模型构建面向在线协作学习交互文本的分类模型,以Word2Vec作为词向量,提出了包含数据收集整理、文本标签标注、数据预处理、词嵌入、数据采样、模型训练、模型调参和模型评价等步骤的在线协作学习交互文本自动分类方法。以知识语义类、调节类、情感类、问题类和无关信息类等作为交互文本的类别划分,对51组大学生所产生的16047条在线协作学习交互文本进行分类后发现:Bi-LSTM模型的分类效果最好,其整体准确率为77.42%;各文本分类模型在问题类、无关信息类交互文本上的准确率较低;CNN模型和LSTM模型在问题类交互文本上的分类效果更佳。该方法在面向在线协作学习的知识掌握度评估、学习活动维持、消极学习情绪干预、学习预警与提示等方面具有较高的应用价值。
关键词:在线协作学习;深度学习;深度神经网络;交互文本;文本分类
中图分类号:G434? ?文献标识码:A? ? 文章编号:1009-5195(2020)03-0104-09? doi10.3969/j.issn.1009-5195.2020.03.012
*基金项目:国家自然科学基金青年项目“基于教育知识图谱的在线协作学习交互分析关键技术研究”(61907003);北京师范大学教育学部2019年度学科建设综合专项资金资助(2019QNJS010)。
作者简介:甄园宜,硕士研究生,北京师范大学教育学部教育技术学院(北京 100875);郑兰琴(通讯作者),博士,副教授,硕士生导师,北京师范大学教育学部教育技术学院(北京 100875)。
一、引言
协作学习是指学生以小组形式参与,为达到共同的学习目标,在一定的激励机制下最大化个人和他人习得成果而互助合作的一切相关行为(黄荣怀,2003)。在线协作学习因不受时空限制、灵活有效的优势而成为在線学习的重要方式。其作为促进学生问题解决、知识建构和合作交流等高阶技能发展的重要手段,显著提高了在线教育的质量和效果(琳达·哈拉西姆等,2015)。Dillenbourg等(2007)指出,不应泛泛地研究“协作”,而应深入地研究“交互”,因为交互是理解协作学习本质的关键。目前,许多研究通过对在线交互文本的分类来分析学习者的交互行为、认知、情感倾向以及批判性思维。如柴阳丽等(2019)将在线协作学习交互文本分为信息共享、协商讨论、综合评论、新问题的产生、新问题的讨论、新问题的总结等六个类别,据此提出在线对话改进策略。冷静等(2018)把在线协作学习者的批判性思维编码为五类,即辨识、理解、分析、评价和创新,进而发现参与在线协作学习有助于学生批判性思维的提高。由此可见,对在线协作学习交互文本进行精准、高效地分类是提升协作学习效果的重要基础,且对于教师的实时反馈和干预也具有重要意义和价值。
然而,已有研究在对在线协作学习中的交互文本进行分类时,大多采用人工编码或传统机器学习的方法。例如,郝祥军等(2019)在对4844条在线协作学习交互文本进行分类时,首先对编码人员进行编码规则培训,而后采用两人一组背对背的方式进行编码,并对编码结果进行一致性检验,最后再通过协商确定有争议文本的编码。Zhang等(2019)选取一元语法(Unigrams)、二元语法(Bigrams)和文本长度等作为交互文本的特征,依据学习者贡献类型将在线协作学习交互文本划分为提问、引用、立论和阐述等四类。由此可见,已有的在线协作学习交互文本分类方法的人工依赖性较强且在分类结果的产生上具有滞后性,还会因未能对交互过程文本进行语义层面的特征表示而导致分类准确率较低。因此,如何对在线协作学习交互文本进行精准分类是目前亟待解决的问题。
随着自然语言处理(Natural Language Processing,NLP)技术的日渐成熟,利用计算机对人类特有的书面形式和口头语形式的自然语言信息进行处理和加工的能力不断增强(冯志伟,1997)。研究表明,基于深度神经网络和预训练词向量的文本分类方法表现优良(宗成庆等,2019)。深度神经网络(Deep Neural Network,DNN)是有多个隐藏层的多层感知机(Multi-Layer Perceptron,MLP),由输入层、隐藏层和输出层组成(Seide et al.,2011)。深度神经网络能够从大量的原始数据中自动提取高层特征并有效表征输入空间,使得其在多个领域表现良好(Sze et al.,2017)。因此,本研究采用深度神经网络构建在线协作学习交互文本分类模型,以对在线协作学习过程中产生的交互文本进行实时精准分类,进而为在线协作学习的实时分析和监控提供支撑。
二、文献综述
1.在线协作学习交互文本分类研究
对在线交互文本进行分类,不仅有助于快速了解学习者在进行交互时的言语特征、行为特征、交互模式和进展状况,还能够捕捉学习者在进行交互时的情感倾向和知识建构模式。在协作学习领域,相关研究主要围绕协作学习的言语交互类型和交互行为类型展开。例如Rafaeli等(1997)对协作学习过程中的言语交互类型进行分析后,将其分为单向交互、双向交互和互动式交互,其中单向交互是指一位学习者发出信息而其他学习者没有应答;双向交互是指一位学习者发出信息后其他学习者发出应答信息;互动式交互是指一位学习者发出信息后,其他学习者应答并引起下一轮的交互。此外,针对交互过程中的行为特征,也有研究从信息交流序列、知识建构和学习资源等视角出发,采用人工编码的方式对交互行为进行分类。例如Capponi等(2010)基于交互行为的序列特征将协作学习中的交互行为分为信息交换、矛盾冲突、协商、达成共识、忽视他人意见、问题解决、帮助信息、教师评价等八类。Hou等(2011)把在线协作学习的知识建构行为分为知识相关类、任务协调类、社会交往类、跑题类等四种。Lee等(2011)收集11位研究生在为期6周的异步协作学习过程中产生的662条文本数据,将其分为社会协调、学习资源、学习资源整合利用等三类。
2.在线协作学习交互文本的分类方法研究
除采用人工编码的方法外,也有研究采用机器学习算法对在线协作学习文本进行分类。例如,Xie等(2018)基于57名美国大学生在为期16周的课程学习中产生的4083条讨论记录,使用逻辑回归(Logistic Regression)和自适应增强(AdaBoost)算法将其分为领导者信息和常规信息,以识别学生在学习过程中的领导力行为,基于这两个算法自动编码结果的F1值分别为68.6%和72.2%。Liu等(2017)基于6650名K-12教师在学习平台OPOP上持续4个月参与在线协作学习所产生的17624条数据,以词频-逆向文件频率(Term Frequency-Inverse Documnt Frequency,TF-IDF)作为词向量进行文档表示,并使用朴素贝叶斯算法将其分为技术描述、技术分析、技术反思、个人描述、个人分析和个人反思等六类,以实现对教师反思思维等级的预测。Tao等(2018)开发了包含可视化协作学习交互文本自動分析功能的主意线索地图工具,可根据贡献类型,利用支持向量机、朴素贝叶斯等算法将交互文本自动分为提问、引用、理论描述和阐述等四类,以帮助学生监控任务进展、个人贡献度和协作网络关系,从而达到提升学习效果的目的。
综上所述,目前对在线协作学习交互文本的分类多采用人工编码和传统机器学习算法两种方式。在使用人工编码方式进行文本分类时,人工依赖性强且无法进行实时分类;在采用传统机器学习算法进行文本分类时,选取的文本特征较为单一,且难以捕捉文本上下文语义信息,导致文本分类准确率较低。
3.计算机领域文本分类技术研究现状
传统机器学习领域中的文本分类方法主要包括三个步骤,即特征工程、特征选择以及分类算法选择(Kowsari et al.,2019)。在特征工程中多选用词袋、词频-逆向文件频率、词性标注、名词短语(Lewis et al.,1992)等作为文本特征。为剔除特征工程中的噪声,需要进行特征选择,所采用的主要方法有去停用词、L1正则化(Ng,2004)和互信息(Cover et al.,2012)等。常用的机器学习分类算法有逻辑回归、朴素贝叶斯和支持向量机等。然而,传统机器学习中的文本分类方法存在数据稀疏、计算资源浪费大等问题。
深度学习算法因其能够避免由于数据稀疏、人工提取特征而导致的偏差,被广泛应用于文本分类任务中(Zhang et al.,2015)。基于深度学习算法的文本分类方法优化研究主要从词向量的表示和分类模型的构建两个方面对原有方法进行改进。例如,Kim(2014)基于Google新闻预训练所获得的1000亿个Word2Vec词向量,通过变化词向量的形式(即随机初始化、单通道传统Word2Vec、单通道训练后的Word2Vec、双通道词向量)构建了4个卷积神经网络(Convolutional Neural Networks,CNN)变体模型,并在电影评论(二分类)、斯坦福情感资料库(五分类)、斯坦福情感资料库(二分类)、主客观句库(二分类)、顾客商品评论(二分类)、MPQA两极评论(二分类)等6个数据集上进行文本分类实验,发现各模型分类结果的F1值在45.0%到89.6%之间。