深度学习视角下的个性化学习资源推荐方法
李浩君 张征 郭海东 王旦
摘要:随着“互联网+”教育的快速发展,在线学习资源数据规模急剧扩张,学习者从海量的学习资源中选择合适资源的难度随之增大。如何帮助学习者获取合适的学习资源开展个性化学习,已成为智能学习领域重要的研究课题。实现个性化学习资源推荐的关键在于对在线学习平台数据应用价值的探索与挖掘,全面考虑学习者与学习资源之间的关联性。随着人工智能的不断发展,简单的机器学习已经难以满足个性化学习资源推荐服务,基于深度神经网络设计的个性化学习资源推荐方法,通过基于MIFS的特征选择模型和学习者-学习资源二部图关联模型,在有效衡量学习者对学习资源的不同关注程度,以及深度挖掘学习者的个性化偏好基础上,为学习者推荐合适的学习资源。该方法在不同学习时间和学习者的实验条件下,取得了较好的推荐效果,并且在分类与回归性能评价指标上优于传统机器学习算法,说明其能够较好地提供教育大数据环境下的个性化学习资源推荐服务,提升学习者的在线学习体验。
关键词:深度学习;神经网络;学习资源;个性化;推荐方法
中图分类号:G434 ? 文献标识码:A ? ?文章编号:1009-5195(2019)04-0094-10 ?doi10.3969/j.issn.1009-5195.2019.04.011
移动互联网和云计算技术的飞速发展,使在线学习成为一种普遍且重要的学习方式。但其在带来海量学习资源的同时,也给学习者带来了认知过载、学习资源零乱等困惑(韩营等,2017)。如何帮助学习者获取合适的学习资源并开展个性化学习,已成为智能学习领域重要的研究课题。为使个性化学习资源推荐效果更加精准,深入了解学习者的个人偏好、学习风格和认知能力等,并与多样化的学习资源形成有效关联,建立模型并通过相关推荐技术向学习者提供符合自身需求的学习资源,是解决这一问题的主要思路。目前个性化推荐技术已在电影、音乐、电视、新闻等领域得到广泛应用(Zhao et al.,2013;Wei et al.,2016;Mao et al.,2016;Wang et al.,2016),其中机器学习已成为个性化推荐服务性能提升的重要技术支撑。
一、个性化学习资源推荐方法及技术
学习资源是指用来支持信息化教学活动开展的数字化资源,包括数字化教育教学案例、电子文档、音视频素材以及多媒体软件等。随着互联网与大数据技术的发展,学习资源获取更加多样化,不同学习者可以根据自己的偏好选择合适的学习资源来开展学习,实现个性化学习目标,许多技术正被广泛应用于在线学习。
1.基于推荐算法的个性化学习资源推荐
常用推荐算法包括基于资源内容的推荐、协同过滤推荐以及混合推荐等。基于内容的推荐算法是通过识别和提取资源内容特征,构建学习者特征模型和资源特征模型,将二者匹配度较高的学习资源推荐给学习者(Yao et al.,2015;Pandey et al.,2016)。协同过滤算法通过对学习者偏好的挖掘,基于不同的偏好对学习者进行分组划分,并推荐相似的学习资源给各组(Zapata et al.,2015)。协同过滤算法能有效降低模型构建复杂性,但存在矩阵稀疏和冷启动等问题(何洁月等,2016,Polatidis et al.,2016)。混合推荐算法将资源内容特征与学习者特征联合考虑,根据学习者的学习风格和习惯为学习者推荐学习资源(Kla?nja-Mili?evi? et al.,2011),如刘忠宝等(2018)基于引入热传导和物质扩散理论提出了二部图的学习资源混合推荐方法。总的来说,资源推荐模型构建的合理性和科学性一直是传统推荐算法应用于个性化学习资源推荐领域的难题。
2.基于机器学习的个性化学习资源推荐
随着机器学习在计算机视觉、语音识别等领域的成功应用(Xue et al.,2014;Tian et al.,2016),其在教育领域应用也逐渐成为研究热点(余明华等,2017)。许多学者致力于降低学习资源推荐过程中的模型依懒性,发挥历史学习数据对资源推荐过程的服务作用,开展机器学习应用于个性化学习资源推荐领域的研究工作。Vesin等(2011)通过测试学习者状态与挖掘服务器日志,识别学习者的学习风格与习惯,开展个性化资源推荐研究;Aher等(2013)利用半监督机器学习以及历史数据,较为准确地为学习者推荐了课程;Batouche等(2014)提出一种基于无监督机器学习的教学资源推荐方法,采用改进的人工神经网络获得了较为合理的推荐结果;赵蔚等(2015)提出了基于知识推荐技术与本体技术相融合的个性化资源推荐策略;文孟飞等(2016)采用了一种基于支持向量机与深度学习相结合方法来实现网络教学视频推送服务的方法,提升教学视频资源的利用率和获取率;Tarus 等(2017)构建了一种基于本体与序列模式挖掘相结合的混合知识推荐系统,为在线学习者推荐个性化资源;Zhou等(2018)提出了基于LSTM神经网络的在线学习路径推荐策略。
