面向大规模在线学习的社会化推荐模型与方法
包昊罡 李艳燕 郑娅峰

摘要:大规模在线学习中,学习者面对数量众多、种类繁杂的学习资源容易产生“信息迷航”“信息过载”等问题。因此,为学习者提供个性化的学习推荐服务是大规模在线学习的重要任务。但目前的推荐系统大多只考虑了学习者与学习资源特征,对其内在社会联系考虑不足,推荐效果有较大的提升空间。许多研究表明,引入社会化因素,对于提升推荐系统效果有显著的帮助。社会化推荐系统需要根据应用情境,深入地理解用户、推荐对象以及影响他们之间相似关系和社会关系的要素。大规模在线学习中的社会化推荐系统要素模型包括学习者特征、推荐对象特征、社会关系和应用情境四个方面。相较于传统的推荐方法,在这一要素模型基础上设计的基于兴趣主题的社会化推荐方法更好地结合了大规模在线教育场景,以及学习者和资源服务要素,并进一步研究了用户间的内在社会关联,挖掘了用户、学习资源间的隐性联系。实验结果也说明,该推荐方法在教育场景中可以实现更好的推荐效果。
关键词:大规模在线学习;社会化推荐;推荐系统;社会网络;要素模型
一、引言
大规模在线课程(MOOCs)的出现,使得在线教育环境发生了巨大变化。MOOCs以其注册门槛低、资源开放、异步呈现和无约束使用等特点吸引了来自世界各地的学习者(杨玉芹等,2014)。大量的资源和众多的学习者使得MOOCs信息量急剧增加,从而导致“信息过载”和“信息迷航”现象突出,学习者难以找到合适的学习资源、学习伙伴及领域专家。因此需要学习推荐系统对其进行个性化的推荐服务。
同时,MOOCs把学习的控制权交给了学生,给了学习者充分发挥其主观能动性的空间,这带来学习方式与交互方式的重大改变(王志军等,2014)。社会化学习成为MOOCs学习者的重要学习方式。在MOOCs中,学习者的社交活动,不仅产生了大量的社交关系,形成了相互联系的群体;而且这些社交信息中也包含着学习者丰富的个人信息,为进一步深入理解学习者的认知特征、学习风格和个人兴趣提供了依据。通过对学习者的社交情境进行分析,可以更加深入地理解学习者,进而构建符合大规模在线课程特征的社会化推荐系统,为学习者个性化的推荐服务提供支持。
面向大规模在线学习的社会化推荐服务的构建需要对大规模在线学习的社会化特点进行深入理解,并结合其特点进行系统设计。为此,本文通过对现有学习推荐系统进行梳理,结合大规模在线学习的特点,从学习者特征、推荐对象特征、社会关系和应用情境四个方面提出了大规模在线学习中社会化推荐系统的要素及其模型,并在这一要素模型的基础上,设计了基于兴趣主题的社会化推荐系统框架及其相关方法。
二、相关研究
1.学习推荐系统
学习推荐系统是通过分析学习者的历史兴趣和偏好信息,从而确定学习者现在和将来可能会喜欢的项目,进而主动向学习者提供相应的资源、同伴和专家推荐服务(Jannach et al,2011)。