Lai等(2015)为避免人工设计文本分类的特征和规则,构建了双向循环神经网络(Recurrent Neural Network,RNN)和最大池化层的组合模型,使用RNN模型提取文本的上下文信息,并基于最大池化层自动提取对文本分类起关键作用的词语,并在20-Newsgroups、Fudan Set、 ACL Anthology Network和Sentiment Treebank等4个公开数据集上进行了分类实验,其分类结果的F1值在32.70%到93.12%之间。Li等(2018a)提出了基于优化的TF-IDF和加权Word2Vec的文本表示模型,并结合卷积神经网络对文本进行分类,实验语料为网易新闻语料库(六分类)的24000篇新闻和复旦文本分类语料库(八分类)的7691篇新闻,其分类结果的F1值分别为95.85%和96.93%。Vargas-Calderón等 (2019)基于波哥大市民在6个月内产生的263万余条推特文本数据,使用Word2Vec作为词向量,进行文本聚类以发现有共同话题的市民。Jang等 (2019)基于12万余篇新闻文章和29万余条推特文本数据,使用Word2Vec作为词向量,CNN作为分类器对数据进行是否相关的二分类研究,并对两种词向量训练方式(即Continuous Bag-of-Words和Skip-Gram)的分类精度进行了比较,结果表明使用Continuous Bag-of-Words词向量训练方式的新闻文章分类结果的F1值为93.51%,而使用Skip-Gram训练方式的推特文章分类结果的F1值为90.97%。
此外,也有研究者通过构建更优的神经网络模型来提升文本分类模型的效果。例如,Joulin 等(2016)提出采用FASText方法进行文本分类,结果表明其具有训练速度快、耗能较低等优点。Felbo 等(2017)提出了基于Embedding层、双向长短时记忆(Bidirectional Long Short-Term Memory,Bi-LSTM)模型和注意力机制的DeepMoji模型,将Embedding层和Bi-LSTM作为输入以得到文档的向量表征,再将向量输入到softmax层以得到在各分类标签上的概率分布,进而获得分类结果。Yao等 (2019)采用图卷积网络(Graph Convolutional Networks,GCN)模型,通过构建包含词节点和文档节点的大型异构文本图,并利用Co-occurrence信息对全局词语进行建模的方式,基于对节点的分类得到文本分类结果。
综上所述,学者们出于不同的研究目标开展了诸多有关在线协作学习交互文本分类的研究,其所使用的方法多为人工编码或逻辑回归、支持向量机等传统机器学习方法,这些方法存在人工依赖性强且分析结果滞后等不足。鉴于新兴的基于深度学习的自然语言处理技术在文本分类中的效果良好,本研究采用深度神经网络构建在线协作学习交互文本的自动分类模型,以期为学习者提供个性化的学习支持服务。
三、在线协作学习交互文本分类模型构建
1.分类标准
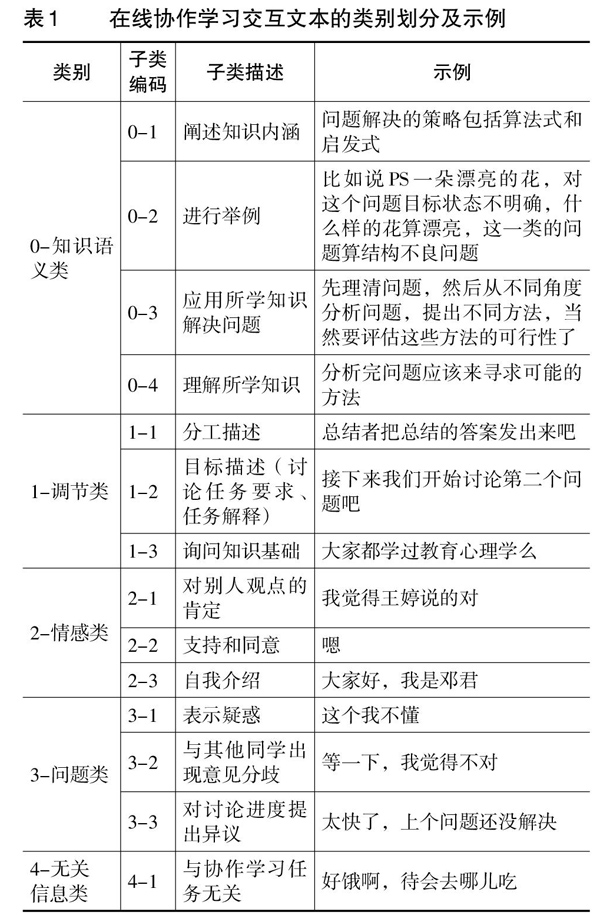
本研究基于郑兰琴(2015)对协作学习交互分析的研究,将在线协作学习交互文本分为知识语义类、调节类、情感类、问题类和无关信息类等五类。其具体的类别划分及示例如表1所示。
2.自动分类流程
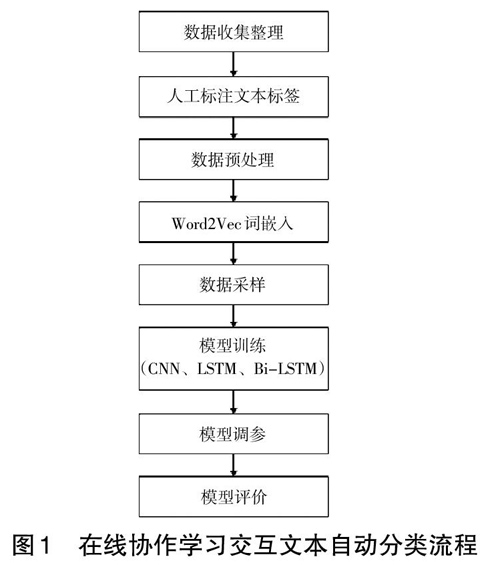
本研究基于深度学习技术设计了如图1所示的在线协作学习交互文本自动分类流程,其主要包括数据收集整理、人工标注文本标签、数据预处理、Word2Vec词嵌入、数据采样、模型训练、模型调参和模型评价等8个步骤。
图1 在线协作学习交互文本自动分类流程
3.数据收集及标注
本研究招募51组大学生开展在线协作学习,通过学习平台自动记录学习过程中的交互文本,并将收集到的交互文本数据集按表1所示的类别标注为0、1、2、3、4等5类。例如,“问题解决策略主要包含算法式和启发式”属于知识语义类,类型序号标注为0;“这个我不懂,好难啊!”属于问题类,类型序号标注为3。
4.数据预处理
研究主要从以下两个方面对数据进行预处理。一是去除特殊字符和标点,即对交互文本数据集中的特殊字符、空白字符、标点符号等进行纠正或删除,以去除交互文本数据集中的噪声。二是进行分词操作,即利用Jieba分词库对交互文本进行分词操作。Jieba分词库是Python编程环境下被广泛使用的中文分词工具包,其主要的分词操作模式有精确模式、全模式和搜索引擎模式等三种。本研究采用精准模式对交互文本进行分词处理,即按照分词后词频最高的原则对句子做分词操作。
5.向量表示