纵观以往的研究,将机器学习领域中的深度学习算法运用到在线资源推荐的研究较少,并且对在线学习隐性数据的挖掘较为粗糙,推荐效果提升不明显。虽然神经网络具有很强的非线性拟合能力,可映射任意复杂的非线性关系,但目前机器学习算法应用于推荐问题针对性不强,缺乏对神经网络训练要素的深入研究。而且推荐效果驗证时缺乏对分类与回归问题的综合分析,容易忽略一些重要的性能指标导致推荐效果不理想。
本文尝试使用机器学习与历史数据来优化资源推荐模型,提出了基于深度神经网络的个性化学习资源推荐方法,在设计基于互信息特征选择模型(Mutual Information Feature Selection,MIFS)的深度神经网络输入优化策略的基础上,建立了学习者-资源二部图关联模型下的输出直观化描述,利用深度神经网络训练资源推荐模型,实现个性化学习资源推荐。
二、問题描述与方法框架
1.问题描述
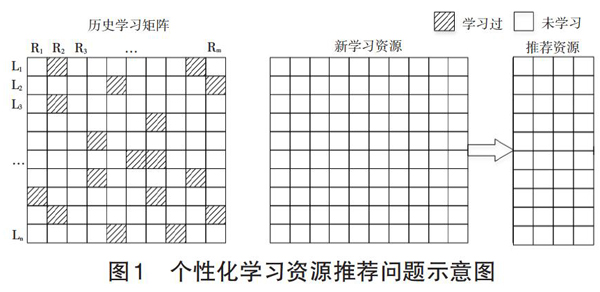
实现个性化学习资源推荐,实质上是对学习者与学习资源二者之间关系的解析。要使在线学习平台提供个性化资源推荐服务,关键在于采集学习平台原始数据,并对数据进行有效地分析、挖掘等处理,最终向学习者推荐合适的学习资源。个性化学习资源推荐模型可以利用学习者学习资源的历史集合信息。该信息可用图1左侧的m×n矩阵表示,其中R代表学习资源(Learning Resource),L代表学习者(Learner)。阴影部分表示学习者学习过的学习资源。白色空白部分表示未学习的资源,需要解决的问题是如何通过该历史信息矩阵实现个性化学习资源推荐,即从新学习资源中得到符合学习者需求的推荐资源,该过程如图1右侧所示。
2.个性化学习资源推荐方法框架
基于深度神经网络的个性化推荐方法可以归结为两个过程,即模型训练过程和资源推荐过程,如图2所示。模型训练过程包括学习平台数据处理、算法设计等;推荐过程由训练过程得到的推荐模型运行产生,即获取个性化学习资源的过程。本文所设计的推荐方法分为三级,其中第一、二级属于训练过程,第三级是个性化学习资源推荐过程。
在第一级中,为了使深度神经网络能够工作,须获取它的输入输出。对于输入,本文设计了基于互信息特征选择模型MIFS,以此来描述和处理历史学习数据;对于输出,构建了学习者-资源二部图关联模型,明确了学习资源是否推荐的条件。第二级中,通过第一级的输入输出,建立深度神经网络学习模型,针对个性化推荐问题,设计了深度神经网络优化策略,通过复杂的训练过程可得到学习资源推荐模型。第三级中,将测试数据输入训练完毕的推荐模型,向学习者推荐符合学习需求的个性化学习资源。
三、模型设计
1.基于互信息特征选择模型(MIFS)
不同学习平台上学习者和学习资源的属性具有多元化特征。影响学习者选择学习资源的因素有很多,涉及性别、专业、学习目标、内容偏好、学习风格、认知水平、学习动机等(包昊罡等,2018)。同时,学习资源可能存在资源风格、媒介类型、交互方式、难易水平等内在属性(文孟飞等,2016)。因此,需要在众多特征中探寻学习者与资源之间的关联并建立特征选择模型,以此完成推荐方法的输入过程。
在线学习数据中包含学习者学习行为记录,也存在很多隐式数据,学习资源特征也能在数据中获取。实际数据处理过程中存在无关特征或者冗余特征,例如学习者的学号或者班级号可能是无关特征,在公开的一些大型开放数据集中可能还记录了学习者的家乡、父母职业、家庭住址等等,因此需要进行筛选处理或者特征选择,将无关特征或者相似冗余特征去除,使得推荐模型更加准确与高效。机器学习实践任务中需要选择与类别相关性强的特征或者数据信息,可以运用特征选择方法定义合适的子集评价函数来实现。
我们通常可以直接利用训练数据的性能来评价特征,这与后续算法无关,且速度较快。互信息是指两个随机属性或者特征之间的关联强弱。判断单个特征与目标类别的相关性,可以减少特征维度的冗余程度。本文选用基于互信息特征选择(MIFS)方法,图3为基于MIFS的特征选择模型示例。
基于MIFS的特征选择方法中,信息度量评价函数至关重要。虽然函数形式多样,但目的都是选择与类别相关性最大的特征子集(姚旭等,2012)。泛化的信息度量评价函数可表示为:
(1)