当前的学习推荐系统研究主要从资源推荐、同伴推荐和学习路径推荐三个方面进行了探讨。资源推荐是学习推荐系统研究最为活跃的部分。利用数据挖掘和语义本体技术对资源内容进行描述进而完成学习资源推荐是当前研究的热点。Tams等(2017)提出了一种基于本体和序列模式挖掘的混合知识推荐系统,用于学习者对e-Learning资源的推荐。Aher和Lobo(2013)采用聚类和关联规则挖掘技术,推荐学生根据其他学生从Moodle收集的特定课程中选择课程。Klasnja-Mili6evic等(2011)通过测试学习者的学习风格和挖掘他们的服务器日志,识别出不同的学习风格和学习習惯,在e-Learning系统中完成对学习者的个性化推荐。赵蔚等(2015)基于本体技术创建学习者知识资源,在教学模式的指导下实现知识资源个性化推荐,较好地满足了个性化学习需求,激发了学习者学习动机并优化了学习过程。陈敏等(2011)从用户兴趣、学习偏好和知识模型三个角度出发,一方面利用泛在学习资源的语义描述,针对结构化泛在学习资源进行综合推荐,另一方面通过对学习者行为模式的分析,完成对学习者学习伙伴的推荐。徐彬等(2015)分析了开放课程中论坛用户的身份特征和学生用户在论坛讨论过程中的行为模式,建立了学习者行为特征模型和学生在讨论过程中形成的关系网络,最终根据讨论主题分布结果为学习者推荐学习伙伴。学习路径推荐也是解决大规模在线学习个性化学习推荐的重要方法。学习路径推荐是对学习者学习的顺序进行推荐的一种策略。学习路径的推荐策略主要有三种:基于特征属性的推荐、基于学习模型的推荐和基于群体路径的推荐(赵呈领等,2015)。
2.社会化推荐系统
社会化推荐系统是指引入信任等社会化因素来设计推荐算法的推荐系统。许多研究已经表明,引入社会化因素,对于提升推荐系统的效果有显著的帮助(king et al,2010)。
基于信任的社会化推荐系统是最为常见的社会化推荐系统。其基本方法是将信任作为衡量用户间社会关系的指标,通过对用户相互信任关系的计算,得出用户间的信任值。一般拥有较高信任值的两个用户之间拥有更多的相似性。大量研究者基于用户信任关系进行了推荐系统的研究。SoRec是利用随机概率矩阵因子分解的方法建立一个与用户信任关系相关的评分矩阵来进行推荐的社会化推荐系统(Ma et al,2009)。TidalTrust是一个基于信任网络的社会化推荐系统,其定义了一个基于传播路径的信任值TidalTrust作为衡量用户间信任值的指标(Massa&Avesani,2007)。同样是基于信任网络,TrustWalker采取了随机游走(Random Walk)模型将信任关系融入推荐算法,通过社会网络询问用户直接或者间接的朋友关于目标物品和与其相似物品的评价,来达到推荐的目标(Jamali&Ester,2009)。
近年来,也有更多的研究引入更为“隐性”的基于信任的社会化影响因素,如社交圈、兴趣圈以及其他社会规则等,这些推荐系统也取得了较好的推荐效果。SET系统认为用户会与其所在的社会网络群体有相似的爱好与兴趣,因此利用用户所在社交网络对物品的整体评分以及用户的社会影响对推荐对象与用户之间的相似度进行计算(Ma et al,2009)。SocialMF系统将现实社会中的社会规则考虑进推荐系统,强调利用信任网络中信任的传递关系来对用户的潜在爱好进行判定(Jamali et al,2011)。CircleCon系统定义了一个基于圈子的社会化推荐算法,该系统的研究者认为,朋友间的信任关系是有其领域范围的,因此需要对用户所处的“圈子”进行区分(Yang et al,2012)。