本研究使用Mikolov等(2013)提出的Word2Vec作为词嵌入的词向量模型,将交互文本转换为计算机能够处理的向量表示方式。该词向量模型所生成的词向量含有语义信息,主要包含通过上下文预测中心词的Continuous Bag-of-Word模型和通过中心词预测上下文的Skip-Gram模型(Rong,2014),其所采用的层次Softmax和负采样算法可提升语义表征性能。
由于本研究的交互文本数据集较小,训练获得的词向量无法涵盖所有词语,因此采用中文类比推理数据集CA8作为词向量(Li et al.,2018b),其共有1348468个中文词语,词向量的维度为300。研究收集到的交互文本数据集共有184680个词,去重后的9079个词中有7500个是语料库中具有的,其余1579个未登录词经检查与语料分类无关,故使用全体向量的均值对其进行表示。
6.数据采样
由于本研究的交互文本数据集中的五类文本在样本量上存在较大差异,即协调类、问题类和无关信息类样本的数量较少,因此针对该文本数据集的分类问题属于不平衡数据分类问题。为避免由于训练集样本数据不平衡而产生分类误差,研究采用合成少数类过采样(Synthetic Minority Over-sampling Technique,SMOTE)与下采样(Under-sampling)相结合的混合采样方式,即通过增加数据集中少数类的数量、减少数据集中多数类的数量以达到数据集的平衡(Chawla et al.,2002)。该种采样方式既减少了语义信息的损失,又使得训练时间不至于过长(Batista et al.,2004)。
7.文本分类器模型
考虑到CNN模型在文本特征选取方面具有较大优势,而长短时记忆(Long Short-Term Memory,LSTM)模型可保留文本的序列信息且双向长短时记忆(Bidirectional Long Short-Term Memory,Bi-LSTM)模型可保留文本序列的上下文信息,因此,研究选取基于深度神经网络的CNN、LSTM和Bi-LSTM模型作为在线协作学习交互文本的分类器模型。
(1)CNN模型
CNN模型由LeCun等(1998)提出并首先被用于图像识别领域,其在图像分类任务中具有良好的表现。CNN模型的基本组成包括输入层、卷积层、池化层、全连接层和输出层,其中卷积层和池化层有多个且一般采用交替设置的架构,即一个卷积层后连接一个池化层,池化层后再连接一个卷积层。Kim(2014)最先将CNN模型应用于文本分类任务,并取得了较好的分类效果。
CNN模型的基本思想如下:假设词xi∈Rk,即句子中的第i个词是一个k维向量;首先对句子进行填充操作,填充后句子的长度变为n,则单个句子可表示为X1:n=x1⊕x2⊕…⊕xn,其中的⊕表示向量连接操作,即整个句子的句向量为所含的每个词的词向量拼接而成的向量;之后,使用卷积核w∈Rhk对句子进行二维卷积操作,即使用卷积得到的h个词产生一个新特征,例如卷积核w在词Xi:i+h-1上卷积生成特征Ci,Ci=f(w·xi:i+h-1+b),其中b∈R是函数的偏置值,f为非线性的激活函数;然后,设定卷积核w的步长为1,并将其应用于句子{x1:h,x2:h,…,xn-h+1:n }上,產生句子矩阵的特征图c,c=[c1,c2,…,cn-h+1 ];最后,遍历整个特征图并进行最大池化操作,找到最大的c值作为特征,
(2)LSTM模型
Hochreiter等 (1997)提出的LSTM模型是RNN模型的一个变种,其因具有时序性且长期依赖问题较弱而被广泛应用于时间序列类模型中。LSTM模型的基本思想如下:假设时间点为t,在整个时间序列内输入的序列X={x1,x2,…,xt},即在文本任务中,X代表一条文本记录,每个时间点的输入表示一条文本记录经过分词后的每个词。在每个时间点t,模型的输入包括当前输入xt、上一时刻隐藏状态的输出ht-1和上一个记忆单元状态ct-1;模型的输出包括当前隐藏状态的输出ht和当前记忆单元状态ct 。LSTM神经单元主要通过控制记忆单元状态ct对上一时刻和当前时刻的输入进行遗忘和输出,通过对遗忘门ft 、输入门it和输出门ot 等三个门控单元的设置,实现记忆单元ct对数据的输入和遗忘,以此获得分类结果。
(3)Bi-LSTM模型
Bi-LSTM模型是为弥补LSTM模型无法捕捉当前计算时刻后文语义信息的缺陷而提出的改进模型。Bi-LSTM模型通过连接反向的LSTM,使得模型既可以提取序列中当前时刻前文的语义信息,也可以提取序列中当前时刻后文的语义信息,从而实现对整个句子关键信息的提取(Schuster et al.,1997)。Bi-LSTM模型的每个LSTM单元的计算方法与LSTM模型一致,但其在得到前向和后向的单元输出后,要做一个矩阵连接的操作,在求和并取平均值后连接一个输出层以得到分类结果。
8.模型调参
在模型调参步骤中,主要使用了Python的sklearn工具包中的GridSearchCV函数进行网格搜索,即将欲调各参数的全部可能值放于一个字典中,然后遍历所有可能的参数组合,通过对各类参数设置情形下模型的准确率进行比较以获得最优的参数组合,进而将其确定为本研究各模型的实际参数。
四、实验与结果
1.实验数据集
本研究基于笔者所在实验室自主开发的在线协作学习平台进行数据收集,一共招募了51个小组参加在线协作学习,每组人数为4人,同一小组的成员在不同的物理空间内进行学习。每个小组的在线协作学习任务均相同,即围绕“教育心理学”课程中“问题解决的策略”章节展开讨论,具体包括问题解决的策略是什么、专家和新手解决问题有何差异、如何培养学生的问题解决能力、如何基于问题解决进行知识建构、结构不良问题的解决过程是什么等5个子任务。在开展协作学习活动之前,小组成员自由选择四种角色(协调者、解释者、总结者和信息搜集者)中的一种。每个小组在线协作学习的平均时长为2个小时。
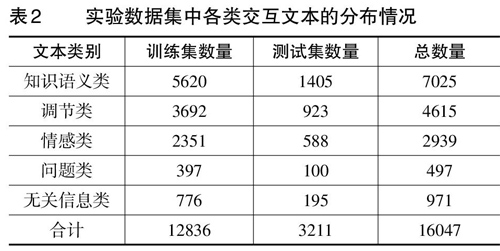
在在线协作学习的过程中,51个小组共产生了16047条交互文本,每组平均约产生315条。为保证交互文本数据集服从真实在线协作学习情景下的数据分布以提高分类模型的泛化能力,本研究保留了全部原始数据。之后,将交互文本数据集分为训练集和测试集,即分别选取每类数据中的80%作为训练集,另20%作为测试集,再将五部分数据合并作为完整的训练集和测试集。知识语义类、调节类、情感类、问题类和无关信息类等五类交互文本的分布情况如表2所示。
2.评价标准
本研究使用正确率(Precision)、召回率(Recall)、F1值和准确率(Accuracy)作为在线协作学习交互文本分类效果的评价指标,将二分类的评价标准在多分类中进行延伸,即在每一个类别中将本类别看作正类,其他类别看作负类。具体计算公式如下所示。
其中,TP表示正确分类的正类数量,FP表示错误分类的正类数量,TN表示正确分类的负类数量,FN表示错误分类的负類数量。Precision表示预测为正类样本的准确性,即被预测为正类的样本中实际正类的比例;Recall表示正类样本被正确预测的比例,即所有正类样本中被预测为正类的比例;F1表示在调和正确率和召回率之后,对分类器性能的综合评判;Accuracy表示分类器的整体准确率。
3.实验模型设置
实验的计算机硬件环境为Intel酷睿 i7-8700 CPU、16G内存,操作系统采用64位Ubuntu。采用Keras框架对三个基于深度神经网络的分类模型进行了搭建,算法的“epochs” 和“batch_size”分别设置为200和64。模型其他具体参数设置如下:(1)CNN模型。基于Kim(2014)等建立的CNN文本分类模型,使用64个大小为7×7的卷积核分别提取文本特征,经过最大池化层处理后,使用 Softmax 函数对在线协作学习文本进行分类。(2)LSTM模型。使用 256个LSTM神经单元进行语义学习(“dropout”设置为0.2),之后连接一个含有10个神经单元的全连接层,最后使用Softmax 函数对在线协作学习文本进行分类(所采用的优化方法为Adam)。(3)Bi-LSTM模型。分别使用100个LSTM神经单元进行文本上下文语义的学习,之后连接一个Softmax 函数对在线协作学习文本进行分类(所采用的优化方法为Adam)。
4.实验结果与分析
利用训练集数据对上述三个文本分类器模型进行训练,获得的分类模型在测试集上进行分类测试的各项指标如表3所示。
由表3可知,Bi-LSTM模型的整体准确率较CNN和LSTM模型高。Bi-LSTM模型在知识语义类、调节类、情感类和无关信息类交互文本上的F1值较另两个模型高,相较CNN模型分别提高了1.33%、4.47%、4.24%和11.49%,相较LSTM模型分别提高了0.33%、4.28%、3.96%和11.39%。但Bi-LSTM模型在问题类交互文本上的分类效果不如CNN模型和LSTM模型,其F1值分别相差3.82%和3.08%。上述结果表明,Bi-LSTM模型可以更好地提取知识语义、调节类、情感类和无关信息类交互文本的语义信息,而在问题类交互文本的语义信息提取上还有待改进。
Bi-LSTM模型在训练集和验证集中的准确率(Training and Validation Accuracy)和Loss值(Training and Validation Loss)的变化曲线如图2所示。可以看出,Bi-LSTM模型在训练过程中,Loss值逐渐缩小,模型准确率逐渐升高至0.97,模型训练过程表现良好。
图2? ?训练集和验证集的准确率和Loss值变化趋势图
图3为Bi-LSTM模型经归一化处理后的混淆矩阵分析结果,其横坐标代表预测标签(Predicted Label,即分类结果),纵坐标代表正确标签(True Label,即实际类型),坐标中的0-4分别代表知识语义类、调节类、情感类、问题类和无关信息类等5种类型的在线协作学习交互文本,矩阵中的数值表示该类交互文本的召回率。从混淆矩阵分析结果可以看出,对角线上的分类预测情况较好,在知识语义类、调节类和情感类在线协作学习交互文本上的表现较优,该结果同样表明Bi-LSTM分类器具有较好的分类效果。
图3? ? 混淆矩阵分析结果
五、讨论与结论
本文使用Word2Vec作为词向量,采用双向长短时记忆(Bi-LSTM)、长短时记忆(LSTM)、卷积神经网络(CNN)等三种深度神经网络模型构建文本分类器,提出了基于深度学习技术的在线协作学习交互文本分类方法。实验结果表明双向长短时记忆模型的分类效果最好,其整体准确率为77.42%,在知识语义类、调节类、情感类、问题类和无关信息类在线协作学习交互文本上的F1值分别达到85.80%、72.88%、83.03%、51.92%和37.13%。各文本分类器在问题类交互文本上的准确率较低,这主要是因为问题类交互文本的数量较少,即在本研究的在线协作学习环境中,涉及学习矛盾冲突和疑惑的交互文本数量较少致使分类模型在该类别的预测效果上不理想。此外,无关信息类交互文本的识别准确率也较低,这是由于无关信息类交互文本与协调类、知识语义类交互文本的特征类似,都是属于就某一话题所进行的讨论,且无关信息类话题的维度较广,故难以对其进行准确分类。由于调节类与情感类交互文本在特征上也呈现出一定程度的交叉,故调节类交互文本的分类效果也有待进一步提升。总之,问题类和无关信息类交互文本的数量较少,造成了数据集不平衡的问题,这影响了各类分类器的分类效果,本研究所采用的混合采样技术、多种分类模型也并不能很好地解决该问题。因此,如何解决在线协作学习交互文本分类中存在的不平衡数据集问题是后续研究的方向。
在线协作学习是一种重要的学习方式。对学习者在线协作学习过程中产生的交互文本进行精准地实时分类,是监控和评价大规模在线协作学习效果的基础,也是通过干预提升在线协作学习效果的前提。例如,依据对知识语义类交互文本的分析,能够对学习者的知识掌握情况进行评估;基于对协调类交互文本的分析可以有效地协调和干预学习过程,从而避免学习者由于任务协调不佳而导致的在线协作学习活动停滞和学习效果不佳等问题;利用问题类交互文本能够知晓学习者所遇到的问题和困难,以便教师及时地提供支持,为学生搭建脚手架,从而提高在线协作学习的效果;基于情感类交互文本能够对在线协作学习过程中出现的消极情绪进行干预;基于无关信息类交互文本可以对在线协作学习过程中出现的跑题现象进行预警和提示,让学习者更加专注地进行学习。因此,构建精准的在线协作学习交互文本的分类模型对于提升在线协作学习的效果具有重要意义和价值。
本研究主要存在以下三方面不足:一是研究中的交互文本数量较少且各类别交互文本的数量差距较大。在未来的研究中,将使用数据增强(Data Augmentation)等方法解决交互文本数据集较小的问题,同时还需解决在线协作学习交互文本分类中现实存在的不平衡数据集问题。二是由于研究所使用的Word2Vec词向量相对固化,因而难以解决一词多意、依据上下文动态转换词向量的问题。后续研究将使用BERT、ERNIE等预训练语言模型生成语义更加准确的词向量。三是研究所构建的神经网络模型的结构相对单一且较为简单。在未来的研究中,将尝试采用更为复杂有效的神经网络模型,并结合Attention、Transformer等算法来优化神经网络的结构,进一步提高在线协作学习交互文本分类的准确率。
参考文献:
[1][加]琳达·哈拉西姆,肖俊洪(2015).协作学习理论与实践——在线教育质量的根本保证[J].中国远程教育,(8):5-16,79.
[2]柴阳丽,陈向东,荣宪举(2019).共享监控和调节视角下 CSCL 在线异步对话分析及改进策略——以 “研究性学习”课程为例[J].电化教育研究, 40(5): 72-80,97.
[3]馮志伟(1997).自然语言的计算机处理[J].中文信息,(4):26-27.
[4]黄荣怀(2003).计算机支持的协作学习——理论与方法[M].北京:人民教育出版社:13.
[5]郝祥军,王帆,彭致君等(2019).群体在线学习过程分析:学习者角色的动态转换[J].现代远距离教育,(3):38-48.