其中S为已选择的特征,f为候选特征,C为类别,函数是C、f、S之间的信息量,即已选特征添加候选特征后与类别之间的相关程度,α是调节系数,用于调节f加入时带来信息量的程度,δ是惩罚因子,用于f给S带来的冗余程度。因此最简单直观的信息度量评价函数可表示为:
(2)
若直接将所有候选特征用于计算评价函数,则会给预处理过程带来过多冗余。为避免这种情况,在考虑特征之间的关联性基础上,通过特征f与已选单个特征s的相关性对f惩罚,β是调节系数,此时最终评价函数可表示为:
(3)
已选择的特征表示确定会影响学习者选择资源的其他特征,比如资源的知识内容、学习时长等,此部分特征可以通过对已有研究的梳理来确定或者通过调查方式来确定。候选特征代表暂时还不能确定是否影响学习者学习某资源的其他特征,比如学习者的年龄、专业背景、性别等。而类别是对已选特征的提取,用于衡量已选特征与候选特征的信息量相关性。最终评价函数的构建是为了判断候选特征对评价结果的影响,添加相关度较大的候选特征,进而过滤掉一些冗余特征,以有效缓解后期利用数据进行深度学习训练的工作量。
2.学习者-资源的二部图关联模型
了解学习者对一个或者若干个学习资源的学习状况,对理解学习者的行为和兴趣具有很大的帮助。传统的协同过滤推荐算法主要依赖于学习者对某些学习资源是否学习过以及学习者自身偏好,未考虑不同学习者对资源的学习次数。学习者对同一资源或者同一类资源的学习次数代表了不同的偏好程度,因此资源的学习次数是一个很好的反映学习者偏好程度的衡量指标。
本文提出学习者-资源的二部图关联模型,定义学习者集合为:L={l1,l2,l3,…,lm},资源集合为:R={r1,r2,r3,…,rn},由此可得到一个由学习者集合和资源集合构成的二值关系矩阵Xm×n,行向量代表学习者,列向量则代表学习者关于学习资源的学习行为。若Xm×n=1,则表示学习者学习过该资源;若Xm×n=0,则没有学习过。
(4)
学习者对学习资源的学习频率可反映不同的偏好程度,资源学习的平均频率可定义为:
四、实验研究
1.实验方案
为了验证基于深度神经网络的个性化学习资源推荐方法推荐的个性化学习资源与学习者需求的符合程度,研究者开展了一系列实验。实验数据不仅包括学习资源数据,还包括学习者开展学习的历史数据。在现有的公开数据集中,如edX、World UC等,提供了数十个属性,包括课程数据、学习者信息和学习者行为数据等。参考Zhou等(2018)的实验设计方案,本文从浙江省某高校网络平台数据中集中提取了部分在线学习数据信息,结合学习者和学习资源的实际情况,按照相应规则补全了部分数据形成本文实验数据集。利用基于MIFS的特征选择方法处理后的模型,可获取学习者-资源特征,即在整个方法流程中需要输入的特征子集。在实际任务中很多机器学习存在表离散化特征,如表1所示。本文对特征采用独热编码方式,例如一条学习记录中显示学习资源属于计算机类,难度为较易,媒介类型是视频格式,学习者是上午九点进行学习的,则该资源样本通过独热编码可记作:[10000000]、[01000]、[10000]、[1000]。
学习者对学习资源的使用次数既反映了学习者的兴趣程度,也提供了资源是否推荐的依据。为了直观地显示学习者与学习资源的学习频次,更好地论证本文方法的有效性和可读性,研究者随机选择了20位学习者对20个学习资源的使用情况作为示例,如表2所示。
2.评价指标
一方面,本文解决的问题是判断学习资源是否推荐给学习者,可分为倾向推荐和倾向不推荐两种情况,因此可看作一个分类问题;另一方面,学习者对学习资源的使用频次很大程度上反映了学习者的兴趣,因此也可看作为一个回归问题。研究结合常用的推荐系统评价指标,将查准率、召回率和F1-score值作为分类性能评价指标,将均方误差、均方根误差、平均绝对误差作为回归性能评价指标。
(1)分类评价指标
TP(True Positive),正确预测出的正样本个数,代表预测学习者会使用或者多次使用的资源数量;FP(False Positive),错误预测出的正样本个数,代表预测学习会者会使用或者多次使用实际却几乎没被使用的资源数量;TN(True Negative):正确预测出的负样本个数,代表预测学习者几乎不使用,实际确实如此的学习资源数量;FN(False Negative),错误预测出的负样本个数,代表预测学习者几乎不使用却被使用了的资源数量。
根据上述表述,查准率(Precision,P)、召回率(Recall, R)和F1-score值(F)通常是越高越好,表明推荐的学习资源被学习者学习的概率较大,即推荐结果较符合学习者的需求。它们的数学计算公式如公式(9):
(9)
(2)回归评价指标
为了探索学习资源被学习者使用的实际次数与预测次数的误差,引入以下指标:
平均绝对误差(Mean Absolute Error,MAE),由于预测误差有正负之分,为了防止正负抵消,故对误差的绝对值进行综合并取平均数。均方误差(Mean Squared Error,MSE),是预测误差平方和的均值,目的是解决正负误差不能相加的问题。均方根误差(Roof Mean Squared Error,RMSE),是均方误差的平方根,可以代表预测值的离散程度。误差越小,说明预测的学习次数与实际次数越接近,即说明推荐结果较好。它们的计算公式如下:
(10)
其中n表示样本数,Xi表示第i个实际值,YI表示第i个预测值。
3.实验结果与讨论
为了使实验结果更加精确,研究采用十折交叉验证。由于学习者在实际进行资源学习时具有时间上的连续性,因此研究对使用时间前段的数据进行十字交叉训练,再将训练完毕的模型应用于时间后段的数据进行验证,以便更加客观地说明推荐的学习资源的使用情况,并通过不同数量的学习者与学习资源构成了四个大小递增的样本(如表3所示),进一步进行验证。
研究选择Windows Server 2012 R2操作系统、64GB RAM、MatlabR2017b语言环境进行实验。表4是各对比算法的性能数据,其中分类对比算法采用决策树算法(Fine Decision Tree,DT)、支持向量机算法(Linear SVM,SVM)和k最近邻算法(Fine KNN,KNN);回归方面则采用回归树算法(Fine Regression Tree,RT)、支持向量机算法(Linear SVM,SVM)和線性回归算法(Linear Regression,LR);DNN(Deep Neural Network)代表本文方法设计的深度神经网络算法。
分类结果中,随着数据集样本大小的变化,各算法查准率(P)和召回率(R)也随之波动,但都处于一个较高的值,说明本文针对个性化学习资源推荐问题所构建的模型,及采用机器学习算法求解是可行且有效的。分类评价指标中P值和R值较高,说明推荐模型即推荐给学习者的资源较为符合学习者的需求。再从式(9)的分析过程可以看出,P与R往往不能共同处于较好的值,如样本一中SVM算法的R值较高,但是P值较小,此时不能片面地从一个指标判断其性能优劣,因此将F1-score值(F)作为推荐性能的综合评价指标,F值越高代表推荐效果越好。
如图6所示,本文设计的深度神经网络(DNN)在F值上优于其他传统机器学习算法并且值较高,说明本文提出的方法在解决学习资源推荐实际问题上是具有针对性且高效的。结合表3,可以看出不同样本中随着学习者数量或者学习时间的增多,分类指标中的三个指标都会随之增加,说明学习记录增多,有利于学习者与学习资源的关联分析,提高推荐性能。
回归分析能够较好地预测学习者对学习资源的关注程度或者兴趣大小。从表4中可以看出,回归评价指标中的误差值都较小,即预测的学习频次与实际的学习频次较为接近,说明本文方法的建模也适用于回归分析。
如图7所示,随着样本大小的变化,以及学习者对资源进行学习积累的记录增多,对其学习频次的预测越有利。在预测结果与实际结果的误差上,DNN算法是最小的,并且均方根误差值(RMSE)下降较多,说明离散程度小,即预测学习者的使用次数值与实际次数偏差小,在不同样本下经过改进的深度神经网络在预测学习者学习资源频次上也具有很好的适应,表现出比其他算法更好的性能。
基于深度神经网络的个性化学习资源推荐方法,不仅考虑了学习者是否会对资源进行学习,也预判了学习者对学习资源的兴趣大小或者关注程度。通过不同推荐性能指标对推荐方法进行验证,本文所提出的推荐方法在资源推荐方面具有明显的优势,能够一定程度上解决新对象或冷门对象的推荐问题。各个评价指标的验证说明,基于MIFS的特征选择模型和学习者-资源二部图关联模型与深度神经网络适配性强,显现出很好的推荐性能,能够适用于大小规模不等的在线学习数据。此外,根据时间前段的历史学习数据为学习者在时间后段的学习推荐个性化学习资源,能够很好地满足学习者的需求。
[14]Polatidis, N., & Georgiadis, C.(2016). A Multi-level Collaborative Filtering Method that Improves Recommendations[J]. Expert Systems with Applications, 48:100-110.
[15]Tarus, J., Niu, Z., & Mustafa, G. (2017). Knowledge-Based Recommendation: A Review of Ontology-Based Recommender Systems for E-learning[J]. Artificial Intelligence Review, 1-28.
[16]Tian, L., Fan, C., & Ming, Y. (2016). Multiple Scales Combined Principle Component Analysis Deep Learning Network for Face Recognition[J]. Journal of Electronic Imaging, 25(2):023025.
[17]Vesin, B., & Budimac, Z. (2011). E-learning Personalization Based on Hybrid Recommendation Strategy and Learning Style Identification[J]. Computers & Education, 56(3):885-899.
[18]Wang, Y., & Shang, W. (2016). Personalized News Recommendation based on ConsumersClick Behavior[C]// International Conference on Fuzzy Systems and Knowledge Discovery. IEEE: 634-638.
[19]Wei, S., Zheng, X., & Chen, D. et al. (2016). A Hybrid Approach for Movie Recommendation Via Tags and Ratings[J]. Electronic Commerce Research & Applications, 18(C):83-94.
[20]Xue, S., Jiang, H., & Dai, L. (2014). Speaker Adaptation of Hybrid NN/HMM Model for Speech Recognition Based on Singular Value Decomposition[A]. International Symposium on Chinese Spoken Language Processing[C]. IEEE: 175-185.
[21]Yao, L., Sheng, Q., & Ngu, A. et al. (2015). Unified Collaborative and Content-Based Web Service Recommendation[J]. IEEE Transactions on Services Computing, 8(3):453-466.
[22]Zapata, A., Menéndez, V., & Prieto, M. et al. (2015). Evaluation and Selection of Group Recommendation Strategies for Collaborative Searching of Learning Objects [J]. International Journal of Human-Computer Studies, 76(C):22-39.
[23]Zhao, X., Yuan, J., & Wang, M. et al. (2013). Video Recommendation over Multiple Information Sources[J]. Multimedia Systems, 19(1):3-15.
[24]Zhou, Y., Huang, C., & Hu, Q. et al. (2018). Personalized Learning Full-Path Recommendation Model Based on LSTM Neural Networks [J]. Information Sciences, 444:135-152.
Personalized Learning Resource Recommendation from the Perspective of Deep Learning
LI Haojun, ZHANG Zheng, GUO Haidong, WANG Dan
Abstract: With the rapid development of “Internet +” education, the scale of online learning resources data has expanded rapidly, and the difficulty of learners to choose the right resources from massive learning resources has increased. How to help learners acquire appropriate learning resources and develop personalized learning has become an important research topic in the field of intelligent learning. The key to realizing personalized learning resource recommendation lies in exploring and mining the application value of online learning platform data, and taking into account the relevance between learners and learning resources. With the continuous development of artificial intelligence, simple machine learning cant meet the personalized learning resources recommendation service. The personalized learning resources recommendation method based on deep neural network, through MIFS-based feature selection model and learner-learning resources bipartite graph association model, on the basis of effectively measuring learners different attention to learning resources, as well as deep mining learners personalized preferences, appropriate learning resources can be recommended for learners. This method achieves good recommendation effect in different learning periods and under different learners experimental conditions, and it is superior to traditional machine learning algorithm in classification and regression performance evaluation index. It shows that this method can provide personalized learning resource recommendation service in the big data environment of education and improve learners online learning experience.
Keywords: Deep Learning; Neural Network; Learning Resources; Personalization; Recommendation Methods