社会化推荐系统在教育领域也逐渐引起研究者的关注。有研究者以建构主义学习理论为基础,利用本体论技术,结合协同过滤推荐算法,提出了社交网络环境下基于本体的学习推荐系统架构和功能(吴正洋等,2016)。也有研究采用将学习者社交网络信息与传统协同过滤相融合的方法,计算新学习者与好友之间的信任度,来预测新学习者对学习资源的评分值,以实现对新学习者的个性化学习资源推荐(丁永刚等,2016)。但这些研究仅考虑了单一或分散的社会要素,并没有对大规模在线学习中的社会化要素进行全面系统的分析。另外对用户关系考虑也比较简单,缺少对隐性用户关系的发现与挖掘。这些问题使得现有的社会化推荐系统研究难以支持教育领域的实际应用。
三、大规模在线学习中社会化推荐系统的要素模型
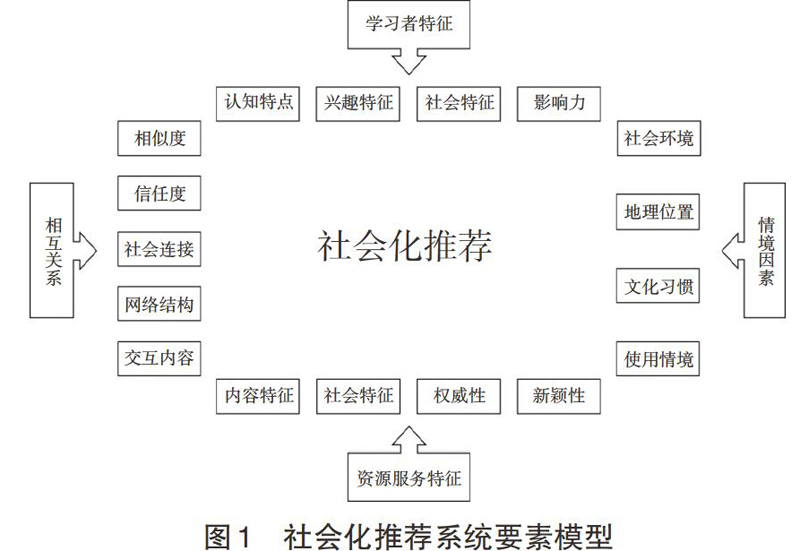
社会化推荐系统需要根据应用情境,深入理解用户、推荐对象以及影响他们之间相似关系和社会关系的要素(Arazy et al,2010)。大规模在线学习是一种特殊的推荐场景,它具有其他推荐场景不具备的一些特征。为了适应不同情境的教学需求,大规模在线学习中的推荐系统也需要向学习者推荐符合当前情境需求的资源。为此我们构建了如图1所示的大规模在线学习中社会化推荐系统的要素模型。该模型包含学习者特征、资源服务特征、用户与推荐对象(包括其他学习者和资源服务)之间的相互关系以及情境因素四个维度。
学习者特征是刻画大规模在线学习中学习者显性和隐性的个体特征的维度,包括认知特点、兴趣特征、社会特征以及影响力四个要素,以此来深入了解学习者心理和行为特征。认知特征是指学习者的初始学习能力和内在认知特点,包括知识水平、学习风格、多元智能水平、认知策略等。兴趣爱好是指学习者感兴趣的主题和内容,是进行学习内容推荐十分重要的参考因素。社会特征是指学习者在与其他学习者之间组成的社交网络中所表现出来的特征,比如他的好友数、参加的小组数量以及通过社交网络分析得到的中心度等量化指标。影响力在社会生活和决策制定等方面发挥重要作用。在大规模在线学习中具有广泛影响力的学习者,发表的观点能够促使网络中的其他人发生态度和行为上的改变,同时能够轻易引发讨论(Li et al,2013)。
与学习者特征维度类似,资源服务特征这一维度反映了资源服务的内在和外在属性,为更好地理解资源内容、分析资源间的关系提供了支持。资源服务包括学习资源、学习支持服务和学习策略等。内容特征是对资源内容的描述。对资源内容特征的描述可以通过很多方法,比如利用文本分析的方法对文本资源进行分析;利用本体、标签等语义描述的方法对资源进行更加深入地描述。资源的社会特征,主要是指资源通过其创建者和使用者而产生的所属类别。资源本身并不存在明显的社会属性,但是资源在创建、使用的过程中会和不同的学习者、学习群体产生关系,使得资源产生了丰富的社会特征。资源的权威性是指资源被他人认可的程度。在大规模在线学习中,学习者倾向于接受权威、可靠的信息(Arazy et al,2010)。资源来源的单位越权威,资源拥有者越有影响力,则该资源就可能更有权威性。当然,权威性也可能是大多数学习者认可和接受的资源。资源的新颖性是在教育场景中特殊的指标。新颖性与资源创新程度以及创建时间有关。学习者对于新颖、未知和具有創新性的推荐对象往往更具有兴趣(Golbeck,2006)。从另一个角度来说,新颖的资源也往往应该得到更多的关注与推荐,帮助新内容的传播和扩散。
相互关系是社会化推荐系统中最为重要的维度。相互关系反映了推荐系统中不同学习者之间、不同资源服务之间以及学习者与资源服务之间的社会联系的强弱。通过推荐对象与目标学习者之间的社会关系的计算和表征,可以将推荐系统中的各个参与者形成相互关联的复杂网络,从而选取合适的推荐对象。在社会化推荐系统中,相互关系包括相似度、信任度、社会连接、网络结构和交互内容5种社会关系。相似度是推荐系统中一种基础关系。很多研究指出用户与推荐对象的相似性会直接影响用户对推荐结果的接受程度(Arazy et al,2010)。不同参与者之间的相似度越高,推荐结果就越容易被接受。信任度体现了参与者之间相互信赖的程度。信任度会带来学习者之间更多的信息交换,并会影响人们对推荐对象的接受程度。信任度可以由学习者显性和隐性行为进行确定,比如学习者主动添加好友、关注以及跟随关系等。社会连接是基于社会连接理论提出的参与者之间的社会关系强弱的指标,包括强连接和弱连接。强连接包括好友关系、亲属关系等直接社会关联。弱连接是除了直接社会关联外广泛的社会关系,如共同的好友个数、共同加入的小组、社群等。社会连接理论的研究表明,无论是强连接还是弱连接都会对推荐结果造成明显的影响。强的社会连接是直接知识的重要传播渠道,会影响学习者对信息来源的态度。而弱的社会连接对于新知识、新理念的传播具有重要的意义。网络结构是指学习者和推荐对象形成的社交网络的网络特征。通过社交网络分析方法,可以得到社交网络的相关量化指标,如网络的密度、广度、凝聚程度、子群情况等。交互内容是社会关系中较新的研究主题,它是指学习者与推荐对象之间进行交互产生的文本、语言等信息。通过对学习者交互内容的分析,可以对参与者的情绪、偏好和交互强度进行更加准确和深入的分析。
情境因素是指影响推荐系统参与者的外部因素。如何对使用者的情境进行感知,并对学习者推荐符合情境的对象,是大规模在线学习推荐系统需要考虑的重要因素。学习者所处的社会环境和文化习惯等外界因素会影响其接受推荐结果的决定,比如学习者的社会背景、宗教、语言等因素会影响学习者对于学习资源的接受程度。地理因素也是一个影响推荐系统的要素。学习者可能更愿意接受来自教育发达地区的推荐结果,同时在选择伙伴时也会关注与自己相近地区的人。在现今的教学中,基于情境的学习越来越多地引起了教育者的关注。学习者不仅需要与学习主题相符合的资源,更加需要与当前情境相符合的资源,以便将理论知识快速转化到解决问题的实践中(陈敏等,2015)。
四、大规模在线学习中社会化推荐系统框架
大规模在线学习中社会化推荐系统的重要目标是采集原始学习数据,经过数据分析、数据挖掘等系统处理,最终为学习者推荐具有高可信度的学习同伴、专家及相关的最优资源。从社会化推荐系统的要素模型出发,依据实际的大规模在线学习情况,本文提出了如图2所示的包括数据收集、特征分析、社会关系网络建立和支持服务四个部分的社会化推荐系统总体框架模型,为大规模在线学习社会化推荐系统提供了一个可行的解决方案。
社会化推荐系统总体框架起始于数据收集模块。数据资源不仅包含传统关系数据库中记录的学习者学习历史信息数据,还包含学习者的社会网络关系数据、学习者社会交互数据、社交文本数据以及学习者与资源的关系数据。这些底层数据来自不同的自治系统,包含了结构化、半结构化、非结构化等形态各异的数据形式。为达到系统统一使用的目的,需要为这些不同形式的数据提供分别的数据处理方法,比如文本数据处理、关系数据处理等。
特征分析是社会化推荐系统的关键模块。以数据收集、清洗的结果为基础,通过对学习者的行为与特征数据(基本属性、认知特点等),学习者之间相互关系数据(社会关系、交互关系)以及学习资源、服务的特征(内容形式、标签)等数据的梳理,并结合关联规则挖掘、社会网络分析等数据挖掘方法,分析出学习者特征、资源服务特征、相互关系和情境因素这四类社会化推荐系统要素。例如,通过对学习者行为数据的分析,学习者的显性(性别、年龄、地域等)和隐性特征(专业程度、影响力、持久性以及专注度)可以被抽取出来。而资源特征则从资源的属性特征(名称、年份等)和资源的社会特征(类别、学习者评分等)等多个维度,利用关键词提取、关键词关联分析及关键问题表征等操作进行抽取和分析。
社会关系网络的建立是社会化推荐系统的核心模块,包括学习者之间基于可信度的社会关系网络和“学习者一资源”二元网络的建立,可以通过分析得出学习者的强社会关联(好友关系)和弱社会关联(共同好友和共同圈子)。结合学习者的强关联和弱关联,可以从社交网络的角度,计算出学习者之间的相互关系,进而形成学习者之间基于可信度的社会关系网络。结合学习者的社会关系、学习者行为特征以及资源特征,可以形成“学习者一资源”二元网络。在这个网络中,既包含传统的相似关系,也包含由社会属性产生的社会关系。学习者和学习者依據相互关系和相似程度相互关联,学习者和资源也通过评分、相似度相互关联。学习者和资源融合于一个统一的“学习者一资源”网络中。
基于“学习者一资源”二元网络,结合学习者特征与资源特征,可以形成在线学习社区中的兴趣主题,进而根据兴趣主题对“学习者一资源”的二元网络进行切分。
最终,在基于兴趣主题的“学习者一资源”社会网络基础上,结合推荐算法,可以完成最后的社会化推荐。经过对“学习者一资源”间的社会关系计算,可以完成为学习者提供学习资源、学习同伴以及专家的推荐服务。
五、社会化推荐方法
社会化推荐系统的核心工作是学习者之间基于可信度的社会关系网络和“学习者一资源”的二元网络这两个网络。这两个网络的构建包括学习者间相互关系的计算、学习者特征分析以及构建基于兴趣主题的学习者社交网络这三个主要的步骤。
1.学习者间相互关系的计算
学习者间相互关系的计算是社会化推荐过程中关键的一步。学习者与学习者之间的相互关系在社交网络中不仅呈现点赞、关注、回帖、求助等显性的社会化关系,还存在隐形关系,比如学习者对其他学习者的信任、喜爱或者尊敬等。这些关系需要通过社会化学习关系分析的方法进行挖掘并最终显性表达出来。依据社会连接理论,在本文中,分别计算了学习者间的强连接和弱连接,并通过进一步计算得到学习者间的相互关系值。
学习者之间的强连接是指学习者之间显性的好友关系。学习者通过大规模在线学习提供的功能,可以直接对感兴趣的其他学习者添加关注或好友关系。通过对这些学习者显性行为的记录,可直接获得学习者之间的强连接。
弱连接是指没有直接关联的两个学习者之间的潜在关系。比如,个人资料的交集(共同好友、共现圈子)、互访行为(访问好友空间次数、好评次数、转发行为等)、共同参与(对共同的好友或主题评论、回复)。学习者u与学习者v在类别c中的弱连接计算如下:
2.学习者特征的计算
学习者特征是表征学习者知识水平、兴趣爱好、社会行为和认知特点等显性或隐性特征的指标。在本文中,学习者特征由专业程度、专注度、持久度、影响力四个方面进行表征和计算。其中专业程度表征学习者的知识水平,专注度、持久度表征学习者的兴趣特征,影响力表征学习者的社会特征。学习者的隐性认知特点由对应的量表提前测得。
专注度表征了一个学习者在特定兴趣主题中的专一程度。一个学习者评论的物品主题类别越集中,他对该主题的兴趣和专一程度就越高。公式
持久度表示了学习者对一个类别关注的持久与深入程度。在某一领域持久度高的学习者不仅对这一领域更有权威性,同时也会更加积极地参与有关这一领域的活动,并具有更大的可能给请求者积极而及时的反馈。一个对某一类别有深入关注的学习者,在该类别中应该持续评价和关注不同的物品,并且对该类别的关注事件较早、较长。因此,一个
专业程度是用于测量学习者在特定主题专业知识能力的指标。它用于在特定主题下对学习者的专业程度评分。一个特定情境下,学习新技术的同学可能更倾向于向领域专家而非同学进行请教。在某一个特定主题中,学习者专业程度的计算基于以下两个假设:第一,学习者在该主题中评论越多,则他对这个主题的了解越多;第二,一个专家对一个物品的评论应该与该物品的总体评论相近。因此,学习者在主题c中专业程度可以用公式(5)进行计算:
影响力即社会影响力,是指学习者发表的观点能够促使网络中的其他人发生态度和行为改变的能力。影响力高的学习者较易成为社会化网络的中心人物并对他人的阅读行为和学习活动产生影响。影响力越高的成员应该拥有更多的“粉丝”(追随程度)并与主题中的其他学习者间有更为丰富的社交关系(直接或者间接)。因此,一个学习者在兴趣主题c中的影响力可以用公式(6)进行计算:
3.基于兴趣主题的学习者网络构建
兴趣主题是对学习者使用情境的刻画。在不同的兴趣主题中,学习者之间会呈现不同的社会关系和角色。例如,在文学领域,学习者更愿意与作家或者创作者进行交流,接受他们的推荐;而在医学领域,医生则具有更高的权威性。这些社会关系和角色的转变,会带来对推荐结果的影响。
基于兴趣主题的学习者可信度网络构建是将学习者的社会关系网络根据兴趣,分割成不同的兴趣主题子网络。依据学习者对不同物品进行的评分,可以按物品的特征和种类将学习者划分为不同的兴趣主题。参照Yang等在论文中提出的方法(Yanget al,2012),“学习者一资源”的社会网络s可以按照以下规则分割成以只包含单个资源类型的子网络S。具体规则如下:
学习者u和学习者v共同存在于类别c的子网络s,有且只有满足以下两个条件:第一,学习者u和学习者v本身存在社会关系;第二,学习者u和学习者v都对类别c中的物品进行过评分。
