基于公共词集对长篇小说相似度的研究
郭涛 霸元婕 李绍昂


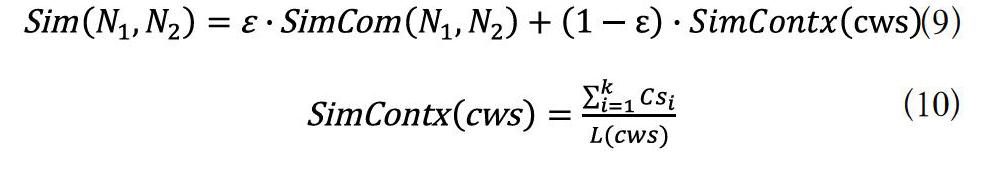
摘 要:传统的文本相似度计算基于向量空间模型(VSM),文本映射成独立的、互不关联的词构成的向量。由于长篇小说具有比普通文本更为复杂的构成元素,以及更加紧密的上下文联系,传统算法忽略词项的上下文联系,并且产生高维向量,因此算法的效率和精度不理想。为此,本文基于公共词集对长篇小说进行相似度计算,并对公共词集进行上下文约束检查,得到关联比较紧密的词集,作为小说的主要特征。实验结果表明,对于某些小说类型,效果有很大的提升。
关键词:公共词集;小说相似度;上下文约束
中图分类号:TP391.1 文献标识码:A
Abstract:Traditional text similarity computation is based on Vector Space Model (VSM),where the text is mapped into independent and unrelated words.Because novels have more complex elements and much closer context than ordinary texts,the traditional algorithm ignores the context of the words and produces the high dimensional vector,so that the efficiency and accuracy of the algorithm are not ideal.For this reason,this paper calculates the similarity of the novels based on the common word set,and carries out the context constraint check on the common word set to achieve a more closely related word set as the main feature of the novel.The experimental results show that for some types of novels,the effect is greatly improved.
Keywords:common word set;novel similarity;context constraint
1 引言(Introduction)
随着互联网技术的发展,网络上的文本数据呈现爆炸式增长,文本处理算法的相关研究也随之发展起来。其中,文本相似度计算成为热点研究方向,其目的在于建立一个合理的衡量模型,对文本间的相似程度进行量化。小说作为一种文学作品,与普通文本有较大区别,小说的构成要素要比普通文本复杂很多,比如时间、地点、人物、社会、环境等等,并且小说的上下段落、上下情节之间联系十分紧密。所以,必须要从新的角度建立小说相似度的衡量模型。
目前经典的文本相似度计算算法大部分基于向量空间模型(VSM)[1]。向量空间模型将文本视作由独立的、互不关联的词构成的一个向量,并且把词语在文中出现的频数作为文本的主要特征。通过将文本映射成一个向量模型,文本相似度计算也就转换成向量之间的相似度计算。小说作为一种特殊的文本类型,词语之间的关联比普通的文本更加紧密,如果依然将小说表示成向量空间模型,将失去很多重要的特征信息,尤其是词条间的上下文信息,词语之间的关联隐含着情节信息,对文义的理解起着至关重要的作用[2]。不仅如此,对于长篇小说而言,向量空间模型将产生一个维数十分巨大的向量,严重影响算法的效率,问题将变得不可行。
本文主要介绍了一种基于公共词集对长篇小说相似度研究的算法[3]。对小说进行预处理后,建立Map映射结构,在构建公共词集的过程中,加入上下文约束,最终得到满足上下文约束的若干词集簇,并以此作为衡量相似度的依据,建立相似度衡量算法,并通过实验验证算法可行。
2 相关工作(Related work)
2.1 向量空间模型
文本的内容特征常常用它所含有的基本语言单位,如字、词或者短语等来表示,这些基本的语言单位被统称为文本的项[4]。向量空间模型(Vector Space Model,VSM)将文本D转化为由词项w构成的m维向量,即:
文本中的每个项相互独立,可以通过计算向量之间的距离来衡量文本之间的相似度。每个词项往往都赋予一个权重(Term Weight),表示该词项在文本中的重要程度。TF-IDF(Term Frequency-Inverse Document Frequency)是使用最广泛的一种权重计算方法,公式如下:
其中,表示词项的出现频数,表示文档集中文本数量,表示词项在文档集中包含该词项的文本数量。
在文本中的出现频率反映该词项的重要程度,词项在多个文本中的出现情况反映了词项的文义甄别能力,TF-IDF综合考虑了以上两点,每一个词项的权重由TF权值和IDF权值两个部分组成。通过计算向量之间的余弦角,可以得到两个文本向量之间的相似程度,定义如下:
2.2 公共词集
从小说的词法方面研究其文本特征,如果不考虑词项之间的先后顺序,可以比较小说词域之间的相交程度来衡量相似度。将小说的词集提取出来,两篇小说的公共词集可以反映小说在用词造句方面的相似性[5]。相对于两篇小说的平均文本长度而言,如果公共词集包含的词项数越多,小说的相似程度越高,两篇小说的用词方式更为接近;反之,若公共词集包含的词项数越少,相似程度越低。在对小说进行文本預处理操作后,分别统计词项的频数和位置信息,可以得到小说N1和N2的公共词集CWS,公共词集中的元素由词项和词项在小说中的频数构成。可以用采取如下计算公式计算相似度:
摘 要:传统的文本相似度计算基于向量空间模型(VSM),文本映射成独立的、互不关联的词构成的向量。由于长篇小说具有比普通文本更为复杂的构成元素,以及更加紧密的上下文联系,传统算法忽略词项的上下文联系,并且产生高维向量,因此算法的效率和精度不理想。为此,本文基于公共词集对长篇小说进行相似度计算,并对公共词集进行上下文约束检查,得到关联比较紧密的词集,作为小说的主要特征。实验结果表明,对于某些小说类型,效果有很大的提升。
关键词:公共词集;小说相似度;上下文约束
中图分类号:TP391.1 文献标识码:A
Abstract:Traditional text similarity computation is based on Vector Space Model (VSM),where the text is mapped into independent and unrelated words.Because novels have more complex elements and much closer context than ordinary texts,the traditional algorithm ignores the context of the words and produces the high dimensional vector,so that the efficiency and accuracy of the algorithm are not ideal.For this reason,this paper calculates the similarity of the novels based on the common word set,and carries out the context constraint check on the common word set to achieve a more closely related word set as the main feature of the novel.The experimental results show that for some types of novels,the effect is greatly improved.
Keywords:common word set;novel similarity;context constraint
1 引言(Introduction)
随着互联网技术的发展,网络上的文本数据呈现爆炸式增长,文本处理算法的相关研究也随之发展起来。其中,文本相似度计算成为热点研究方向,其目的在于建立一个合理的衡量模型,对文本间的相似程度进行量化。小说作为一种文学作品,与普通文本有较大区别,小说的构成要素要比普通文本复杂很多,比如时间、地点、人物、社会、环境等等,并且小说的上下段落、上下情节之间联系十分紧密。所以,必须要从新的角度建立小说相似度的衡量模型。
目前经典的文本相似度计算算法大部分基于向量空间模型(VSM)[1]。向量空间模型将文本视作由独立的、互不关联的词构成的一个向量,并且把词语在文中出现的频数作为文本的主要特征。通过将文本映射成一个向量模型,文本相似度计算也就转换成向量之间的相似度计算。小说作为一种特殊的文本类型,词语之间的关联比普通的文本更加紧密,如果依然将小说表示成向量空间模型,将失去很多重要的特征信息,尤其是词条间的上下文信息,词语之间的关联隐含着情节信息,对文义的理解起着至关重要的作用[2]。不仅如此,对于长篇小说而言,向量空间模型将产生一个维数十分巨大的向量,严重影响算法的效率,问题将变得不可行。
本文主要介绍了一种基于公共词集对长篇小说相似度研究的算法[3]。对小说进行预处理后,建立Map映射结构,在构建公共词集的过程中,加入上下文约束,最终得到满足上下文约束的若干词集簇,并以此作为衡量相似度的依据,建立相似度衡量算法,并通过实验验证算法可行。
2 相关工作(Related work)
2.1 向量空间模型
文本的内容特征常常用它所含有的基本语言单位,如字、词或者短语等来表示,这些基本的语言单位被统称为文本的项[4]。向量空间模型(Vector Space Model,VSM)将文本D转化为由词项w构成的m维向量,即:
文本中的每个项相互独立,可以通过计算向量之间的距离来衡量文本之间的相似度。每个词项往往都赋予一个权重(Term Weight),表示该词项在文本中的重要程度。TF-IDF(Term Frequency-Inverse Document Frequency)是使用最广泛的一种权重计算方法,公式如下:
其中,表示词项的出现频数,表示文档集中文本数量,表示词项在文档集中包含该词项的文本数量。
在文本中的出现频率反映该词项的重要程度,词项在多个文本中的出现情况反映了词项的文义甄别能力,TF-IDF综合考虑了以上两点,每一个词项的权重由TF权值和IDF权值两个部分组成。通过计算向量之间的余弦角,可以得到两个文本向量之间的相似程度,定义如下:
2.2 公共词集
从小说的词法方面研究其文本特征,如果不考虑词项之间的先后顺序,可以比较小说词域之间的相交程度来衡量相似度。将小说的词集提取出来,两篇小说的公共词集可以反映小说在用词造句方面的相似性[5]。相对于两篇小说的平均文本长度而言,如果公共词集包含的词项数越多,小说的相似程度越高,两篇小说的用词方式更为接近;反之,若公共词集包含的词项数越少,相似程度越低。在对小说进行文本預处理操作后,分别统计词项的频数和位置信息,可以得到小说N1和N2的公共词集CWS,公共词集中的元素由词项和词项在小说中的频数构成。可以用采取如下计算公式计算相似度:
