基于自适应遗传算法的多维数据关联规则挖掘
闫磊 何志方 赵文娜 李远 姚非

摘 要:针对传统的关联规则在电力数据中心大数据环境下数据挖掘过程中效率低的问题,提出了基于自适应遗传算法的多维数据关联规则挖掘算法,对传统算法中的交叉算子和变异算子进行自适应优化,为了避免无用规则产生,融入注意力以提高关联规则的可靠性,更好地用于关联规则的挖掘。最后通过对比实验验证了本文算法能够提高运算的收敛速度和结果的鲁棒性。
关键词:数据挖掘;关联规则;自适应遗传算法;注意力
1 概述
近年来随着电网的大规模建设,相应的自动化机房系统及数据网规模日益庞大,系统节点、设备、厂商日渐增多。各种设备与应用间的交互与连接形成了纵横交错的复杂关系网。在这种设备与应用数量急剧增加,关系愈加复杂的情况下,为保证数据中心系统的平稳运行和实时监控,需要对收集到的多维度运行数据信息进行有效地关联分析与挖掘,让所有的数据得到充分的分析利用,挖掘其潜在价值[1-3]。
因此本文提出一种将自适应遗传算法与关联规则相结合的方式,选择遗传算法[4]用于电力数据中心数据的挖掘,并根据其具体需求对其进行自适应改进。与此同时,通过引入注意度参数来增加算法的可信度。
2 自适应遗传算法
传统的遗传算法存在搜索能力较弱,容易陷入局部最优无法达到应有的效果。因此本文提出了一种新的自适应遗传算法,针对交叉概率Pc和变异概率Pm进行优化,使其在运算过程中根据实际情况的适应度变化而作出相应改变。传统算法中Pc过大不利于优良个体的保护,Pc太小会使运算过程繁琐,从而使算法的效率过低。Pm过小,会导致新的变异个体不易产生,同时也需要控制Pm不能过大[5]。基于此上述两种概率的计算方式如公式(1)(2)所示。其中favg表示平均适应度值,f′表示交叉个体中适应度较大的值,f表示变异个体适应度的值;Pc1和Pc2为交叉概率,Pm1和Pm2为变异概率。
基于自适应遗传算法的关联规则挖掘步骤如下,首先初始化相关参数,生成初始种群,计算每个后代个体的适应度,进行复制繁衍下一代个体,接着对后代个体使用公式3、4完成自适应遗传变异步骤,然后分别计算每条规则的支持度、置信度和注意力的相关值,最后选择满足条件的规则来生成提取最终的强关联规则。
3 实验结果与分析
3.1 实验数据
实验数据来源于某电力数据中心运维数据。数据集采集于2019年1月1日至2019年12月31日的数据中心的三份运维数据,由告警、故障和综合网络数据三部分构成。告警数据是由全业务系统中系统监测单元产生的告警日志,用于监测系统的运行状态;故障数据由人工完成,显示了系统故障的起因及解决方案;综合网络数据由进程调度、CPU占用率、设备信息、流量统计、数据库操作等系统数据构成。
3.2 自适应交叉概率和变异概率结果分析
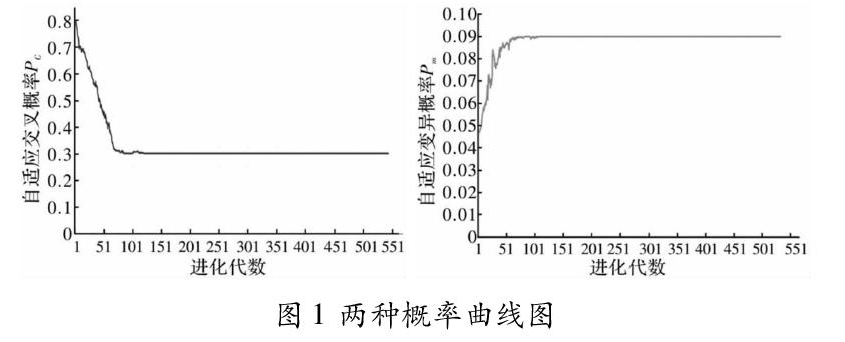