如果不满足以上两个条件,则学习者u和学习者v不存在于类别c的子网络。对于一个物品,他仅仅存在于一个子网络,而学习者可以存在于多个子网络中。即学习者可以分属多个兴趣主题。
4.推荐模式
社会化学习推荐的最终目标是在社会化学习分析及社会化推荐技术背景下,从更智能更广泛的角度理解资源与学习者的关系,提供由浅层资源向深层资源推进的按需推送,实现对学习社群、学习同伴、领域专家的有效推荐。依据不同的应用需求,不同指标可以根据其重要程度被进行赋权,通过将学习者可信度网络与学习者的评分矩阵进行整合,结合基于信任的协同过滤方法(Victor et al,2009)实现学习资源推荐、专家推荐和同伴推荐等推荐模式。
六、效果验证
为了验证本文所提出的社会化推荐方法的有效性,研究选取了真实数据集,以资源服务推荐为例,对所提出的社会化推荐方法的准确性进行了评估测试。同时,对所提出的推荐系统进行了初步实现。
1.数据收集
社会化推荐的重点是收集在线学习社区中学习者之间的社会交互数据。因此,根据研究需要,为了突出社会关系属性,本研究选取了来自豆瓣网的两个小组——“教育大发现”(https://www.douban.com/group/SocialLearnLab/)以及“实践蒙台梭利”(https://www.douban.com/group/123776/)作为数据来源。自动收集了小组成员、成员对物品的评分信息以及成员的相关社交信息。成员评论的物品选取了评论人数较为密集的“图书”作为推荐资源,成员的社交信息包括成员关注的人、关注该成员的人以及成员加入的小组名称。本研究所收集的数据如下:
“教育大发现”共有成员477名,全部成员共关注84484本图书,其中有17148本图书被该小组成员评论。全部成员共参加31057个小组,关注49194人,这些成员也被81054个其他用户所关注。
“实践蒙台梭利”共有成员524名,全部成员共关注100943本图书,其中有21371本图书被该小组成员评论。全部成员共参加47388个小组,关注56372个,这些成员也被100831个其他用户所关注。
2.实验过程
本研究分别收集了两个小组的成员基本信息(ID、性别、地区),社交信息(关注的人、被关注的人、参加的小组),与资源的交互信息(想看的图书、已看的图书、在看的图书、成员对图书的评分)以及资源信息(所有图书的标题、年份、作者、标签等信息),并对原始数据进行了清洗(去除了两个小组被注销的账号)。
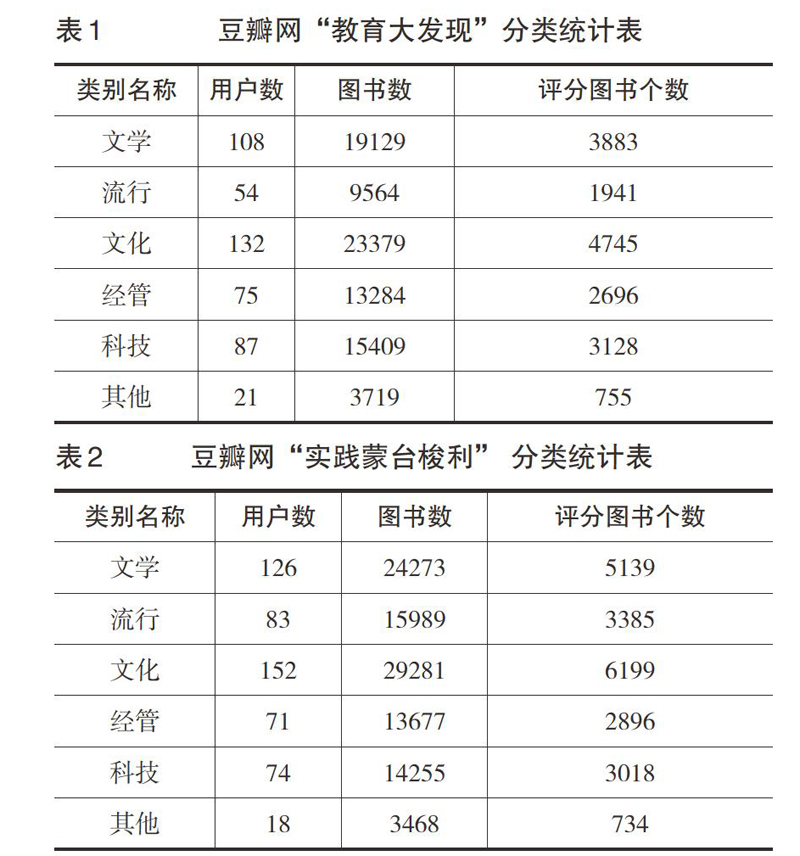
利用前文提出的兴趣主题的划分方法,对图书和用户进行了划分。依据豆瓣网的图书分类标签,可以将图书分为文学、流行、文化、经管、科技和其他6个分类,如果有图书属于不同的分类,则经研究人员讨论后,^工将其放入其中—个分类。依照图书的分类,可以将两个社区中的学习者分为6个兴趣主题。两个社区这6个主题的基本情况如表1和表2所示。
对学习者进行兴趣主题的划分后,利用学习者之间的关注、被关注和参加小组的信息,对学习者之间的可信度进行了计算。并结合学习者在不同兴趣主题下的评论对学习者的特征进行了计算。最后,依据基于信任度的推荐算法,计算了不同图书、学习者之间的推荐关系,完成了图书推荐的工作。
3.实验结果
准确率(Precision)是检索出相关文档数与检索出的文档总数的比率,衡量的是推荐系统的查准率。在推荐过程中,准确率是广泛用于信息检索和统计学分类领域的度量值,用来评价结果的质量(刘建国等,2009)。本文采用最常用的准确率平均误差MAE(Mean Absolute Error)作为研究提出的社会化推荐方法性能的评价基准。MAE越小,说明该方法的平均误差越小,推荐的结果则越准确。
研究将所提出的社会化推荐方法与传统协同过滤方法中的基于用户的推荐和基于物品的推荐方法进行了对比。采用70%的训练集和30%的测试集针对三个不同类别方法作了MAE的计算,两组数据的计算结果如表3和表4所示。
从上面两张表中我们可以清楚地看到,在图书推荐中,研究所提出的社会化推荐方法推荐准确率平均误差(MAE)小于基于用户的推荐方法和基于物品的推荐方法,显示出较好的推荐效果。
4.推荐系统的初步实现
通过对现有开源推荐系统的调研,本研究以Apache基金会的Mahout项目所提供的开源推荐算法为基础,修正和补充了部分内容,完成了整个社会化推荐系统的开发。
Apache的Mahout项目是一个开源的机器学习软件库,主要关注于推荐引擎(協同过滤)、聚类和分类等机器学习的热点问题(sean owen等,2014)。相较于其他开源的推荐系统,Mahout拥有更为灵活和开放的类库,同时提供了包括基于物品的推荐、基于用户的推荐以及基于模型的推荐等多种经典的推荐算法,便于操作。推荐系统的推荐结果如图3和图4所示。
七、总结
大规模在线学习是在线学习的未来发展趋势。为学习者提供个性化的推荐服务是大规模在线学习的重要任务。个性化学习的支持,最重要的是对学习者更加深入和充分的理解。在社交网络逐渐普及的今天,学习者越来越多地利用社交网络进行交流与学习。一个好的在线学习社区,不仅需要建立学习者可以相互协作和交流的社会空间,而且需要建立有效的社会化推荐服务,帮助学习者找到合适的伙伴、专家和资源,建立学习共同体,促进学习者完成深度学习。
本研究结合在线学习社区场景,通过对大规模在线学习中的社会化要素进行系统地分析,提出了大规模在线学习中社会化推荐系统的要素模型。在这一要素模型的基础上,设计了基于兴趣主题的社会化推荐系统框架,并结合大规模在线学习的实际情况,提出了构建基于兴趣主题“学习者一资源”二元社会网络的具体方法以及学习资源、学习同伴以及领域专家的推荐方法。相较于传统的推荐方法,本研究所提出的基于兴趣主题的社会化推荐方法更好地结合了大规模在线教育场景,结合了学习者和资源服务要素,并进一步研究了用户间的内在社会关联,挖掘了用户、学习资源间的隐性联系。实验结果也说明,本研究所提出的方法在准确率上有较好的表现,在教育场景中可以实现更好的推荐效果。
本文是将社会化推荐系统应用于大规模在线学习的一次有益尝试,为大规模在线学习的个性化推荐服务提供了新的视角和思路。本文的不足之处在于主要探讨了学习者的社会关系及其特征,但是对资源之间的语义联系没有进行计算。在下一步研究中,将依据当前的社会关系研究成果,结合资源语义关系,进一步提升推荐的准确度和相关性,以达到更好的推荐效果。