[6]冷静,郭日发(2018).在线协作平台中批判性思维话语分析研究[J].电化教育研究,39(2):26-31.
[7]郑兰琴(2015).协作学习的交互分析方法——基于信息流的视角[M].北京:人民邮电出版社:70.
[8]宗成庆,夏睿,张家俊(2019).文本数据挖掘[M].北京:清华大学出版社:53.
[9]Batista, G. E., Prati, R. C., & Monard, M. C. (2004). A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data[J]. ACM SIGKDD Explorations Newsletter, 6(1):20-29.
[10]Capponi, M. F., Nussbaum, M., & Marshall, G. et al. (2010). Pattern Discovery for the Design of Face-to-Face Computer-Supported Collaborative Learning Activities[J]. Journal of Educational Technology & Society, 13(2):40-52.
[11]Chawla, N. V., Bowyer, K. W., & Hall, L. O. et al. (2002). SMOTE: Synthetic Minority Over-Sampling Technique[J]. Journal of Artificial Intelligence Research, 16(1):321-357.
[12]Cover, T. M., & Thomas, J. A. (2012). Elements of Information Theory[M]. Hoboken: John Wiley & Sons: 54.
[13]Dillenbourg, P., & Fischer, F. (2007). Computer-Supported Collaborative Learning: The Basics[J]. Zeitschrift für Berufs-und Wirtschaftsp?dagogik, 21:111-130.
[14]Felbo, B., Mislove, A., & S?gaard, A. et al. (2017). Using Millions of Emoji Occurrences to Learn Any-Domain Representations for Detecting Sentiment, Emotion and Sarcasm[EB/OL]. [2019-12-12]. https://arxiv.org/pdf/1708.00524.pdf.
[15]Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory[J]. Neural Computation, 9(8):1735-1780.
[16]Hou, H. T., & Wu, S. Y. (2011). Analyzing the Social Knowledge Construction Behavioral Patterns of an Online Synchronous Collaborative Discussion Instructional Activity Using an Instant Messaging Tool: A Case Study[J]. Computers & Education, 57(2):1459-1468.
[17]Jang, B., Kim, I., & Kim, J. W. (2019). Word2Vec Convolutional Neural Networks for Classification of News Articles and Tweets[J]. PLoS ONE, 14(8):1-20.
[18]Joulin, A., Grave, E., & Bojanowski, P. et al. (2016). Bag of Tricks for Efficient Text Classification[EB/OL]. [2019-12-12]. https://arxiv.org/pdf/1607.01759.pdf.
[19]Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification[EB/OL]. [2019-12-12]. https://arxiv.org/pdf/1408.5882.pdf.
[20]Kowsari, K., Meimandi, K. J., & Heidarysafa, M. et al. (2019). Text Classification Algorithms: A Survey[J]. Information, 10(4):67-75.
[21]Lai, S., Xu, L., & Liu, K. et al. (2015). Recurrent Convolutional Neural Networks for Text Classification[C]// Twenty-Ninth AAAI Conference on Artificial Intelligence. Texas, USA:2267-2273.
[22]LeCun, Y. , Bottou, L., & Bengio, Y. et al. (1998). Gradient-Based Learning Applied to Document Recognition[J]. Proceedings of the IEEE, 86(11):2278-2324.
[23]Lee, S. W. Y., & Tsai, C. C. (2011). Identifying Patterns of Collaborative Knowledge Exploration in Online Asynchronous Discussions[J]. Instructional Science, 39(3):321-347.
[24]Lewis, D. D. (1992). An Evaluation of Phrasal and Clustered Representations on a Text Categorization Task[C]// Proceedings of the 15th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Copenhagen: ACM: 37-50.
[25]Li, L., Xiao, L., & Jin, W. et al. (2018a). Text Classification Based on Word2vec and Convolutional Neural Network[C]// International Conference on Neural Information Processing. Cham: Springer:450-460.
[26]Li, S., Zhao, Z., & Hu, R. et al. (2018b). Analogical Reasoning on Chinese Morphological and Semantic Relations[EB/OL]. [2019-12-12]. https://arxiv.org/pdf/1805.06504.pdf.
[27]Liu, Q., Zhang, S., & Wang, Q. et al. (2017). Mining Online Discussion Data for Understanding Teachers Reflective Thinking[J]. IEEE Transactions on Learning Technologies, 11(2):243-254.
[28]Mikolov, T., Chen, K., & Corrado, G. et al. (2013). Efficient Estimation of Word Representations in Vector Space[EB/OL]. [2019-12-12]. https://arxiv.org/pdf/1301.3781.pdf%5D.
[29]Ng, A. Y. (2004). Feature Selection, L1 vs. L2 Regularization, and Rotational Invariance[C]// Proceedings of the Twenty-First International Conference on Machine Learning. Banff: ACM:78-86.
[30]Rafaeli, S., & Sudweeks, F. (1997). Networked Interactivity[J]. Journal of Computer-Mediated Communication, 2(4):243.
[31]Rong, X. (2014). Word2Vec Parameter Learning Explained[EB/OL]. [2019-12-12]. https://arxiv.org/pdf/1411.2738.pdf.
[32]Schuster, M., & Paliwal, K. K. (1997). Bidirectional Recurrent Neural Networks[J]. IEEE Transactions on Signal Processing, 45(11):2673-2681.
[33]Seide, F., Li, G., & Yu, D. (2011). Conversational Speech Transcription Using Context-Dependent Deep Neural Networks[C]// Proceedings of the 12th Annual Conference of the International Speech Communication Association. Florence, Italy: ISCA:437-440.
[34]Sze, V., Chen, Y. H., & Yang, T. J. et al. (2017). Efficient Processing of Deep Neural Networks: A Tutorial and Survey[J]. Proceedings of the IEEE, 105(12):2295-2329.
[35]Tao, D., & Zhang, J. (2018). Forming Shared Inquiry Structures to Support Knowledge Building in a Grade 5 Community[J]. Instructional Science, 46(4):563-592.
[36]Vargas-Calderón, V., & Camargo, J. E. (2019). Characterization of Citizens Using Word2Vec and Latent Topic Analysis in a Large Set of Tweets[J]. Cities, 92:187-196.
[37]Xie, K., Di Tosto, G., & Lu, L. et al. (2018). Detecting Leadership in Peer-Moderated Online Collaborative Learning Through Text Mining and Social Network Analysis[J]. The Internet and Higher Education, 38:9-17.
[38]Yao, L., Mao, C., & Luo, Y. (2019). Graph Convolutional Networks for Text Classification[C]// Proceedings of the AAAI Conference on Artificial Intelligence. Hawaii: AAAI: 7370-7377.
[39]Zhang, J., & Chen, M. (2019). Idea Thread Mapper: Designs for Sustaining Student-Driven Knowledge Building Across Classrooms[C]//13th International Conference on Computer Supported Collaborative Learning. Lyon: ISLS:144-151.
[40]Zhang, W., & Wang, J. (2015). A Collective Bayesian Poisson Factorization Model for Cold-Start Local Event Recommendation[C]// Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Sydney: ACM:1455-1464.
收稿日期 2020-01-10責任编辑 谭明杰