图1展示了两种概率随迭代次数增加的变化曲线,从图中可以看出,随着进化迭代代数的不断增加,交叉概率Pc逐渐变小,然后稳定于0.3左右波动;变异概率Pm则相反,随迭代次数增加不断变大,最终稳定于0.09左右。在种群繁衍初期,受交叉算子的影响,能快速产生后代的新个体,当进化繁衍到后期时,交叉算子稳定于一较小值,保证优质后代不会发生变异,同时较大的变异算子又能够在种群陷入局部最优解时,变异产生新的后代,保证种群的继续迭代,全局搜索能力较强。
3.3 自适应遗传算法实验结果与对比分析
通过本文算法对告警、故障和综合网络数据进行关联规则分析,当支持度设置为50时,共分析得到8项强关联规则,同时在告警数据和综合网络数据中进行分析,最终得到10项关联规则,证明了本文算法的有效性。
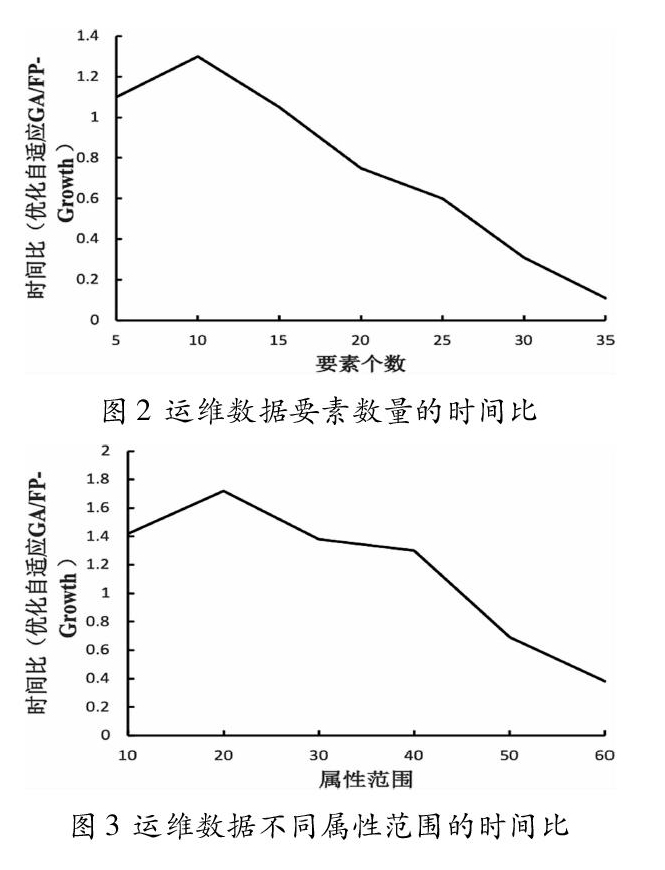
算法效率的高低取决于数据集中不同属性的范围、数据量的大小和数据要素的数量,针对以上三种变量,使用FP-Growth算法[6]与本文提出的自适应遗传算法进行对比实验,通过两者的時间比来体现提出算法的性能,结果如图2,3,4所示。
根据实验结果可知,如果运维数据要素个数越多,每个运维数据不同属性的取值范围越大,则自适应遗传算法比FP-Growth效果越好。虽然当运维数据数据记录量增大时,本文算法的效率比FP-Growth算法低,但两者差距较小。因此本文提出的自适应遗传算法适用于数据类型复杂的数据中心运维数据的关联规则挖掘。
4 结语
本文针对数据中心运维数据关联规则挖掘效率低、潜在价值缺乏挖掘的问题,提出了关联规则在电网数据中心的应用,将自适应遗传算法融入到关联规则中,在提取关联规则前引入了注意力来提高结果的可靠性。通过实验表明改进后的方法在算法收敛性、挖掘效率上,相比传统方法有了较大的提升,适用于类型复杂的数据集中发现关联规则。
参考文献:
[1]丁煜.数据中心运维数据关联规则知识库的构建[D].2016.
[2]彭刚,唐松平,曾力,等.基于数据挖掘的电网故障关联规则的研究[J].计算机与数字工程,2019,47(9):2369-2374.
[3]蔡泽祥,马国龙,孙宇嫣,等.基于数据挖掘的电力设备运维与决策分析方法[J].华南理工大学学报(自然科学版),2019,47(6).
[4]张军,刘文杰.关联规则中基于模糊遗传算法的研究与改进挖掘技术[J].现代电子技术,2017,40(14):23-25.
[5]任子武,伞冶.自适应遗传算法的改进及在系统辨识中应用研究[J].系统仿真学报,2006,18(1):41-43.
[6]Sun Hong,Zhang Huaxuan,Chen Shiping,et al.The study of improved FP-growth algorithm in MapReduce [C].Shang-hai:International Workshop on Cloud Computing and Infor-mation Security(CCIS),2013.
作者简介:闫磊(1985—),男,高工/副处长,研究方向:调度自动化。
